第九篇:使用 AdaBoost 元算法提高分类器性能
2017-01-19 10:08
260 查看
前言
有人认为 AdaBoost 是最好的监督学习的方式。某种程度上因为它是元算法,也就是说它会是几种分类器的组合。这就好比对于一个问题能够咨询多个 "专家" 的意见了。
组合的方式有多种,可能是不同分类算法的分类器,可能是同一算法在不同设置下的集成,还可以是数据集在不同部分分配给不同分类器之后的集成等等。
本文将给出的 AdaBoost 分类器实现基于第二种 (另外几种实现在此基础上稍作改动即可)。
一种原始的元算法 - bagging (自举汇聚法)
这个算法的意思有点像投票系统,其思路步骤大致如下:1. 将数据按照一定的规则划分成 N 份,每份的大小和原数据集一样大 (因此里面肯定是有重复数据的)。
2. 将这 N 份数据集分发到多个分类器中。
3. 按照 "少数服从多数" 原则,从这 N 个分类器的分类结果中总结出最优结果。
boost (提高任意给定学习算法精确度算法) vs bagging (自举汇聚法)
boost 和 bagging 一个很大的不同是它会给那些分错的样本更高关注度(权重)。AdaBoost 是一种最为典型的 boost 元算法。因此理论上它能在相对较少的迭代次数下得到更为精确的分类结果。
AdaBoost 元算法的基本原理
AdaBoost 的强大之处,在于它能够集成多个弱分类器,形成一个强分类器。所谓弱分类器就是分类错误率大于五成的分类器,比随机分类还渣。(但是它的分类算法是确定的,这点和随机分类器不同。显然你无法通过集成随机分类器得到什么有价值的东西)
其具体步骤大致如下:
1. 对每个样本给定一个权重 d。
2. 基于权重向量 D 调用一次弱分类器并得出这次统计的分类器权重值 alpha (注意是分类器权重值,区别于上一步的权重d)
3. 基于分类器权重值 alpha 更新各个样本的权重向量
4. 循环 2 - 3 直到错误率为 0 或者循环到了指定的次数
5. 1-4 为训练部分算法,训练好了之后,便可带入样本进行分类。分类的方法是依次带入训练集中的各个分类器中求出分类结果,然后各部分结果乘以其对应的分类器权重值 alpha 再累加求和。
下图可用来帮助理解 (直方图中的矩形长度表示样本权重,三角形中的值表示分类器权重值 alpha):
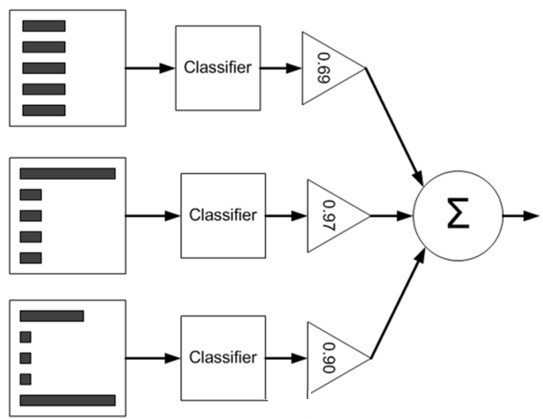
基于单层决策树的 AdaBoost 元算法分类器实现
首先,准备好单层决策树的数据结构。在本文的 AdaBoost 实现中,元算法中的分类器组合模式是 "同一算法在不同设置下的集成",那么不同设置不同在哪里?
