hive 底层模块实现-distinct
2017-01-18 11:29
351 查看
准备数据
语句SELECT COUNT, COUNT(DISTINCT uid) FROM logs GROUP BY COUNT; hive> SELECT * FROM logs; OK a 苹果 3 a 橙子 3 a 烧鸡 1 b 烧鸡 3 hive> SELECT COUNT, COUNT(DISTINCT uid) FROM logs GROUP BY COUNT;
根据count分组,计算独立用户数。
计算过程

默认设置了hive.map.aggr=true,所以会在mapper端先group by一次,最后再把结果merge起来,为了减少reducer处理的数据量。注意看explain的mode是不一样的。mapper是hash,reducer是mergepartial。如果把hive.map.aggr=false,那将groupby放到reducer才做,他的mode是complete.
Operator
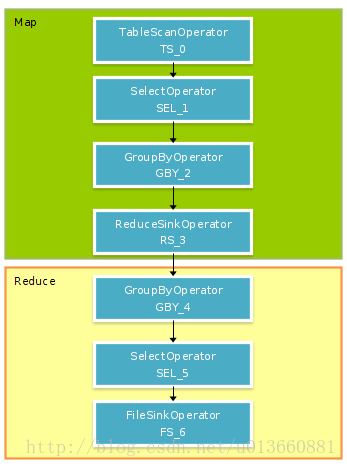
Explain
hive> explain SELECT uid, sum(count) FROM logs group by uid; OK ABSTRACT SYNTAX TREE: (TOK_QUERY (TOK_FROM (TOK_TABREF (TOK_TABNAME logs))) (TOK_INSERT (TOK_DESTINATION (TOK_DIR TOK_TMP_FILE)) (TOK_SELECT (TOK_SELEXPR (TOK_TABLE_OR_COL uid)) (TOK_SELEXPR (TOK_FUNCTION sum (TOK_TABLE_OR_COL count)))) (TOK_GROUPBY (TOK_TABLE_OR_COL uid)))) STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 is a root stage STAGE PLANS: Stage: Stage-1 Map Reduce Alias -> Map Operator Tree: logs TableScan // 扫描表 alias: logs Select Operator //选择字段 expressions: expr: uid type: string expr: count type: int outputColumnNames: uid, count Group By Operator //这里是因为默认设置了hive.map.aggr=true,会在mapper先做一次聚合,减少reduce需要处理的数据 aggregations: expr: sum(count) //聚集函数 bucketGroup: false keys: //键 expr: uid type: string mode: hash //hash方式,processHashAggr() outputColumnNames: _col0, _col1 Reduce Output Operator //输出key,value给reducer key expressions: expr: _col0 type: string sort order: + Map-reduce partition columns: expr: _col0 type: string tag: -1 value expressions: expr: _col1 type: bigint Reduce Operator Tree: Group By Operator aggregations: expr: sum(VALUE._col0) //聚合 bucketGroup: false keys: expr: KEY._col0 type: string mode: mergepartial //合并值 outputColumnNames: _col0, _col1 Select Operator //选择字段 expressions: expr: _col0 type: string expr: _col1 type: bigint outputColumnNames: _col0, _col1 File Output Operator //输出到文件 compressed: false GlobalTableId: 0 table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat Stage: Stage-0 Fetch Operator limit: -1
转载:http://ju.outofmemory.cn/entry/784

相关文章推荐
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-distinct
- hive 底层模块实现-group by
- hive 底层模块实现-join
- hive 底层模块实现-join
- hive 底层模块实现-group by
- hive 底层模块实现-group by
- hive 底层模块实现-group by
- hive 底层模块实现-group by
- hive 底层模块实现-join
- hive 底层模块实现-join