Sentiment Classification with User and Product information
2017-02-14 11:56
441 查看
这两天又看了2篇和文本情感分类相关的论文,使用的基础模型还是深度学习中在情感分析中比较常见的CNN和RNN架构。但是不同的是,这些算法模型在做情感分类的时候凭借的依据不仅仅是单条的文本信息,还考虑了发这条文本的用户特征以及所评论的物品特征。从理论上讲,这是一种引入了额外的信息去帮助情感分析的手段,貌似这是一个比较靠谱的方向。下面就分别的来介绍一下这些模型策略。
首先参考的论文是《Learning Semantic Representations of Users and Products for Document Level Sentiment Classification》 2015 ACL。他应该是第一次把用户和商品信息用于帮助情感分类。首先他讲了这样做的依据,主要是下面这四个方面:1 user-sentiment consistency(不同用户打分标准不一样,有的用户习惯打高分,有的用户习惯打低分);2 product-sentiment consistency (由于商品的质量不同,因此商品的质量直接决定了它的整体打分档次) ;3 user-text consistency (还是每个用户在评价一些商品的时候,用的同一个形容词会表达出不同的情感强度。比方说有的用户说不错,可能代表一般般的意思,而有的用户说不错就是代表很好的意思);4 product-text consistency (用户在评价不同类别商品的时候会倾向于使用不同种类的形容词)。那么这篇论文的作者,根据这四个特性建模如下:
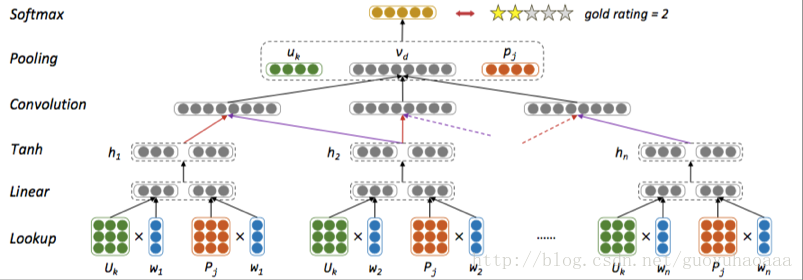
它使用的整体模型是基于CNN的,只不过在整体模型的输入和输出部分进行了稍微的变换。图中最下方的绿色矩阵Uk<
4000
span style="display: inline-block; width: 0px; height: 2.392em;">和Pj代表了用户k和商品j的user-text consistency与product-text consistency 特性。也就是把原来的词向量w1通过转换生成另一个词向量,这个词向量的意义表达更加的准确。在模型的最上面为了考虑user-sentiment consistency与product-sentiment consistency特征,把最后的句向量与向量uk和pj进行拼接。整体的思路还是很直观的。
接下来要讲的模型参考了论文《Neural Sentiment Classification with User and Product Attention》2016 EMNLP 。他的主体模型使用的是LSTM,同时他的预测是基于文档的级别的,故使用了两层次的LSTM,第一层次从词向量生成句向量,第二层次从句向量生成文档向量。这两个层次用的方法是相似的,故这里只讲第一层次,以避免赘述。整体模型如下:
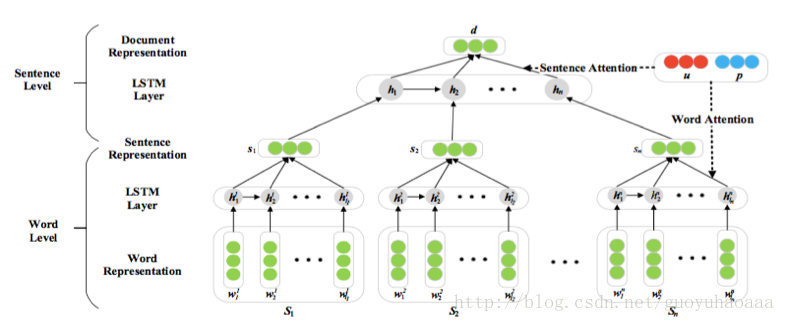
由图中可以看出来,在word level阶段,他的句向量是由LSTM所有时刻的hidden state加权得到的。而这个权值根据不同的用户和商品变化,体现了attention的思想。具体计算公式为:αj=exp(score(hj,U,P))∑lk=1exp(score(hk,U,P)) 其中score(hi,U,P)=Vtanh(WHhi+WUU+WPP+b) 其中从公式上讲并不复杂,V、WH、WP、WU都是需要训练的参数,使用梯度下降算法训练就可以了。但是我好奇的是标注用户的向量u和标注商品的向量p,貌似在论文里没有提到如何正确的初始化,如果是随机初始化的话那么感觉在训练数据有限的情况下就提升有限,也许未来可以探索一种无监督的初始化方法,类似pre-training思想。
上面两种模型在使用的时候都需要知道一句话的用户是谁以及对哪个商品进行了评价,在标注数据的时候就比较麻烦了,需要重新自己标注数据集,而他们用的数据集就是第一篇论文中的作者自己构建的,这是比较消耗人力的。一定要有为科研献身的精神才行啊!!
