CentOS7 从零开始搭建 Hadoop2.7集群
2017-01-09 22:58
465 查看
版权声明:本文为博主原创文章,未经博主允许不得转载。
目录(?)[+]
序言
文件准备
权限修改
配置系统环境
配置Hadoop集群
配置无密码登录
启动Hadoop
默认举例
下载软件与工具包
pscp.exe : 用于从本地到目标机器的文件传输
hadoop-2.7.3.targ.gz: Hadoop 2.7 软件包
JDK 1.8: Java 运行环境
准备四台安装好CentOS (选择基本服务器安装,最小安装会少这少那比较麻烦,反正我没有折腾了很久没有成功)的机器,且已经配置网络环境(链接方式选择桥接)。(只需要记住四台机器的IP地址,主机名后面设置)
机器1: 主机名 node, IP: 192.168.169.131
机器1: 主机名 node1, IP: 192.168.169.133
机器1: 主机名 node2, IP: 192.168.169.132
机器1: 主机名 node3, IP: 192.168.169.134
添加用户组与用户(选择安装在root用户下可以省略这步,建议在root用户下安装,这样其他用户可以方便访问)
2
1
2
复制本机文件到目标机器
2
3
4
1
2
3
4
解压并复制文件
2
3
4
5
6
7
8
9
10
11
1
2
3
4
5
6
7
8
9
10
11
修改夹所有者
1
修改组执行权限
1
配置系统变量
2
3
4
5
6
7
8
9
10
11
12
13
1
2
3
4
5
6
7
8
9
10
11
12
13
配置主机域名
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
关闭防火墙
2
1
2
修改配置文件----添加Java环境
2
3
4
5
6
1
2
3
4
5
6
配置从节点主机名
2
3
1
2
3
拷贝文件并覆盖以下文件
/home/hadoop/hadoop2.7/etc/hadoop/core-site.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/home/hadoop/hadoop2.7/etc/hadoop/hdfs-site.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
/home/hadoop/hadoop2.7/etc/hadoop/mapred-site.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/home/hadoop/hadoop2.7/etc/hadoop/yarn-site.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1、所有datanode都重复“配置Hadoop集群”前的操作
2、拷贝jdk和Hadoop文件到node1、node2、node3节点与node节点相应的路径下(scp 命令,不懂得百度一大堆)
3、修改slaves文件, 除了做secondnamenode节点外(这里是node1),其他节点均清空slaves
[hadoop@node ~]$> /home/hadoop/hadoop2.7/etc/hadoop/slaves
在所有主机上创建目录并赋予权限-----root安装此步骤省略
2
1
2
在node主机上生成RSA文件
1
生成并拷贝 authorized_keys文件
2
3
4
5
6
7
1
2
3
4
5
6
7
在所有主机上修改拥有者和权限-----root安装此步骤省略
2
1
2
修改ssh 配置文件
2
3
4
1
2
3
4
重新启动ssh
1
Note: 第一次连接仍然需要输入密码。
进入Node 主机,并切换到Hadoop账号
1
格式化 namenode
1
启动 hdfs
1
验证 hdfs 状态
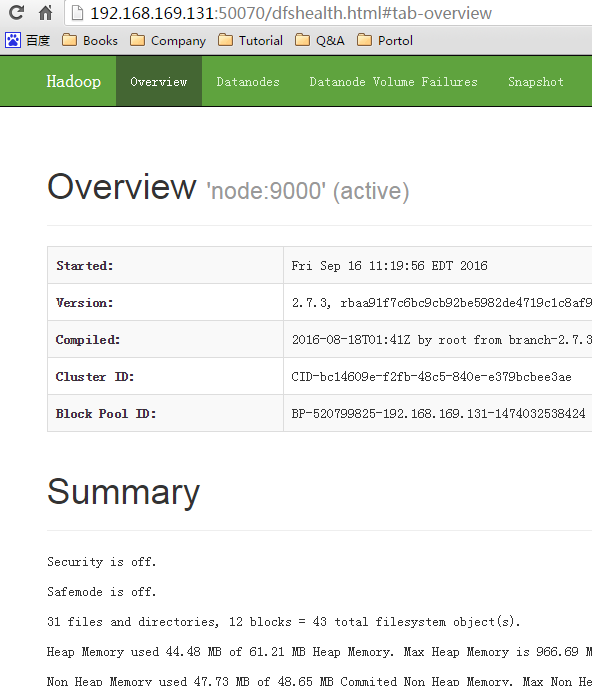
启动 yarn
1
验证 yarn 状态
创建文件夹
2
3
1
2
3
上传文件
2
3
1
2
3
执行Map-Reduce
1
查看状态
1
浏览结果
1
引用:
https://www.baidu.com/s?wd=hadoop%E9%9B%86%E7%BE%A4%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA&rsv_spt=1&rsv_iqid=0xffb1db6f0002def2&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&oq=shell%20%E5%88%9B%E5%BB%BA%E6%96%87%E4%BB%B6%E5%A4%B9&rsv_t=b457e81oNfX2KqE2N62rZkxga5NJ4LA1PBga1gBeH2Y2RZr1dK5cXsG6jPkERHUs8L6b&inputT=7316&rsv_pq=8f6d21860003ff4f&rsv_sug3=177&rsv_sug1=134&rsv_sug7=100&bs=shell%20%E5%88%9B%E5%BB%BA%E6%96%87%E4%BB%B6%E5%A4%B9
http://www.cnblogs.com/liuling/archive/2013/06/16/2013-6-16-01.html
本文转子博主:小杭嘟嘟嘟,在此表示感谢!!!
