S3 服务(Simple Storage Service简单存储服务) 简介(与hdfs同一级)
2017-01-11 15:56
162 查看
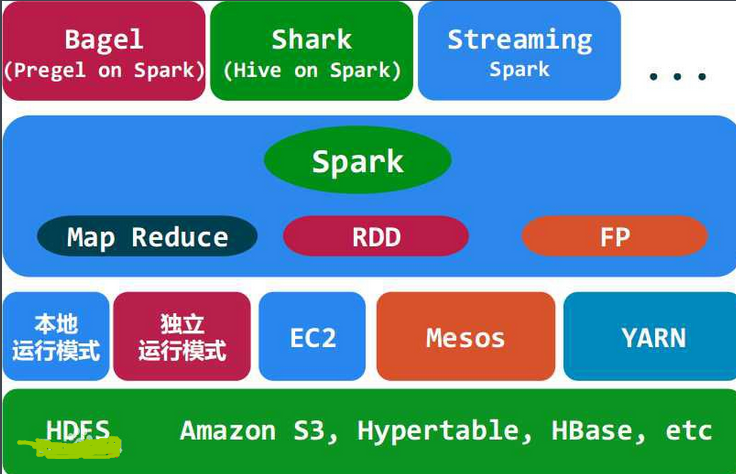
图1 spark 相关
亚马逊云存储之S3(Simple Storage Service简单存储服务)
(转 )
S3是Simple Storage Service的缩写,即简单存储服务。亚马逊的名词缩写也都遵循这个习惯,例如Elastic Compute Cloud缩写为EC2等等。其他组织类似的命名有W3C,如果我们也follow这个习惯则IEEE会被写为IE3,CCTV就是C2TV,好像有点罗嗦了。
S3说的玄乎一点可以叫云存储,通俗一点就是大网盘。其概念类似于分布式文家系统,同Google的GFS应该在一个层面。
S3的定义如下
Amazon S3 is a web service that enables you to store data in the cloud. You can then download the data or use the data with other AWS services, such as Amazon Elastic Cloud Computer (EC2).
看来除了做网盘只用,S3存储的数据还可以被其他的亚马逊高层服务直接引用,这一点比国内的简单的网盘提供商高不少,亚马逊大网盘是其整体Solution中的有机组成部分。
基本概念
1。bucket – 类比于文件系统的目录
A bucket is a Container for objects stored in Amazon S3. Every object is contained in a bucket. For example, if the object named photos/puppy.jpg is stored in the johnsmith bucket, then it is addressable using the URL http://johnsmith.s3.amazonaws.com/photos/puppy.jpg
似乎目录不能嵌套,也就是不能有子目录,官方的说法是起到namespace的作用,是访问控制的基本单位,其实丫还是个目录。
2。Object – 类比文件系统的文件
对象中带有对象名名,对象属性,对象本身最大5G,其实也还是个文件。
目前object有Versioning的属性(即对象不同历史版本的cache概念),这个是文件系统不具备的,在早期看到的S3资料中没有这一概念,应该是演进的结果,其面对的应该是有版本控制的需求的用户。
3。Keys – 类比文件名
key的样式也是URL,记住亚马逊的服务都是使用Web Service或REST方式访问的。
例如,http://doc.s3.amazonaws.com/2006-03-01/AmazonS3.wsdl
其中‘doc’就是目录名(桶名),”2006-03-01/AmazonS3.wsdl”是文件名(对象名)。
如果引入了version则bucket + key + version唯一标示一个版本的文件。
4。Versioning – 类比CVS中的一个版本
下面是一些实现原理的描述。
<图片缺失...>
同名文件的写入,并不覆盖已有文件而是增加了一个最新的文件版本。
同样下面的删除也不真正删除,而是mark了删除标记。
<图片缺失...>
当最新版本mark为deleted之后,对该对象的get操作返回404错误,除非明确指定一个历史版本。
当然也可以指定版本永久删除其中一个拷贝。
5。Regions – 文件存储的地理位置
这个也是文件系统中不存在的,就是不同的地理区域,用户可以指定将文件存在某个国家的服务器。我个人认为,这不是一个很好的概念,作为云的提供商,应该对于应用屏蔽这些部署细节。工程实现同技术理想还是有差距。目前其可以指定的server位置有美国、爱尔兰、新加坡等地。
接口API
常用的API就是读、写、增、删、改、查等等。使用标准的SOAP和REST定义。
尤其一提的是对于对象的获取,除了用http直接按照C/S方式获取之外,亚马逊支持BT协议,也就是说提供种子。从用户角度想,亚马逊会 charge更少的钱,但同时亚马逊自身也会减负。bt下载的速度就不太稳定了,基本取决于种子“质量”也就是取决于对文件感兴趣的人的多寡。例如命名为 “XX门”估计文件下载能够快很多。
数据有什么用
当数据上传到aws云之后,可以很多服务可以使用例如。
Amazon ElasticCompute Cloud
Amazon Elastic MapReduce
Amazon Import/Export等。
一点遗憾
没有看到如何实现分布式文件系统的资料,这是了解其Scale以及可靠性等的关键,或许亚马逊没有google大方,没有提供类似GFS之类的底层机制实现文档。
参考
http://aws.amazon.com/s3/#functionality
http://docs.amazonwebservices.com/AmazonS3/2006-03-01/
http://developer.amazonwebservices.com/connect/forum.jspa?forumID=24
http://www.kernelchina.org/content/%E4%BA%9A%E9%A9%AC%E9%80%8A%E4%BA%91%E5%AD%98%E5%82%A8%E4%B9%8Bs3simple-storage-service%E7%AE%80%E5%8D%95%E5%AD%98%E5%82%A8%E6%9C%8D%E5%8A%A1