首先参考的论文是《Learning Semantic Representations of Users and Products for Document Level Sentiment Classification》 2015 ACL。他应该是第一次把用户和商品信息用于帮助情感分类。首先他讲了这样做的依据,主要是下面这四个方面:1 user-sentiment consistency(不同用户打分标准不一样,有的用户习惯打高分,有的用户习惯打低分);2 product-sentiment consistency (由于商品的质量不同,因此商品的质量直接决定了它的整体打分档次) ;3 user-text consistency (还是每个用户在评价一些商品的时候,用的同一个形容词会表达出不同的情感强度。比方说有的用户说不错,可能代表一般般的意思,而有的用户说不错就是代表很好的意思);4 product-text consistency (用户在评价不同类别商品的时候会倾向于使用不同种类的形容词)。那么这篇论文的作者,根据这四个特性建模如下:
它使用的整体模型是基于CNN的,只不过在整体模型的输入和输出部分进行了稍微的变换。图中最下方的绿色矩阵Uk<
4000
span style="display: inline-block; width: 0px; height: 2.392em;">和Pj代表了用户k和商品j的user-text consistency与product-text consistency 特性。也就是把原来的词向量w1通过转换生成另一个词向量,这个词向量的意义表达更加的准确。在模型的最上面为了考虑user-sentiment consistency与product-sentiment consistency特征,把最后的句向量与向量uk和pj进行拼接。整体的思路还是很直观的。
接下来要讲的模型参考了论文《Neural Sentiment Classification with User and Product Attention》2016 EMNLP 。他的主体模型使用的是LSTM,同时他的预测是基于文档的级别的,故使用了两层次的LSTM,第一层次从词向量生成句向量,第二层次从句向量生成文档向量。这两个层次用的方法是相似的,故这里只讲第一层次,以避免赘述。整体模型如下:
由图中可以看出来,在word level阶段,他的句向量是由LSTM所有时刻的hidden state加权得到的。而这个权值根据不同的用户和商品变化,体现了attention的思想。具体计算公式为:αj=exp(score(hj,U,P))∑lk=1exp(score(hk,U,P)) 其中score(hi,U,P)=Vtanh(WHhi+WUU+WPP+b) 其中从公式上讲并不复杂,V、WH、WP、WU都是需要训练的参数,使用梯度下降算法训练就可以了。但是我好奇的是标注用户的向量u和标注商品的向量p,貌似在论文里没有提到如何正确的初始化,如果是随机初始化的话那么感觉在训练数据有限的情况下就提升有限,也许未来可以探索一种无监督的初始化方法,类似pre-training思想。
上面两种模型在使用的时候都需要知道一句话的用户是谁以及对哪个商品进行了评价,在标注数据的时候就比较麻烦了,需要重新自己标注数据集,而他们用的数据集就是第一篇论文中的作者自己构建的,这是比较消耗人力的。一定要有为科研献身的精神才行啊!!

相关文章推荐
- 论文阅读 - 《Neural Sentiment Classification with User and Product Attention》
- The password supplied with the username Domain\UserName was not correct. Verify that it was entered correctly and try again
- LR场景运行提示:This Vuser already started a transaction with the same name, and has not yet processed the
- 图书推荐——Image Analysis, Classification, and Change Detection in Remote Sensing With Algorithms
- 论文笔记 A Large Contextual Dataset for Classification,Detection and Counting of Cars with Deep Learning
- Image Analysis, Classification, and Change Detection in Remote Sensing: With Algorithms for ENVI/IDL, Second Edition
- MS SQL错误:SQL Server failed with error code 0xc0000000 to spawn a thread to process a new login or connection. Check the SQL Server error log and the Windows event logs for information about possible related problems
- Knockout is a JavaScript library that helps you to create rich, responsive display and editor user interfaces with a clean underlying data model.
- LR场景运行提示:This Vuser already started a transaction with the same name, and has not yet processed the
- 论文《Aspect Level Sentiment Classification with Deep Memory Network》总结
- Allow user to scroll and maintain position with "Scroll To Bottom of the Div" example
- Building Applications with Force.com and VisualForce (DEV401) (四):Building Your user Interface
- Coping With Labor Scarcity in Information Technology: Strategies and Practices for Effective Recruit
- Aspect Level Sentiment Classification with Deep Memory Network笔记
- target情感分类(1,0,-1)——Target-dependent sentiment classification with long short term memory
- [React] Animate your user interface in React with styled-components and "keyframes"
- More 3D Graphics (rgl) for Classification with Local Logistic Regression and Kernel Density Estimates (from The Elements of Statistical Learning)(转)
- NAACL 2013 Paper Mining User Relations from Online Discussions using Sentiment Analysis and PMF
- Defend Your Apps and Critical User Info with Defensive Coding Techniques
- Storing User Information with ASP.NET 2.0 Profiles