YDB针对范围查找所做的性能小改进(skiplist IO 分析)
2017-01-30 14:57
316 查看
范围查找,尤其是时间范围的查找,在日常检索中会被经常使用,在范围查找中跳跃表的利用与否对性能影响非常大。
我们对lucene的默认范围查找做了一个小实验,截获了每种SQL的IO读取明细,对IO情况做了测试与分析。
测试结果如下
amtlong采用的数据类型为tlong类型,已经尽量通过tree的层次结构减少了term的个数,但是没想到,doclist本很成为瓶颈。
doclist用来存储一个term对应的doc id的列表,由于数据量很大,有些term可能达数亿甚至几十亿个。
对于文档数量较少的范围查找,是否使用了跳跃功能对性能影响不大,但是YDB的场景更偏重大数据场景,倒排表对应的skiplist会特别长,如果没有使用跳跃功能就会出现上面那种一个查询耗费几个GB的IO的情况,严重影响查询性能。
我们针对每个IO,打印出详细的函数调用关系,验证我们的推测。
前两种情况均使用了advance。
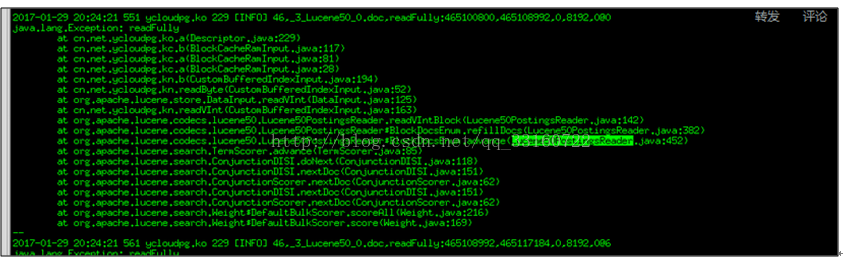
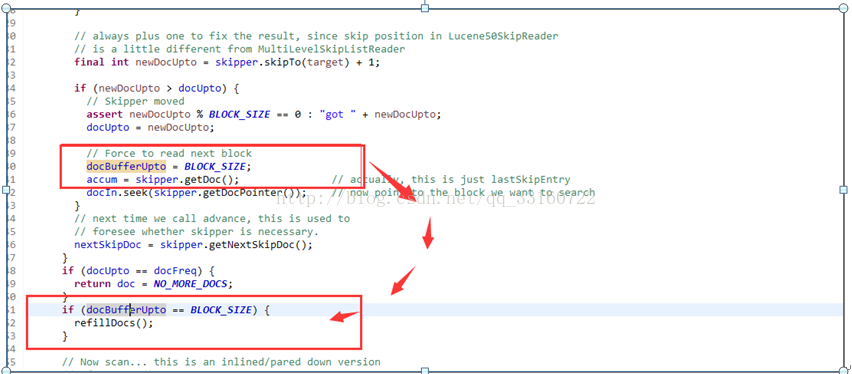
第三种情况没有advance,而是采用了暴力遍历的方式,所以IO特别巨大,我们通过源码分析到了具体原因,超过16个term后,lucene默认就不会继续使用skiplist了。
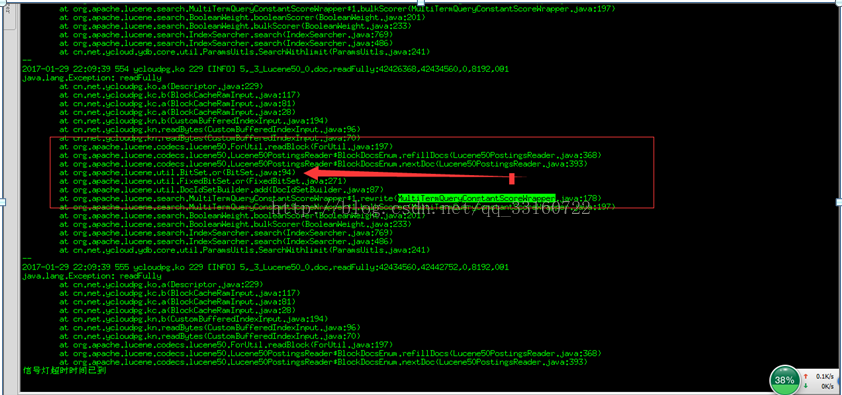
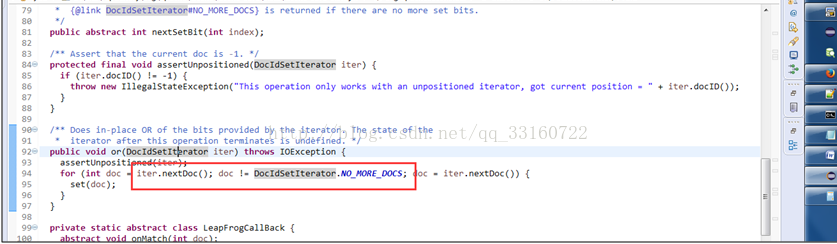

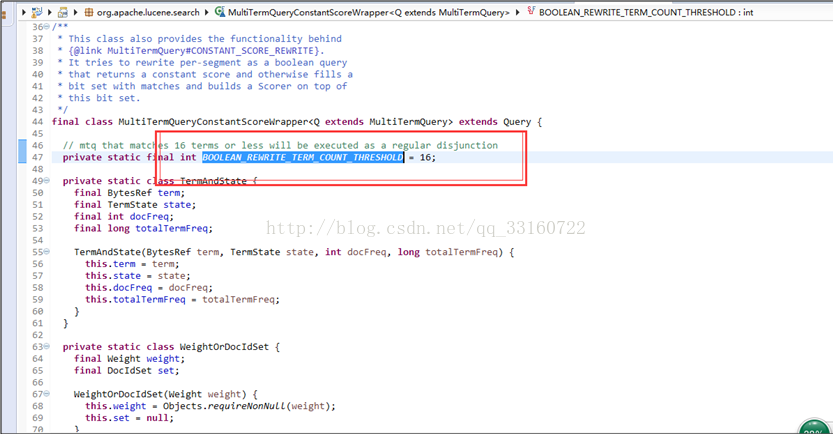
但显然对于海量数据的情况下不适用,因IO巨大导致检索性能很慢,YDB针对范围查找做了如下的变更改动
16个term真的太小太小,我们更改为1024个,针对tlong,tint,tfloat,tdouble类型的数据将会有特别高的扫描性能。
大多时候term对应的skiplist也是有数据倾斜的,尤其是tlong,ting,tfloat,tdouble类型本身的分层特性。对于有数据倾斜的term我们要区别对待,对于skiplist很长的term采用跳跃功能能显著减少IO,对于skiplist很短的term则采用顺序读取,遍历的方式,减少随机读。
我们对lucene的默认范围查找做了一个小实验,截获了每种SQL的IO读取明细,对IO情况做了测试与分析。
测试结果如下
普通的等值SQL分析-占用IO较小
筛选条件为:phonenum='13470881895' and amtdouble=50使用小范围的 term扫描(IO也较小)
