搭建Spark的maven本地windows开发环境以及测试
2017-02-07 19:51
926 查看
在看完下面的细节之后,就会发现,spark的开发,只需要hdfs加上带有scala的IDEA环境即可。
当run运行程序时,很快就可以运行结束。
为了可以看4040界面,需要将程序加上暂定程序,然后再去4040上看程序的执行。
一:通过maven命令行命令创建一个最初步的scala开发环境
1.打开cmd
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.ibeifeng.bigdata.spark.app -DartifactId=logs-analyzer -Dversion=1.0
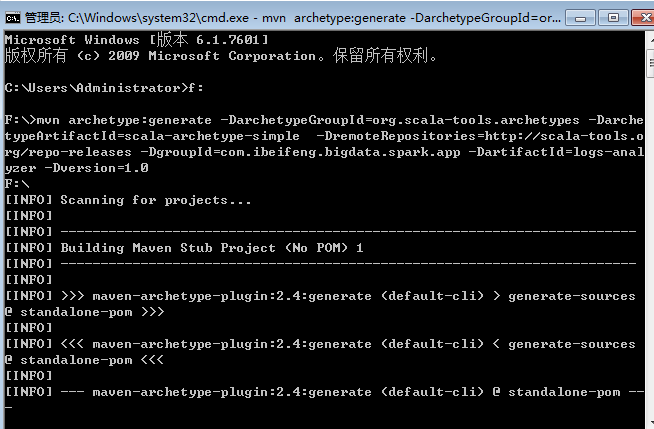
2.等待创建
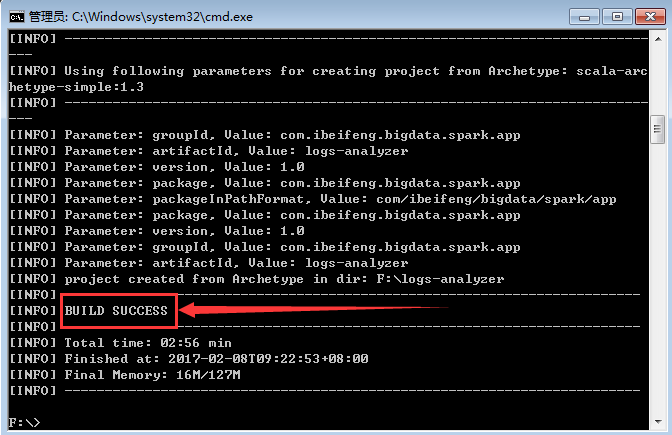
3.生成的项目在F盘
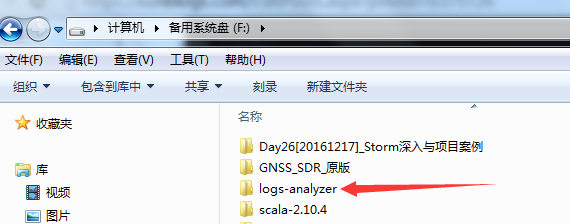
4.使用open导入
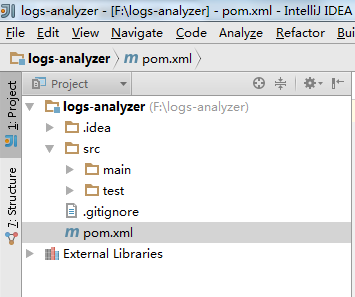
5.在pom.xml中添加dependency
HDFS ,Spark core ,Spark SQL ,Spark Streaming
6.完成

7.在resources中拷贝配置文件
8.新建core包
9.新建类
10.启动hdfs
因为需要hdfs上的文件。
11.书写程序
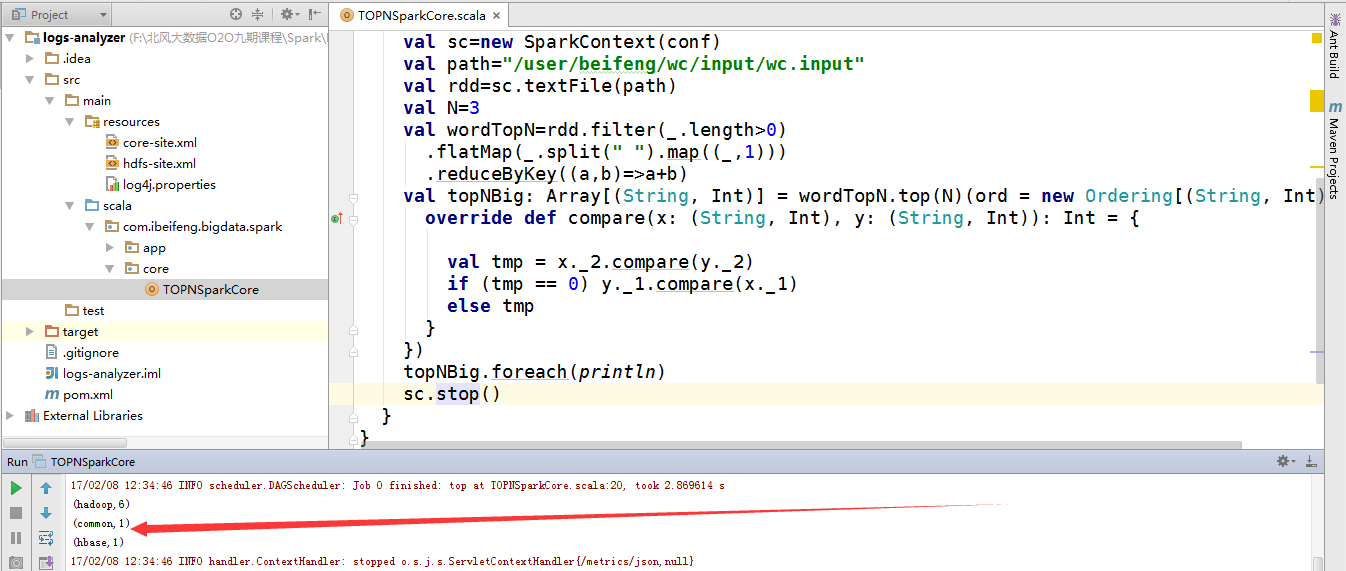
12.直接运行的结果
因为是local模式,所以不需要启动关于spark的服务。
又因为hdfs的服务已经启动。
所以,直接运行run即可。
二:注意的问题
1.path问题
程序中的path默认是hdfs路径。
当然,可以使用windows本地文件,例如在D盘下有abc.txt文件,这时候path="file:///D:/abc.txt"
当run运行程序时,很快就可以运行结束。
为了可以看4040界面,需要将程序加上暂定程序,然后再去4040上看程序的执行。
一:通过maven命令行命令创建一个最初步的scala开发环境
1.打开cmd
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.ibeifeng.bigdata.spark.app -DartifactId=logs-analyzer -Dversion=1.0
2.等待创建
3.生成的项目在F盘
4.使用open导入
5.在pom.xml中添加dependency
HDFS ,Spark core ,Spark SQL ,Spark Streaming
6.完成
7.在resources中拷贝配置文件
8.新建core包
9.新建类
10.启动hdfs
因为需要hdfs上的文件。
11.书写程序
package com.ibeifeng.bigdata.spark.core
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Administrator on 2017/2/8.
*/
object TOPNSparkCore {
def main(args: Array[String]) {
val conf=new SparkConf()
