Data Structure: All you should know about Hash
2017-01-13 04:21
525 查看
在我们进入正题之前,我们来讲讲Object里面最常用的两个方法和哈希的关系。在Java的定义当中,如果equals方法返回true的两个对象,其hashCode的返回值是需要相等的。默认的实现是,hashCode返回引用指向的对象的内存地址(10进制)。而equals根据两个hashCode返回的内存地址值(10进制)是否相等来判断两个对象是否相等。
另外还有一个比较容易记混的方法叫toString,对于没有重载这个方法的类,它的默认是返回classname @ heximal 的内存地址(与上面的10进制不同)。
而hash table的基本原理是,对于任何的对象,利用hashcode产生一个独一无二的数,再用这个数放进地址压缩算法返回一个index值。下面讨论的是,如何在压缩算法上做文章。
Why do we need hashing?
Assume we store our data in an array, and we want to search for an element. The normal time consume is O(n). Since we need to traversal the array's element one by one.
If we got a sorted array, we can use binary search to improve the performance by cutting it down to O(logn).
However, if we think even bigger, we should try to solve this problem in O(1). It needs us to know the index of element in advance.
What hashing is doing?
1) Convert an object to an integer(index). In java, we use hashCode() method to do this.
2) Use an array to store the data. However, the length of array need to be compressed by using module (%).
Workarounds for Collision
The length of array is compressed; therefore, it is inevitable to have collisions by having two different elements hashed to the same index using the same hash function. If such situation happened, we need some workarounds to handle it.
Open addressing(the address of element is not necessary follow the index value calculated by hash function):
1) Linear Probing (drawback: primary clustering) (python使用)
如果遇到冲突,沿着当前计算的index值,不断以步距为1 的探索范围向后探索,直至查找到free slot可以存储当前element.
Primary cluster:如果有一连串连续的元素已经在array中存在,那么linear probing将会变得十分time consuming. 另外,以下图为例:
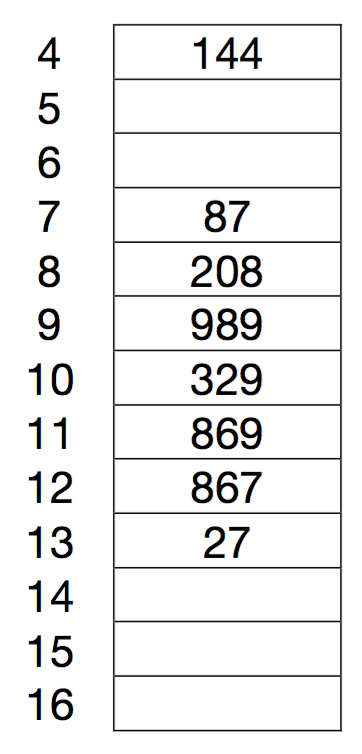
如果第一个冲突发生在87,第二个冲突发生208,那么第一次冲突已经搜索过的occupied的slots又要重新被搜索一次。造成浪费。
2) Quadratic Probing (drawback: second clustering)
如果遇到冲突,则以当前index值+1, +2, +4, +9, +16去探索,直至查找到free slot可以存储当前element.
Second clustering同理。只不过造成浪费的概率稍微小一些。
3) Double hasing (Java 使用)
在遇到冲突时,进行第二次hash来计算step size。怎么理解呢?
让我们来总结下上述的open addressing的方法先。总体而言,linear probing, quadratic probing和double hash其实都可以归结到一个公式当中:

所以double hash的实质是:hi=(h(key)+ih1(key))%m 0≤i≤m-1 //即di=i*h1(key)。
即step的大小由另外一个hash函数决定。
在open addressing的时候,需要考虑load factor的问题。load factor是一项指标: number of occupied slots / length of array.
一般,当load factor > 1/2的时候,linear probing 效率就十分低下。而对于所有的open addressing方法而言,大于2/3时,都需要创建一个新的array, 再rehashing。这一做法类似于ArrayList。所以,hashtable的效率不总是O(1).
Close addressing(the address of element must follow the index value calculated by hash function):
Separate Chaining
这个方法是通过为每个index下设置一个链表。将所有属于这个Index的元素都放在链表中。当元素很多,很容易产生high load factor时,应该使用这种情况。
因为这个不方法不需要考虑load factor的问题。
What makes a Good Hash Function
The first concern of hash function is the input variables.
Whether the input variables are totally random or not:
Random: we can directly use module. (%)
Non-random: like car numbers. Different parts of it can be interpreted differently. In the situation of non-random, we need to take care of these:
1) Never use the non-information numbers. Like checksum of ID. It is just a sum of other information. There is not new information from it.
2) Set the length of hash internal storage array to be prime number. This will be extremely helpful when you are using double hashing as the solution to conflict.
If the length is 15, there will be a chance:
1st hash:
0 -- 5 -- 10 -- 0
2nd hash:
5 -- 10 -- ...
无限循环。
但如果是质数13的话,就能遍
4000
历整个array.