筛选条件为:phonenum='13470881895' and amtdouble like '([50 to 50])'使用大范围的term扫描(IO非常大,超出想象)
筛选条件为:phonenum='13470881895' and (amtdouble>='50' or amtdouble<='50')amtlong采用的数据类型为tlong类型,已经尽量通过tree的层次结构减少了term的个数,但是没想到,doclist本很成为瓶颈。
doclist用来存储一个term对应的doc id的列表,由于数据量很大,有些term可能达数亿甚至几十亿个。
问题分析
我们在上述查找中,都限定了手机号码,理论上,只要利用了skiplist的跳跃功能(lucene中对应advance方法),IO会很小,但是明显第三种测试的IO超出了我们的预期。对于文档数量较少的范围查找,是否使用了跳跃功能对性能影响不大,但是YDB的场景更偏重大数据场景,倒排表对应的skiplist会特别长,如果没有使用跳跃功能就会出现上面那种一个查询耗费几个GB的IO的情况,严重影响查询性能。
我们针对每个IO,打印出详细的函数调用关系,验证我们的推测。
前两种情况均使用了advance。
第三种情况没有advance,而是采用了暴力遍历的方式,所以IO特别巨大,我们通过源码分析到了具体原因,超过16个term后,lucene默认就不会继续使用skiplist了。
如何解决?
lucene这样优化是有明显的原因的,即当term数量特别多的时候,跳跃的功能会带来更多的随机读,相反性能会更差。但显然对于海量数据的情况下不适用,因IO巨大导致检索性能很慢,YDB针对范围查找做了如下的变更改动
16个term真的太小太小,我们更改为1024个,针对tlong,tint,tfloat,tdouble类型的数据将会有特别高的扫描性能。
大多时候term对应的skiplist也是有数据倾斜的,尤其是tlong,ting,tfloat,tdouble类型本身的分层特性。对于有数据倾斜的term我们要区别对待,对于skiplist很长的term采用跳跃功能能显著减少IO,对于skiplist很短的term则采用顺序读取,遍历的方式,减少随机读。

相关文章推荐
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- YDB针对范围查找所做的性能小改进(skiplist IO 分析)
- 磁盘阵列与普通硬盘IO性能分析
- Skip List(跳表) 分析
- SUSE LINUX下磁盘IO性能监测分析
- leveldb源代码分析4:SkipList