pyinstaller的库导入和多进程打包问题
2017-01-19 11:46
218 查看
以前使用py2exe进行打包,那也仅限于windows。后来由于工作原因需要在Linux上进行打包操作,那么就不能使用py2exe工具了,后来选择了pyinstaller。
在实际应用中,pyinstaller打包的效率和操作性很好,个人觉得比py2exe更加智能,但是也是有一些问题。
开发环境:Windows 7 + python3.4
一、import导入的问题
pyinstaller是很智能的,只要指定了入口py文件,那么它就会根据代码自动查找需要导入的包。但是隐式导入的话,平常运行是没有问题的,举例:
运行这个ORM库的初始化引擎,是没有问题的,在console得到结果:
this is my test
那么我们开始打包,使用最简单的pyinstaller test1.py。打包完成后,在当前目录下有个dist文件夹,进入dist下的test1文件夹,然后打开cmd,运行这个exe,我们就会发现:
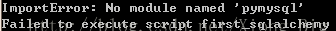
这是怎么回事呢?那么问题来了,sqlalchemy这个库在初始化的时候是不需要显示导入引擎库的,它自己有一个create_engine()的函数来初始化,这个字符串是使用者根据规则来自己填写的。其实解决的方法很简单,我们只要在显式导入pymysql这个库即可。现在我们导入这个库:
重新打包一遍(重新打包的时候记得删除掉spec文件,否则会有缓存,或者是加上--clean选项清除掉),再次运行:

现在就没有这个问题了。
二、多进程打包的问题
官方的CPython存在一个GIL锁,这个锁的存在有很多优点,很多库都是线程安全的,单线程执行的效率也高。在python早期的一个版本中取消掉了GIL,代之以高粒度的锁来实现多线程,但是实际应用中单个线程的效率大大降低。故后来又将GIL这个锁还原回去,所以至今的python2也好还是python3中都会有这个锁。但是这个锁有很大一个问题,那就是效率问题,它导致了python仅仅只能利用一个core来进行数据的计算。所以后面为了弥补这个GIL带来的问题,专家们设计了multiprocessing库,gevent库等。前一个是多进程库,为了解决python用于数据密集型处理的情况;后一个用于异步IO处理的情况,基本原理就是在CPU时钟之间来回切换,简单的例子就是爬虫程序爬取网页的时候。假如有10个url,我们都要去GET它,实际上网络之间的延迟是大大高于计算机内部的,那么这个时间内计算机就切换到下一个。
有时候运用多进程是必须的,这个替代不了,哪怕它占用资源很多。
废话不多说了,实际操作中,存在多进程使用的时候,本身像Debug这种模式来运行python代码是没有问题的:
I am foo1
I am foo2
I am foo3
主进程已经跑完了
现在我们使用pyinstaller来打一个包,然后运行这个可执行文件:
……
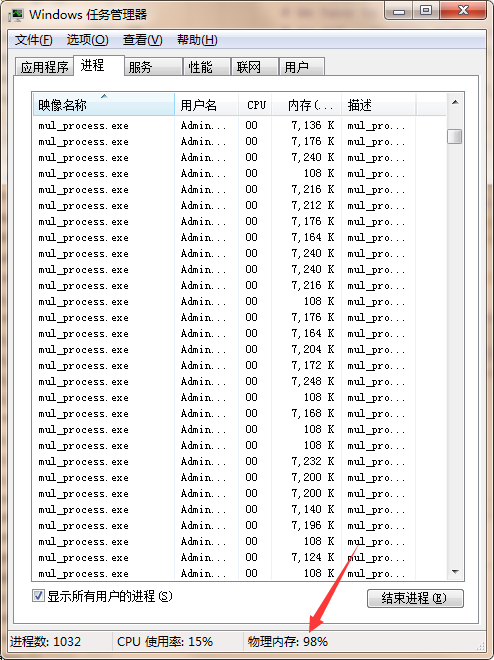
等一会之后,我发现计算机不怎么响应了,而且很卡,打开任务管理器:
赶紧Ctrl + Break结束掉!