三个理由告诉你对象存储替换HDFS还不错
原因一:对象存储可提供更好的数据保护 虽然HDFS能够利用内部的服务器级存储,它实际上是按照其标准的数据保护策略将所有数据做了三个副本。因此,尽管可以使用较便宜的服务器内部的硬盘驱动器,它可能并不像最初希望的那样经济,因为容量需求要乘以3。一种替代方案是使用基于对象的存储系统,提供亚马逊简单存储服务(S3)协议访问,这是Hadoop除了HDFS也同样支持的。这些系统可以是纯软件,因此可以使用商用服务器和服务器级存储。但不同于默认的HDFS,许多对象存储系统都提供纠删编码。这种数据保护机制类似于RAID但粒度更细,可以在对象或子对象的层面操作,把数据和奇偶校验位分布到存储集群的各个节点上。其结果是,可以达到相似或更高水平的数据冗余性,而只需大约25%至30%的额外开销。相比之下, HDFS的标准三副本配置下的额外容量开销为200%。
原因二:HDFS会暴露主节点
HDFS具有一个主节点和一系列从节点。从节点处理数据并将结果发送给主节点。主节点还需要维护数据复制策略以及基本的集群管理。如果主节点发生故障,集群的其余节点将不能被访问。 HDFS对主节点只提供了有限的保护,所以企业需要采取特殊措施来实现主节点的高可用性。
如上所述,在对象存储系统中,主节点与从节点都能受到相同的纠删编码的数据保护。此外,由主节点维护的管理Hadoop集群所需的所有元数据(metadata)都可以存储在集中化的对象存储系统中。这样当主节点发生故障时,从节点或备用节点可以迅速变成为主节点。
原因三:HDFS不能进行单独扩展
像任何其他架构一样,Hadoop对计算和存储容量也会有不同程度的需求。问题是,HDFS要求计算能力和存储容量需要按比例进行扩展,这意味着你不能单独对某一种资源进行扩充。
要说明这一点最常见的方式是当一个Hadoop架构的存储容量用尽时,因为增加更多容量就意味着加入另一个装满硬盘的节点,这也增加了更多的计算能力。反之亦如此,作为Hadoop基础设施,往往需要更多的处理能力,但存储空间却很充裕。大多数时候,当购置了一个新的服务器以增加计算能力时,它也带来了新的存储空间。其结果是,Hadoop架构总是在某种资源上浪费金钱,而对另一种资源却总是缺乏。
对象存储允许容量和计算能力各自独立地进行扩展。计算节点可以是1U或2U的机箱,通过固态存储引导。对象存储系统可以装满高容量驱动器,从而保持每GB成本最低。更重要的是,随着应用环境的变化,每一层都可以独立扩展。
HDFS之于Hadoop的主要优点是低成本和高性能,这得益于数据存放于本地。而利用商业存储硬件的对象存储系统同样可以提供类似的低成本,尤其是当采用纠删编码来提高数据保护效率时更是如此。10 GbE的高速网络现在已经很实惠,这些都使HDFS将数据和计算放在一起所带来的性能优势不复存在。对象存储提供了一种更具成本效益,更可靠,而且性能至少跟HDFS相当的基础架构,它理所当然应该成为一种可行的HDFS替代解决方案。

相关文章推荐
- S3服务(Simple Storage Service简单存储服务)简介
- WindowsAzure存储服务(StorageService)简介
- 用 Amazon Web Services 进行云计算,第 2 部分: 用 Amazon Simple Storage Service (S3) 在云中存储数据
- 用 Amazon Web Services 进行云计算,第 2 部分: 用 Amazon Simple Storage Service (S3) 在云中存储数据
- Amazon Web Services S3 (Simple Storage Service)
- HTTPSQS(HTTP Simple Queue Service)是一款基于 HTTP GET/POST 协议的轻量级开源简单消息队列服务
- Windows Azure Storage (3) Windows Azure Storage Service存储服务之Blob详解(中)
- Windows Azure Storage (1) Windows Azure Storage Service存储服务
- Amazon Simple Storage Service(Amazon S3)
- Amazon Simple Storage Service (Amazon S3)
- openstack安装(liberty)--安装块存储服务(Block Storage service/cinder)
- Windows Azure Storage (2) Windows Azure Storage Service存储服务之Blob详解(上)
- 利用AWS简单存储服务(S3)托管网站
- Windows Azure Platform (九) Windows Azure Storage Service存储服务
- SSDP——Simple Service Discovery Protocol——简单服务发现协议
- Windows Azure Storage (4) Windows Azure Storage Service存储服务之Blob Share Access Signature
- 试用Amazon S3(Simple Storage Service)云储存服务
- Amazon Simple Storage Service (Amazon S3)
- Amazon Simple Storage Service(S3)
- 独立存储 – 比你想的更简单 Isolated Storage – Might Be Easier Than You Think [by Jesse Liberty]