TensorFlow + CUDA 开发环境配置的坑与丘
2017-02-04 14:55
309 查看
作者:沈晟
链接:https://zhuanlan.zhihu.com/p/23042536
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
GPU计算能力的快速发展,让海量矩阵乘法运算更容易被实现,终于也让多年积累下来的神经网络研究与机器学习成果得以喷发。TensorFlow的出现,更让「旧时王谢堂前燕,飞入寻常百姓家」。甚至组合一些家用发烧的设备,就可以开始像模像样的进行深度学习训练。AI for Everybody 的时代开始了。
这里整理了一下部署TensorFlow开发环境的心得,希望对同好有所帮助。
Titan X,或者双路Titan X,或者四路都是常见的选择。

下载Local版,更方便出现故障时重新安装。
CUDA Toolkit本身包括了显卡驱动,所以可以不用另外重复安装。
同时需要根据指示安装 cudnn
官方下载:https://developer.nvidia.com/cuda-downloads
、https://developer.nvidia.com/cudnn
参考编译命令
在运行 ./configure 时,会提示一个叫做 「Cuda compute capabilities」的参数。这时一定要记得到 https://developer.nvidia.com/cuda-gpus 查询下自己显卡的 「compute capability」,例如 Titan X 就应该是61,而不是很多文档或默认提到的52。
安装后,在使用TensorFlow之前,还必须需要配置两个环境变量。
也可以放到 /etc/environment 中固化到系统中,方便后续开发。
安装文档:https://www.tensorflow.org/versions/master/get_started/os_setup.html#optional-install-cuda-gpus-on-linux
、 https://www.tensorflow.org/versions/r0.11/how_tos/using_gpu/index.html
注意:不要在 tensorflow 所在的目录下运行本代码
观察输出的日志是否显示了 gpu0 , gpu1 等,即可确认TensorFlow是否已经利用到CUDA。例如
例如启动 TensorFlow 官方镜像。官方镜像会运行一个 jupyter 可以通过 http://<ip>:<8888>/ 来访问,进入交互式的 Python 笔记本。
推荐参考:GitHub - NVIDIA/nvidia-docker: Build and run Docker containers leveraging NVIDIA GPUs
、
tensorflow/Dockerfile.gpu at master · tensorflow/tensorflow · GitHub
链接:https://zhuanlan.zhihu.com/p/23042536
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
GPU计算能力的快速发展,让海量矩阵乘法运算更容易被实现,终于也让多年积累下来的神经网络研究与机器学习成果得以喷发。TensorFlow的出现,更让「旧时王谢堂前燕,飞入寻常百姓家」。甚至组合一些家用发烧的设备,就可以开始像模像样的进行深度学习训练。AI for Everybody 的时代开始了。
这里整理了一下部署TensorFlow开发环境的心得,希望对同好有所帮助。
硬件
只有英伟达nvidia的显卡支持CUDA和有效帮助TensorFlow。Titan X,或者双路Titan X,或者四路都是常见的选择。
系统环境
目前社区推荐 Ubuntu 14.04 作为。这也是因为 TensorFlow 还是基于 Python 2。而更高版本的 Ubuntu 16 默认的是 Python 3。安装驱动
显卡驱动务必去官方下载最新的Local版(.run file)驱动和CUDA Toolkit。这是因为无论是 apt-get 或 官网的网络安装方式,都不能保证最新版的驱动。下载Local版,更方便出现故障时重新安装。
CUDA Toolkit本身包括了显卡驱动,所以可以不用另外重复安装。
同时需要根据指示安装 cudnn
官方下载:https://developer.nvidia.com/cuda-downloads
、https://developer.nvidia.com/cudnn
安装TensorFlow
只有自行编译的TensorFlow才能利用CUDA。参考编译命令
bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
在运行 ./configure 时,会提示一个叫做 「Cuda compute capabilities」的参数。这时一定要记得到 https://developer.nvidia.com/cuda-gpus 查询下自己显卡的 「compute capability」,例如 Titan X 就应该是61,而不是很多文档或默认提到的52。
# ./configure 过程中留心下面的问题,否则可能浪费大量计算性能 Please specify a list of comma-separated Cuda compute capabilities you want to build with
安装后,在使用TensorFlow之前,还必须需要配置两个环境变量。
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64" export CUDA_HOME=/usr/local/cuda
也可以放到 /etc/environment 中固化到系统中,方便后续开发。
LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64" CUDA_HOME=/usr/local/cuda
安装文档:https://www.tensorflow.org/versions/master/get_started/os_setup.html#optional-install-cuda-gpus-on-linux
、 https://www.tensorflow.org/versions/r0.11/how_tos/using_gpu/index.html
测试
最合适测试CUDA的代码是使用 log_device_placement 参数:# python import tensorflow as tf a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') c = tf.matmul(a, b) sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) print sess.run(c)
注意:不要在 tensorflow 所在的目录下运行本代码
观察输出的日志是否显示了 gpu0 , gpu1 等,即可确认TensorFlow是否已经利用到CUDA。例如
I tensorflow/core/common_runtime/gpu/gpu_device.cc:951] Found device 0 with properties: name: TITAN X (Pascal) ...... I tensorflow/core/common_runtime/direct_session.cc:252] Device mapping: /job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: TITAN X (Pascal), pci bus id: 0000:02:00.0 /job:localhost/replica:0/task:0/gpu:1 -> device: 1, name: TITAN X (Pascal), pci bus id: 0000:01:00.0
范例项目
推荐前往:GitHub - jtoy/awesome-tensorflow: TensorFlow检测 GPU 的使用率
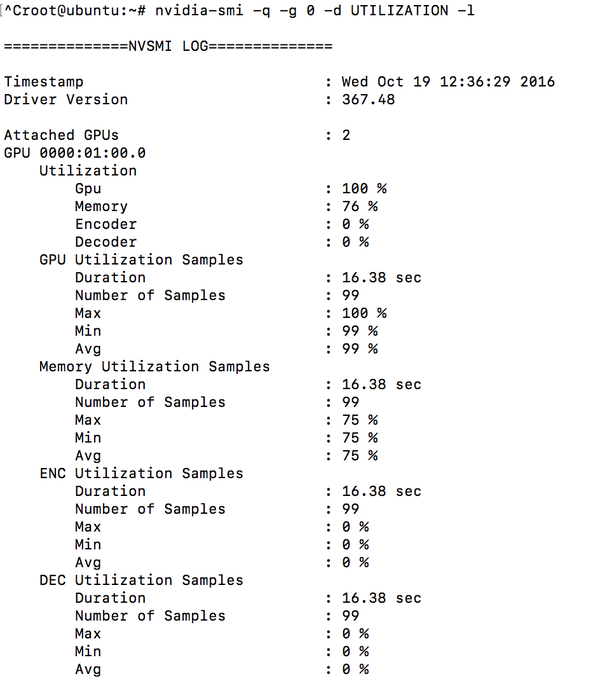
想查看 GPU 的 top 怎么办? 怎么知道 GPU 有没有被充分利用起来。 nVidia 提供了监控 GPU 的工具 「nvidia-smi」,GPU使用率,显存使用率都一目了然。nvidia-smi -q -g 0 -d UTILIZATION -l
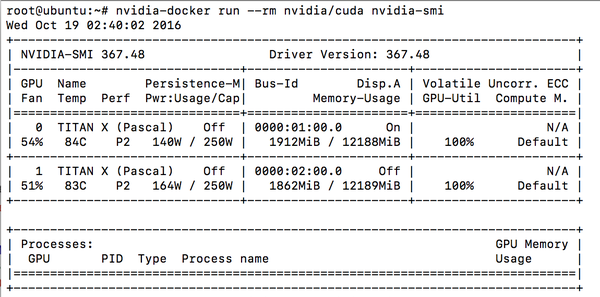
让你的 Docker 容器支持GPU
容器的好处很多。英伟达在这个领域也做了一件大好事,就是提供了让 Docker 也能支持GPU计算的plugin(或者说mod?)。这样可以让项目之间更好的与系统环境隔离,方便管理。换句话说,开发环境的操作系统中只要有 nvidia-docker 即可,而不用安装 TensorFlow 。而每个项目如果有各自不同的版本依赖,也不会在同一个操作系统中产生冲突。例如启动 TensorFlow 官方镜像。官方镜像会运行一个 jupyter 可以通过 http://<ip>:<8888>/ 来访问,进入交互式的 Python 笔记本。
nvidia-docker run -it -p 8888:8888 tensorflow/tensorflow:0.11.0rc0-gpu
推荐参考:GitHub - NVIDIA/nvidia-docker: Build and run Docker containers leveraging NVIDIA GPUs
、
tensorflow/Dockerfile.gpu at master · tensorflow/tensorflow · GitHub

相关文章推荐
- Windows 10 +Anaconda+tensorflow+cuda8.0 环境配置
- N卡双显卡电脑装ubuntu15.04并配置Anaconda+Tensorflow+cuda+cuDNN的深度学习环境
- ubuntu16.04+cuda8.0+pycharm+tensorflow环境配置
- tensorflow+cuda+linux mint开发环境搭建
- 深度学习环境搭建:linux下 Ubuntu16.04+cuda8.0+cudnn+anaconda+tensorflow并配置远程访问jupyter notebook
- 深度学习环境搭建:linux下 Ubuntu16.04+cuda8.0+cudnn+anaconda+tensorflow并配置远程访问jupyter notebook
- 深度学习主机环境配置: Ubuntu16.04 + GeForce GTX 1070 + CUDA8.0 + cuDNN5.1 + TensorFlow
- 在U盘里配置好主流深度学习框架及GPU环境theano\tensorflow\keras\caffe\cuda7.5
- 【并行计算-CUDA开发】Windows下opencl环境配置
- CUDA开发环境配置大全
- CUDA开发环境配置大全
- CUDA开发环境配置大全
- VS2005开发CUDA3.2环境配置
- CentOS下配置CUDA开发环境
- Linux_Ubuntu16的安装与CUDA7.5开发环境搭建及Nvidia-OpenACC开发工具配置 笔记本-台式机均可
- CUDA学习日志:开发环境配置和学习资源
- CUDA与PyCUDA开发环境配置详情
- RedHat(rhel5.5_x86-client)下配置CUDA开发环境
- 配置RoR开发环境 (安装git和gitflow)
- Win7环境下的CUDA开发环境配置