3) Use folding:
Folding is to break keys into groups of digits and adding the groups.
A reasonable rule of breaking groups is break the number into groups that have n-1 digits when the length of array is n digits.
This way, you can distribute the numbers better.
4) If a particular serial of numbers' step size is not 1, then you must shrink to interval to step size of 1.
Like: 100 150 200 250 300 --> 1 2 3 4 5
How Java do with Hash
hashCode() is a function that is listed in the Object class. However, some subclass of Object may override the function.
Like: Integer类就会直接用其value作为hashcode,而String类则是用一下的公式:
s.charAt(0)*31^(n-1) + s.charAt(1)*31^(n-1) + ... + s.charAt(n-1)
Fun facts:
在2004年,Java 1.4以前,Java也是用求余符号来做hash的。但是,求余符号最不好的是计算时间太差。
所以之后直接用按位与来实现hash,此方法十分巧妙:
我们需要把array的长度设置成2^n长,接着把所有的输入变量都转换成2进制后,按位与(n-1),得到的结果就是hashcode. 其实质是dropping the higher bit or signed bit.
注意,使用此方法的前提是,array的长度必须是power of two.
利用当array长度为8,输入变量是86时,1010110 && 0111 = 110 = 6.
所以,在Java的HashMap的源码中,也是要求内部存储结构的长度需要是power of 2。
部分源码(java采用close addressing, separate chain):
另外还有一个比较容易记混的方法叫toString,对于没有重载这个方法的类,它的默认是返回classname @ heximal 的内存地址(与上面的10进制不同)。
而hash table的基本原理是,对于任何的对象,利用hashcode产生一个独一无二的数,再用这个数放进地址压缩算法返回一个index值。下面讨论的是,如何在压缩算法上做文章。
Why do we need hashing?
Assume we store our data in an array, and we want to search for an element. The normal time consume is O(n). Since we need to traversal the array's element one by one.
If we got a sorted array, we can use binary search to improve the performance by cutting it down to O(logn).
However, if we think even bigger, we should try to solve this problem in O(1). It needs us to know the index of element in advance.
What hashing is doing?
1) Convert an object to an integer(index). In java, we use hashCode() method to do this.
2) Use an array to store the data. However, the length of array need to be compressed by using module (%).
Workarounds for Collision
The length of array is compressed; therefore, it is inevitable to have collisions by having two different elements hashed to the same index using the same hash function. If such situation happened, we need some workarounds to handle it.
Open addressing(the address of element is not necessary follow the index value calculated by hash function):
1) Linear Probing (drawback: primary clustering) (python使用)
如果遇到冲突,沿着当前计算的index值,不断以步距为1 的探索范围向后探索,直至查找到free slot可以存储当前element.
Primary cluster:如果有一连串连续的元素已经在array中存在,那么linear probing将会变得十分time consuming. 另外,以下图为例:
如果第一个冲突发生在87,第二个冲突发生208,那么第一次冲突已经搜索过的occupied的slots又要重新被搜索一次。造成浪费。
2) Quadratic Probing (drawback: second clustering)
如果遇到冲突,则以当前index值+1, +2, +4, +9, +16去探索,直至查找到free slot可以存储当前element.
Second clustering同理。只不过造成浪费的概率稍微小一些。
3) Double hasing (Java 使用)
在遇到冲突时,进行第二次hash来计算step size。怎么理解呢?
让我们来总结下上述的open addressing的方法先。总体而言,linear probing, quadratic probing和double hash其实都可以归结到一个公式当中:
所以double hash的实质是:hi=(h(key)+ih1(key))%m 0≤i≤m-1 //即di=i*h1(key)。
即step的大小由另外一个hash函数决定。
在open addressing的时候,需要考虑load factor的问题。load factor是一项指标: number of occupied slots / length of array.
一般,当load factor > 1/2的时候,linear probing 效率就十分低下。而对于所有的open addressing方法而言,大于2/3时,都需要创建一个新的array, 再rehashing。这一做法类似于ArrayList。所以,hashtable的效率不总是O(1).
Close addressing(the address of element must follow the index value calculated by hash function):
Separate Chaining
这个方法是通过为每个index下设置一个链表。将所有属于这个Index的元素都放在链表中。当元素很多,很容易产生high load factor时,应该使用这种情况。
因为这个不方法不需要考虑load factor的问题。
package com.xjieli.datastrc;
interface HashTableInterface{
boolean search(int key);
int delete(int key);
void insert(int key);
}
public class HashTableSimple implements HashTableInterface{
private static final DataItem DELETED = new DataItem(-1);
//internal data storage
private DataItem[] hashArray;
public HashTableSimple(int initialCapacity){
hashArray = new DataItem[initialCapacity];
}
private static class DataItem{
private int key;
public DataItem (int k){
this.key = k;
}
}
//implement methods here
private int hashFunc(int key){
return key % hashArray.length;
}
@Override
public boolean search(int key){
int hash_val = hashFunc(key);
while(hashArray[hash_val] != null){
if(hashArray[hash_val].key == key){
return true;
}
hash_val++;//linear probing
//because hash table never get full,
//we do not need to worry about dead loop
hash_val = hash_val % (hashArray.length);//control the range
}
return false;
}
@Override
public int delete(int key){
int hash_val = hashFunc(key);
int return_val = 0;// used for return
while(hashArray[hash_val] != null){
if(hashArray[hash_val].key == key){
return_val = hashArray[hash_val].key;
//这里应该用特殊的类型DELETED,用来控制re-hash的
hashArray[hash_val] = DELETED;
return return_val;
}
hash_val++;
hash_val = hash_val % (hashArray.length);
}
return -1;
}
@Override
public void insert(int key){
DataItem item = new DataItem(key);
int hash_val = hashFunc(key);
while(hashArray[hash_val] != null &&
hashArray[hash_val] != DELETED){
hash_val++;
hash_val = hash_val % (hashArray.length);
}
hashArray[hash_val] = item;
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}What makes a Good Hash Function
The first concern of hash function is the input variables.
