kafka队列模型
2017-01-16 11:10
330 查看

Kafka是一个持久化消息发布订阅系统,常用于消息队列、日志通道等场景。
Kafka的一些名词解释和概述:
| 名词 | 解释 |
|---|---|
| Producer | Kafka通过Producer产生数据push到Kafka服务器中。 |
| topic | Kafka通过topic来对不同类别的队列进行隔离,每个push的消息必须制定属于哪个topic |
| Broker | 每一个Kafka的机器被称为一个Broker。 |
| Cluster | 多个Broker组成一个Kafka集群(Kafka Cluster) |
| Consumer | Kafka中的数据通过Consumer指定不同的offset进行消费 |
| Partition | Kafka支持数据分区,每个topic可以包含多个分区,并将分区分布在不同的服务器上,同时设置其中一个为leader,其余几个通过复制来进行数据副本,保证集群在N-1个挂掉仍然可用 |
| Group | 多个Consumer组成一个Group,用于负载均衡的进行消费 |
Offset
在Kafka中Consumer在消费队列中的数据时候,需要通过指定offset来告诉当前消费的进度。offset不在broker中进行维护,需要在客户端维护。可以设置Offset自动增长或者手动进行commit两种方式。一般会使用手动commit的方式来防止程序异常的时候队列数据没有消费被直接跳过。
Group
多个Consumer组成一个Group的时候,发送到这个Group的数据会分别被Group中的Consumer来进行消费,如果Consumer A消费了这条数据,那么Consumer B就不会受到这条数据。同一个Topic可以同时被不同的Group以订阅的形式进行拉取,他们的offset是相互隔离的。比如我在kafka的Consumer用三个Group来进行拉取分别对应:Hadoop、Storm、log collention等,这样每个Consumer Group都可以接收到相同的数据。
Partition
kafka通过分区的方式来增加吞吐量和处理容灾。每个offset可以存放在不同的分区中,每个partition对应一个文件夹,kafka保证每个Partition中的数据是有序的,每个push到offset的消息,会被有序的追加到Partition的结尾。Kafka中对每个Partition进行主从复制,可以配置为一主多从的方式进行数据副本。同时保证N-1个Broker挂掉的时候数据不丢失。
Consumer在进行消费的时候可以指定Partition进行消费。但是不可以指定多个Consumer消费一个Partition。
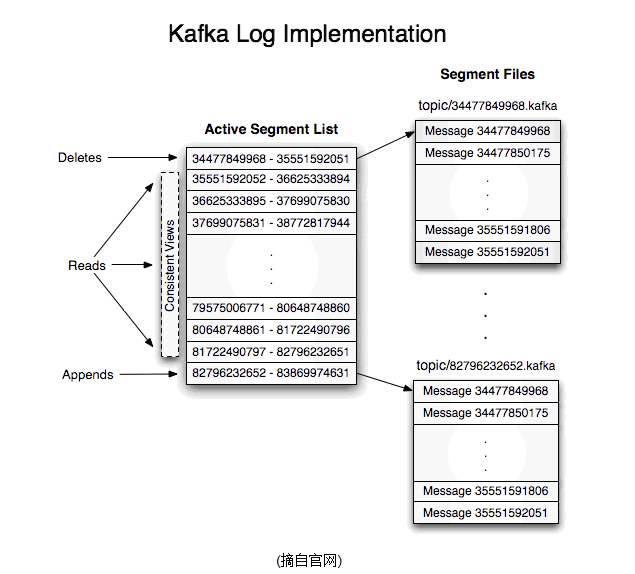
更多:/detail/2622954381.html

相关文章推荐
- Linux系统消息队列框架Kafka单机安装配置
- 分布式消息队列kafka系列介绍 — 基本概念
- storm bolt作为kafka消息队列生产者
- Linux基于单链表&环形队列的多线程生产者消费者模型
- Kafka分布式消息队列(一):基础
- 分布式消息队列Kafka的集群部署
- Kafka源码深度解析-系列1 -消息队列的策略与语义
- kafka消息队列环境搭建
- Kafka源码深度解析-系列1 -消息队列的策略与语义
- 生产者/消费者模型改进版 ——队列
- ELK之消息队列选择redis_kafka_rabbitmq
- 【转】快速理解Kafka分布式消息队列框架
- 学习笔记TF049:TensorFlow 模型存储加载、队列线程、加载数据、自定义操作
- Kafka#2:消息队列
- Android消息队列模型--Thread,Handler,Looper,Massage Queue
- Android消息队列模型
- Python 多线程同步队列模型
- 用生产者消费者模型实现的线程安全环形队列
- 分布式队列编程:模型、实战
- 生产者/消费者模式(阻塞队列) 一个经典的并发模型