这完全不是我们想要的,同时这么多进程在运行,计算机就要挂掉了。
这种情况是很令人费解的,考虑半天无果之后,当然Google了——https://github.com/pyinstaller/pyinstaller/wiki/Recipe-Multiprocessing
GitHub上说得很清楚了,不再赘述。
现在我们新建一个模块,暂且就叫mul_process_package.py,添加代码:
先运行测试一遍,发现没有问题,那么删掉以前的spec文件,再次打包。运行结果如下:

这两个问题就算解决了。
结语:python的一个强大之处在于众多开源库的存在,在GitHub上的python开源项目也越来越多。python拥有众多的优点,当然也有众多的缺点,现在还没有一款语言能达到既有C++般的效率又有python这般简洁的语法。鱼与熊掌不可兼得,常人是“一”字型人才,也有“|”字型人才,我们的目标当然是“十”字型人才。多学、多用与多动手,一切问题迎刃而解。
在实际应用中,pyinstaller打包的效率和操作性很好,个人觉得比py2exe更加智能,但是也是有一些问题。
开发环境:Windows 7 + python3.4
一、import导入的问题
pyinstaller是很智能的,只要指定了入口py文件,那么它就会根据代码自动查找需要导入的包。但是隐式导入的话,平常运行是没有问题的,举例:
# test1.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
DB_CONNECT_STRING = 'mysql+pymysql://root:123456@localhost/study'
engine = create_engine(DB_CONNECT_STRING, echo = False)
DB_Session = sessionmaker(bind = engine)
session = DB_Session()
print('this is my test')运行这个ORM库的初始化引擎,是没有问题的,在console得到结果:
this is my test
那么我们开始打包,使用最简单的pyinstaller test1.py。打包完成后,在当前目录下有个dist文件夹,进入dist下的test1文件夹,然后打开cmd,运行这个exe,我们就会发现:
这是怎么回事呢?那么问题来了,sqlalchemy这个库在初始化的时候是不需要显示导入引擎库的,它自己有一个create_engine()的函数来初始化,这个字符串是使用者根据规则来自己填写的。其实解决的方法很简单,我们只要在显式导入pymysql这个库即可。现在我们导入这个库:
import pymysql
重新打包一遍(重新打包的时候记得删除掉spec文件,否则会有缓存,或者是加上--clean选项清除掉),再次运行:
现在就没有这个问题了。
二、多进程打包的问题
官方的CPython存在一个GIL锁,这个锁的存在有很多优点,很多库都是线程安全的,单线程执行的效率也高。在python早期的一个版本中取消掉了GIL,代之以高粒度的锁来实现多线程,但是实际应用中单个线程的效率大大降低。故后来又将GIL这个锁还原回去,所以至今的python2也好还是python3中都会有这个锁。但是这个锁有很大一个问题,那就是效率问题,它导致了python仅仅只能利用一个core来进行数据的计算。所以后面为了弥补这个GIL带来的问题,专家们设计了multiprocessing库,gevent库等。前一个是多进程库,为了解决python用于数据密集型处理的情况;后一个用于异步IO处理的情况,基本原理就是在CPU时钟之间来回切换,简单的例子就是爬虫程序爬取网页的时候。假如有10个url,我们都要去GET它,实际上网络之间的延迟是大大高于计算机内部的,那么这个时间内计算机就切换到下一个。
有时候运用多进程是必须的,这个替代不了,哪怕它占用资源很多。
废话不多说了,实际操作中,存在多进程使用的时候,本身像Debug这种模式来运行python代码是没有问题的:
# mul_process.py
from multiprocessing import Process
def foo1():
print('I am foo1')
def foo2():
print('I am foo2')
def foo3():
print('I am foo3')
if __name__ == '__main__':
a = Process(target = foo1)
b = Process(target = foo2)
c = Process(target = foo3)
a.start()
b.start()
c.start()
a.join()
b.join()
c.join()
print('主进程已经跑完了')运行这段代码,是没有问题的:I am foo1
I am foo2
I am foo3
主进程已经跑完了
现在我们使用pyinstaller来打一个包,然后运行这个可执行文件:
……
等一会之后,我发现计算机不怎么响应了,而且很卡,打开任务管理器:
赶紧Ctrl + Break结束掉!