.setMaster("local[*]")
.setAppName("top3");
val sc=new SparkContext(conf)
val path="/user/beifeng/wc/input/wc.input"
val rdd=sc.textFile(path)
val N=3
val wordTopN=rdd.filter(_.length>0)
.flatMap(_.split(" ").map((_,1)))
.reduceByKey((a,b)=>a+b)
val topNBig: Array[(String, Int)] = wordTopN.top(N)(ord = new Ordering[(String, Int)]() {
override def compare(x: (String, Int), y: (String, Int)): Int = {
val tmp = x._2.compare(y._2)
if (tmp == 0) y._1.compare(x._1)
else tmp
}
})
topNBig.foreach(println)
sc.stop()
}
}12.直接运行的结果
因为是local模式,所以不需要启动关于spark的服务。
又因为hdfs的服务已经启动。
所以,直接运行run即可。
二:注意的问题
1.path问题
程序中的path默认是hdfs路径。
当然,可以使用windows本地文件,例如在D盘下有abc.txt文件,这时候path="file:///D:/abc.txt"

相关文章推荐
- [1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
- Windows 搭建jdk、Tomcat、eclipse以及SVN、maven插件开发环境
- Windows环境下新浪SAE本地开发环境搭建及简单测试
- Spark Streaming 实战(1)搭建kafka+zookeeper+spark streaming 的windows本地开发环境
- windows本地sparkstreaming开发环境搭建及简单实例
- Spark2.2,IDEA,Maven开发环境搭建附测试
- [置顶] 安装Idea(集成scala)以及在windows上配置spark(hadoop依赖)本地开发环境
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
- 转】[1.0.2] 详解基于maven管理-scala开发的spark项目开发环境的搭建与测试
- eclipse+maven搭建hadoop本地开发环境
- spark的windows开发环境搭建
- Windows搭建本地Lua开发环境
- Openfire和Spark本地开发环境搭建记要
- Windows下搭建go语言开发环境 以及 开发IDE (附下载链接)
- 新手学Android之在windows下搭建Android开发环境以及HelloWorld
- Windows 8(64位)如何搭建 Android 开发环境与真机测试(转)
- Windows下搭建PHP开发环境 (经过测试可以用)
- 系出名门Android(1) - 在 Windows 下搭建 Android 开发环境,以及 Hello World 程序
- golang的windows本地开发环境搭建