不同就不同在每次构建单层决策树都是选择划分正确率最高的划分方式。
因此在构建单层决策树函数中,必须有一个择优过程,具体可以参考下面的实现代码。
函数的功能应当是返回一个单层决策树信息结构(仅仅是划分信息就可以了不用数据)。
同时,函数应该返回一个错误信息值,这个错误值是和权重向量D相关的,用于计算分类器权重值 alpha。(当然也可以在该函数内部实现该字段)
最后,分类结果自然也要返回。
单层决策树代码实现如下:
#==========================================
# 输入:
# dataMatrix: 输入数据
# dimen: 划分特征下标
# threshVal: 划分阈值
# threshIneq: 划分方向(是左1右0分类还是左0右1分类)
# 输出:
# retArray: 分类结果
#==========================================
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
'按照指定方式分类并返回结果'
retArray = numpy.ones((numpy.shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
#==========================================
# 输入:
# dataArr: 输入数据
# classLabels: 分类标签集
# D: 权重向量
# 输出:
# bestStump: 决策树信息
# minError: 带权错误(用于生成分类器权重值 alpha)
# bestClasEst: 分类结果
#==========================================
def buildStump(dataArr,classLabels,D):
'创建单层最佳决策树'
dataMatrix = numpy.mat(dataArr);
labelMat = numpy.mat(classLabels).T
m,n = numpy.shape(dataMatrix)
# 特征值阈值步长
numSteps = 10.0;
# 当前最佳决策树信息集
bestStump = {};
# 分类结果
bestClasEst = numpy.mat(numpy.zeros((m,1)))
# 最小带权错误初始化为无穷大
minError = numpy.inf
for i in range(n): # 遍历所有的特征选取最佳划分特征
rangeMin = dataMatrix[:,i].min();
rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1): # 遍历所有的特征值选取最佳划分特征值 stepSize为探测步长
for inequal in ['lt', 'gt']: # 对于 左1右0 和 左0右1 两种分类方式
# 当前划分阈值
threshVal = (rangeMin + float(j) * stepSize)
# 分类
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
# 统计分类错误信息
errArr = numpy.mat(numpy.ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr
# 更新最佳决策树的信息
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst在单层决策树之上,便是 AdaBoost 分类器的实现,下面先给出伪代码:
对每次迭代: 找到最佳单层决策树 将该树加入到最佳决策树数组 计算分类器权重 alpha 更新权重向量 D 更新累计类别估计值 PS: 如果错误率等于0.0,则立马退出循环。
Python 代码实现如下:
#========================================== # 输入: # dataArr: 输入数据 # classLabels: 分类标签集 # numIt: 最大迭代次数 # 输出: # bestStump: 决策树信息 # minError: 带权错误(用于生成分类器权重值 alpha) # bestClasEst: 分类结果 #========================================== def adaBoostTrainDS(dataArr,classLabels,numIt=40): 'AdaBoost 分类器' # 最佳决策树集合 weakClassArr = [] # 样本个数 m = numpy.shape(dataArr)[0] # 权重向量 D = numpy.mat(numpy.ones((m,1))/m) # 各个类别的估计累积值 aggClassEst = numpy.mat(numpy.zeros((m,1))) for i in range(numIt): # 迭代 numIt 次 # 构建最佳决策树 bestStump,error,classEst = buildStump(dataArr,classLabels,D) # 计算该决策树的分类器权重值 alpha alpha = float(0.5*numpy.log((1.0-error)/max(error,1e-16))) bestStump['alpha'] = alpha # 将该决策树加入到决策树数组中去 weakClassArr.append(bestStump) # 更新权重向量 expon = numpy.multiply(-1*alpha*numpy.mat(classLabels).T,classEst) D = numpy.multiply(D,numpy.exp(expon)) D = D/D.sum() # 计算当前的总错误率。如果错误率为0则退出循环。 aggClassEst += alpha*classEst aggErrors = numpy.multiply(numpy.sign(aggClassEst) != numpy.mat(classLabels).T,numpy.ones((m,1))) errorRate = aggErrors.sum()/m print "错误率: ",errorRate if errorRate == 0.0: break return weakClassArr
至此,就可以用 AdaBoost 进行分类了。
首先训练出一个训练集,然后将训练集带入分类函数,如下:
# 获取训练集 classifierArr = adaBoostTrainDS(daaArr, labelArr, 30) # 分类并打印结果 print adaClassify([0,0], classifierArr)
测试结果:

显然,可以看出 AdaBoost 分类器由三个决策树构成。样本最终分类结果为 -1。
小结
本文介绍了分类器中的元算法思想。通过这样的思想,能够将多种分类器组合起来,大大地加强了分类性能。另外据可靠数据分析,较之逻辑回归,AdaBoost 分类器没有过度拟合(overfitting)现象。
Boost算法还有很多种,AdaBoost 只是其中最为经典的实现之一,还有更多高级实习需要在日后学习工作中进行研究。

相关文章推荐
- 使用 AdaBoost 元算法提高分类器性能
- 使用缓存来提高开发性能 - 算法优化
- 利用AdaBoost元算法提高分类器性能
- Socket网络编程学习笔记(6):使用线程池提高性能
- 以编程方式使用批语句节省 数据库 IO 来提高性能
- 使用内存映射文件来提高你程序的性能
- 使用异步 I/O 大大提高应用程序的性能
- 使用Epoll提高网络性能
- 使用异步 I/O 大大提高应用程序的性能
- 使用内存映射文件来提高你程序的性能
- 在视频格式转换中使用MMX和SSE指令集提高性能
- 使用内存映射文件来提高你程序的性能
- 在SQL语句中使用索引提示提高SQL性能
- 使用索引初图来提高性能
- 使用Raid提高SQL的性能和可用性
- 使用查询改写提高查询性能
- 使用标准数据绑定语法代替 DataBinder.Eval 方法以提高性能
- 使用sealed声明密封类(sealed class)如何对于提高性能有帮助
- 使用异步 I/O 大大提高应用程序的性能
- 在PL/SQL中使用Bulk Binds对性能的提高