这完全不是我们想要的,同时这么多进程在运行,计算机就要挂掉了。
这种情况是很令人费解的,考虑半天无果之后,当然Google了——https://github.com/pyinstaller/pyinstaller/wiki/Recipe-Multiprocessing
GitHub上说得很清楚了,不再赘述。
现在我们新建一个模块,暂且就叫mul_process_package.py,添加代码:
import os
import sys
import multiprocessing
# Module multiprocessing is organized differently in Python 3.4+
try:
# Python 3.4+
if sys.platform.startswith('win'):
import multiprocessing.popen_spawn_win32 as forking
else:
import multiprocessing.popen_fork as forking
except ImportError:
import multiprocessing.forking as forking
if sys.platform.startswith('win'):
# First define a modified version of Popen.
class _Popen(forking.Popen):
def __init__(self, *args, **kw):
if hasattr(sys, 'frozen'):
# We have to set original _MEIPASS2 value from sys._MEIPASS
# to get --onefile mode working.
os.putenv('_MEIPASS2', sys._MEIPASS)
try:
super(_Popen, self).__init__(*args, **kw)
finally:
if hasattr(sys, 'frozen'):
# On some platforms (e.g. AIX) 'os.unsetenv()' is not
# available. In those cases we cannot delete the variable
# but only set it to the empty string. The bootloader
# can handle this case.
if hasattr(os, 'unsetenv'):
os.unsetenv('_MEIPASS2')
else:
os.putenv('_MEIPASS2', '')
# Second override 'Popen' class with our modified version.
forking.Popen = _Popen然后在mul_process.py中加入:import mul_process_package然后在if __name__ == '__main__':下面加入:
multiprocessing.freeze_support()
先运行测试一遍,发现没有问题,那么删掉以前的spec文件,再次打包。运行结果如下:
这两个问题就算解决了。
结语:python的一个强大之处在于众多开源库的存在,在GitHub上的python开源项目也越来越多。python拥有众多的优点,当然也有众多的缺点,现在还没有一款语言能达到既有C++般的效率又有python这般简洁的语法。鱼与熊掌不可兼得,常人是“一”字型人才,也有“|”字型人才,我们的目标当然是“十”字型人才。多学、多用与多动手,一切问题迎刃而解。

相关文章推荐
- pyinstaller的库导入和多进程打包问题
- Python 3.6 使用 pyinstaller 打包exe文件遇到的问题
- Myeclipse导入Spring源码后少jar包问题--使用Jar命令重新打包
- 一、问题 MyEclipse怎么导出可运行的jar包。 二、测试环境 MyEclipse V8.6 三、操作过程 1、java项目没有导入第三方jar包的情况 这时候打包就比较简单: ①首先在MyE
- pyinstaller打包pyqt4程序时在部分电脑上无法显示jpg图像的问题
- 导入Excel时,Excel进程excel.exe不能自动结束的问题
- 在vue中的js部分导入图片后通过webpack无法被正确打包的问题
- Pygame使用pyinstaller打包exe以及停止工作问题
- 通过Pyinstaller打包Pygame库写的小游戏程序容易出现的问题解决方法
- pyinstaller打包exe---requests模块打包后无法运行问题记录
- wxPython和pyOpenGL在用PyInstaller打包时遇到的若干问题及解决办法
- pyinstaller打包apscheduler问题的解决方法
- Python调用不在同一个文件夹下的Python程序,并且如何解决pyinstaller打包路径问题
- pyinstaller 打包Python程序(APScheduler,mysql)遇到的问题
- pyinstaller打包pyqt5问题解决
- pyinstaller打包问题,关于skleran
- Pygame使用pyinstaller打包exe无法运行问题
- 解决pyinstaller打包exe文件出现命令窗口一闪而过的问题
- pyinstaller打包pyqt5常见问题解决办法
- idea maven 打包报错问题,不是maven注入而是用的本地idea导入jar的方式