搭建scala 开发spark程序环境及实例演示
2017-02-16 14:23
411 查看
上一篇博文已经介绍了搭建scala的开发环境,现在进入正题。如何开发我们的第一个spark程序。
下载spark安装包,下载地址http://spark.apache.org/downloads.html(因为开发环境需要引用spark的jar包)
我下载的是spark-2.1.0-bin-hadoop2.6.tgz,因为我的scalaIDE版本是scala-SDK-4.5.0-vfinal-2.11-win32.win32.x86_64.zip
最好,IDE版本和spark版本要匹配,否则,开发程序的时候,可能会包引用的jar包错误等等。
new 一个 scala project,然后new 一个 scala object

代码如下:
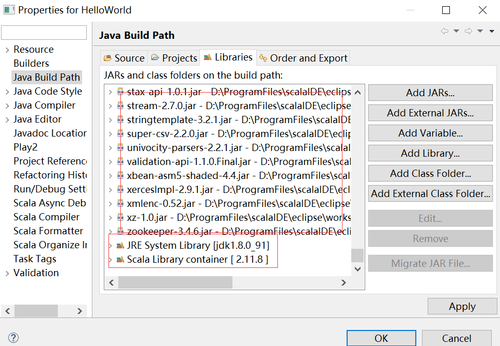
spark的jar包是 spark安装包解压之后jars目录里面的jar包,可以把这个目录下面的所有jar包都引入工程

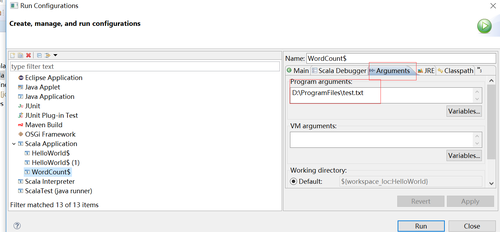
4.run Configurations,配置运行入参,
因为 这个代码是读入一个文本,在hadoop文件系统,可以spark-submit的时候传入这个参数,在windows 本地开发环境可以在eclipse里面配置这个参数,见下面的图
4.入参文本及运行结果
入参文本:

run scala Application运行结果

ok,开发环境搭建完毕。
下载spark安装包,下载地址http://spark.apache.org/downloads.html(因为开发环境需要引用spark的jar包)
我下载的是spark-2.1.0-bin-hadoop2.6.tgz,因为我的scalaIDE版本是scala-SDK-4.5.0-vfinal-2.11-win32.win32.x86_64.zip
最好,IDE版本和spark版本要匹配,否则,开发程序的时候,可能会包引用的jar包错误等等。
new 一个 scala project,然后new 一个 scala object
代码如下:
package com.test
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
/**
* 统计字符出现次数
*/
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
}
val conf = new SparkConf();//创建SparkConf对象
conf.setAppName("Wow,My First Spark Programe");//设置应用程序的名称,在程序运行的监
conf.setMaster("local")//此时,程序在本地运行,不需要安装Spark集群
val sc = new SparkContext(conf);//创建SparkContext对象,通过传入SparkConf实例
// val lines = sc.textFile(args(0));
val lines = sc.textFile(args(0));
val words = lines.flatMap{line => line.split(" ")};//对每一行的字符串进行单词拆
val pairs = words.map{word => (word,1)};
val wordCounts = pairs.reduceByKey(_+_);//对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
// val wordCounts = pairs.reduce((x,y)=>(x.));
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + " : " +wordNumberPair));
// line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)
sc.stop()
}
}3.配置JDK1.8 和引入spark jar包spark的jar包是 spark安装包解压之后jars目录里面的jar包,可以把这个目录下面的所有jar包都引入工程
4.run Configurations,配置运行入参,
因为 这个代码是读入一个文本,在hadoop文件系统,可以spark-submit的时候传入这个参数,在windows 本地开发环境可以在eclipse里面配置这个参数,见下面的图
val lines = sc.textFile(args(0));
4.入参文本及运行结果
入参文本:
run scala Application运行结果
ok,开发环境搭建完毕。

相关文章推荐
- 【Windows】【Scala + Spark】【Eclipse】单机开发环境搭建 - 及示例程序
- 分别用Eclipse和IDEA搭建Scala+Spark开发环境
- [1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
- 转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
- 0070 IntelliJ IDEA+Scala+Hadoop +Spark的开发环境搭建
- 学习大数据的第一步-搭建Scala开发环境,以及使用Intellij IDEA开发Scala程序
- Spark开发环境搭建之使用Scala和maven的pom文件
- 学习大数据的第一步-搭建Scala开发环境,以及使用Intellij IDEA开发Scala程序
- Spark-Scala-IntelliJ开发环境搭建和编译Jar包流程
- windows本地sparkstreaming开发环境搭建及简单实例
- spark 之 Scala 环境搭建,开发工具使用
- 利用Intellij IDEA构建Spark开发环境(包括scala环境的搭建)
- 基于linux的spark与scala开发环境搭建
- Spark程序开发-环境搭建-程序编写-Debug调试-项目提交
- Spark程序开发-环境搭建-程序编写-Debug调试-项目提交
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
- Spark学习: Spark-Scala-IntelliJ开发环境搭建和编译Jar包流程
- spark开发环境搭建intellij+Scala+sbt
- Idea基于scala语言构建spark开发环境搭建