Whether the input variables are totally random or not:
Random: we can directly use module. (%)
Non-random: like car numbers. Different parts of it can be interpreted differently. In the situation of non-random, we need to take care of these:
1) Never use the non-information numbers. Like checksum of ID. It is just a sum of other information. There is not new information from it.
2) Set the length of hash internal storage array to be prime number. This will be extremely helpful when you are using double hashing as the solution to conflict.
If the length is 15, there will be a chance:
1st hash:
0 -- 5 -- 10 -- 0
2nd hash:
5 -- 10 -- ...
无限循环。
但如果是质数13的话,就能遍
4000
历整个array.
3) Use folding:
Folding is to break keys into groups of digits and adding the groups.
A reasonable rule of breaking groups is break the number into groups that have n-1 digits when the length of array is n digits.
This way, you can distribute the numbers better.
4) If a particular serial of numbers' step size is not 1, then you must shrink to interval to step size of 1.
Like: 100 150 200 250 300 --> 1 2 3 4 5
How Java do with Hash
hashCode() is a function that is listed in the Object class. However, some subclass of Object may override the function.
Like: Integer类就会直接用其value作为hashcode,而String类则是用一下的公式:
s.charAt(0)*31^(n-1) + s.charAt(1)*31^(n-1) + ... + s.charAt(n-1)
Fun facts:
在2004年,Java 1.4以前,Java也是用求余符号来做hash的。但是,求余符号最不好的是计算时间太差。
所以之后直接用按位与来实现hash,此方法十分巧妙:
我们需要把array的长度设置成2^n长,接着把所有的输入变量都转换成2进制后,按位与(n-1),得到的结果就是hashcode. 其实质是dropping the higher bit or signed bit.
注意,使用此方法的前提是,array的长度必须是power of two.
利用当array长度为8,输入变量是86时,1010110 && 0111 = 110 = 6.
所以,在Java的HashMap的源码中,也是要求内部存储结构的长度需要是power of 2。
部分源码(java采用close addressing, separate chain):
package com.xjieli.datastrc;
public class HashTable<K,V> {
Entry<K,V>[] table;
public HashTable(){
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
static class Entry<K,V>{
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n){
value = v;
next = n;
key = k;
hash = h;
}
}
public V put(K key, V value){
if(key == null){
return null;
}
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for(Entry<K,V> e = table[i]; e != null; e = e.next){
//看看是否需要update,不是linear probing
Object k;
//if the hash are the same --> same object, then need to be updated
if(e.hash == hash && ((k = e.key) == key || key.equals(k))){
V old_value = e.value;
e.value = value;
e.recordAccess(this);
return old_value;
}
}
modCount++;//记录修改次数
addEntry(hash, key, value, i);
return null;//如果不是更新,就返回null
}
static int indexFor(int h, int length){
return h & (length - 1);
}
void addEntry(int hash, K key, V value, int bucket_index){// separate chain
Entry<K,V> e= table[bucket_index];
table[bucket_index] = new Entry<K,V>(hash, key, value, e);
if(size++ >= threshold){
resize(2*table.length);
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
}
}

相关文章推荐
- Data Structure: All you should know about Hash
- Data Structure: All you should know about Hash
- Data Structure: All you should know about Hash
- Data Structure: All you should know about Hash
- Data Structure: All you should know about Hash
- Data Structure: All you should know about Hash
- All you should know about NUMA in VMware!
- 10 boot time parameters you should know about the Linux kernel
- You should know this about T & F & Y!
- A Unix Utility You Should Know About: Pipe Viewer
- 6 Things You Should Know About Fragment URLs
- A Unix Utility You Should Know About: Netcat
- Task cancellation in C# and things you should know about it
- What are all the common undefined behaviour that a C++ programmer should know about?
- 10 Things You Should Know About Using a BlackBerry!
- A Unix Utility You Should Know About: Pipe Viewer
- Node.js modules you should know about: request
- A Unix Utility You Should Know About: lsof
- You should know this about google(plus)
- 5 Things You Should Know About the New Maxwell GPU Architecture