Python爬虫学习笔记-网页topN条目爬取
2017-01-10 08:56
471 查看
背景
爬取某网页TopN条目数据过程
安装chrome驱动
注意,在安装过程中对于chrome驱动是有对应的版本要求的,否则运行时报错,比如下面的例子:chrome的版本号:
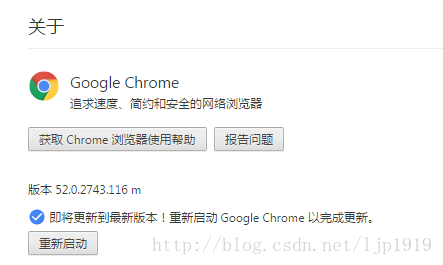
而安装chrome的驱动后,并将其目录添加到系统path之后,运行报错如下:
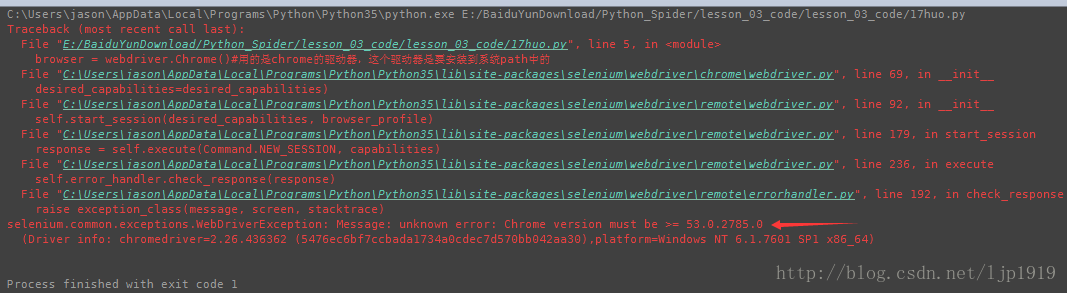
从中可以看出,该错误是由于chrome的版本问题导致的。
根据网页页面上面的元素的位置,右键-检查可以查看对应的属性和值:

选择需要爬取的数据项,比如商品名,价格等等信息:

获取每件商品的名字:

代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
browser = webdriver.Chrome()#用的是chrome的驱动器,这个驱动器是要安装到系统path中的。如果是无头浏览器的话,PhantomJS,则不会真实起一个浏览器
browser.set_page_load_timeout(30)#网页的等待超时
#有多少页商品
browser.get('http://www.17huo.com/search.html?sq=2&keyword=%E5%A4%A7%E8%A1%A3')
page_info = browser.find_element_by_css_selector('body > div.wrap > div.pagem.product_list_pager > div')
#body > div.wrap > div.pagem.product_list_pager > div,这个字符串是网页页面下,右键-检查-copy-copy selector
# print(page_info.text)
pages = int((page_info.text.split(',')[0]).split(' ')[1])#商品的页数,48页
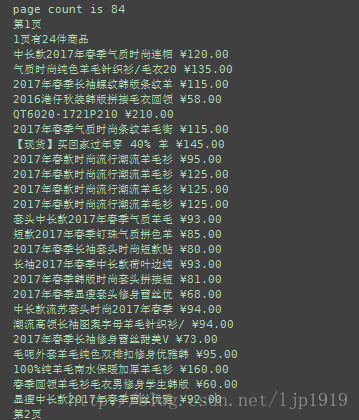
print("page count is %s" %pages)
#根据商品的页数进行遍历,此时通过点击网页上的第二页可以看出,对应的url是原来基础上增加一个page=2,依次类推
for page in range(pages):
if page > 2:#只是抓取前3页
break
print('第%d页' % (page + 1))
url = 'http://www.17huo.com/?mod=search&sq=2&keyword=%E7%BE%8A%E6%AF%9B&page=' + str(page + 1)
browser.get(url)#打开该页
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")#发送js指令,模拟网页的滚动。(X坐标,Y坐标)
time.sleep(3)#需要等待滚动到底部,加载整个页面, 不然会load不完整
#抓取商品信息
#先看网页中第一件商品的位置。检查-发现该第一件商品刚好对应一个ul,所有商品都是该列表中的元素li.
#先抓取ul.copy-cpoy selector,如下
#body > div.wrap > div:nth-child(2) > div.p_main > ul
goods = browser.find_element_by_css_selector('body > div.wrap > div:nth-child(2) > div.p_main > ul').find_elements_by_tag_name('li')
#此时的goods是一个列表
print('%d页有%d件商品' % ((page + 1), len(goods)))
#遍历每个商品,获取商品信息,比如商品名字,
for good in goods:
try:
#获取商品的名字,获取结果如下:
#(第一件商品)body > div.wrap > div:nth-child(2) > div.p_main > ul > li:nth-child(1) > a:nth-child(1) > p:nth-child(2)
#(第二件商品)body > div.wrap > div:nth-child(2) > div.p_main > ul > li:nth-child(2) > a:nth-child(1) > p:nth-child(2)
#所以公有部分body > div.wrap > div:nth-child(2) > div.p_main > ul 都是已经通过good定位获取到的,所以只需要访问
title = good.find_element_by_css_selector('a:nth-child(1) > p:nth-child(2)').text
#此时good已经定位到了body > div.wrap > div:nth-child(2) > div.p_main > ul > li:nth-child(1),所以只需要定位后面的
#(第一件商品价格)body > div.wrap > div:nth-child(2) > div.p_main > ul > li:nth-child(1) > div > a > span
#(第二件商品价格)body > div.wrap > div:nth-child(2) > div.p_main > ul > li:nth-child(2) > div > a > span
price = good.find_element_by_css_selector('div > a > span').text
print(title, price)
except:
print(good.text)
#直接发http的方式的话,不会处理js的执行,所以对于动态网页,是有缺陷的。而采用selenium驱动则可以解决。
#python 开源代理池运行结果:

相关文章推荐
- Python爬虫学习笔记二:百度贴吧网页图片抓取
- Python爬虫学习笔记一:简单网页图片抓取
- Python爬虫(入门+进阶)学习笔记 1-8 使用自动化神器Selenium爬取动态网页(案例三:爬取淘宝商品)
- Python3.x 爬虫学习笔记——判断网页的编码方式
- Python爬虫框架Scrapy 学习笔记 1 ----- 环境搭建
- Python爬虫框架Scrapy 学习笔记 9 ----selenium
- python学习笔记-抓取网页图片脚本
- python爬虫框架scrapy学习笔记
- VS2013中Python学习笔记[Django Web的第一个网页]
- python爬虫框架scrapy学习笔记
- C#网页爬虫学习笔记(1)
- Python爬虫框架Scrapy 学习笔记 8----Spider
- [Python]网络爬虫1:抓取网页的含义和URL基本构成 笔记
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- [Python]网络爬虫学习笔记,爬取豆瓣妹子上妹子的照片
- Python爬虫框架Scrapy 学习笔记 7------- scrapy.Item源码剖析
- Python3.x学习笔记[1]:2种简单爬虫获取京东价格
- Python 网页爬虫-BeautifulSoup库的学习
- VS2013中Python学习笔记[Django Web的第一个网页]
- Python爬虫框架Scrapy 学习笔记 10.3 -------【实战】 抓取天猫某网店所有宝贝详情