目录(?)[+]
序言
文件准备
权限修改
配置系统环境
配置Hadoop集群
配置无密码登录
启动Hadoop
默认举例
序言
下载软件与工具包 pscp.exe : 用于从本地到目标机器的文件传输
hadoop-2.7.3.targ.gz: Hadoop 2.7 软件包
JDK 1.8: Java 运行环境
准备四台安装好CentOS (选择基本服务器安装,最小安装会少这少那比较麻烦,反正我没有折腾了很久没有成功)的机器,且已经配置网络环境(链接方式选择桥接)。(只需要记住四台机器的IP地址,主机名后面设置)
机器1: 主机名 node, IP: 192.168.169.131
机器1: 主机名 node1, IP: 192.168.169.133
机器1: 主机名 node2, IP: 192.168.169.132
机器1: 主机名 node3, IP: 192.168.169.134
文件准备
添加用户组与用户(选择安装在root用户下可以省略这步,建议在root用户下安装,这样其他用户可以方便访问)groupadd hadoop useradd -d /home/hadoop -g hadoop hadoop1
2
1
2
复制本机文件到目标机器
pscp.exe -pw 12345678 hadoop-2.7.3.tar.gz root@192.168.169.131:/usr/local pscp.exe -pw 12345678 spark-2.0.0-bin-hadoop2.7.tgz root@192.168.169.131:/usr/local1
2
3
4
1
2
3
4
解压并复制文件
tar -zxvf /usr/local/jdk-8u101-linux-x64.tar.gz #重命名 mv /usr/local/jdk1.8.0_101 /usr/local/jdk1.8 tar -zxvf /usr/local/hadoop-2.7.3.tar.gz mv /usr/local/hadoop-2.7.3 /home/hadoop/hadoop2.71
2
3
4
5
6
7
8
9
10
11
1
2
3
4
5
6
7
8
9
10
11
权限修改
修改夹所有者chmod -R hadoop:hadoop /home/hadoop/hadoop2.71
1
修改组执行权限
chmod -R g=rwx /home/hadoop/hadoop2.71
1
若是以root用户安装不需要1、2步骤,root的安装是文件位置如下:Java:/usr/local/jdk1.8Hadoop:/usr/local/hadoop2.7如安装在root下,以下的遇到路径的配置做相应的修改
配置系统环境
配置系统变量echo 'export JAVA_HOME=/usr/local/jdk1.8' >> /etc/profile
echo 'export JRE_HOME=$JAVA_HOME/jre' >> /etc/profile
echo 'export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar' >> /etc/profile
echo 'export HADOOP_HOME=${hadoopFolder}' >> /etc/profile
echo 'export PATH=$HADOOP_HOME/bin:$PATH' >> /etc/profile
source /etc/profile12
3
4
5
6
7
8
9
10
11
12
13
1
2
3
4
5
6
7
8
9
10
11
12
13
配置主机域名
hostname node #当前机器名称 echo NETWORKING=yes >> /etc/sysconfig/network echo HOSTNAME=node >> /etc/sysconfig/network #当前机器名称,避免重启主机名失效 echo '192.168.169.131 node' >> /etc/hosts echo '192.168.169.133 node1' >> /etc/hosts echo '192.168.169.132 node2' >> /etc/hosts echo '192.168.169.134 node3' >> /etc/hosts1
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
关闭防火墙
systemctl stop firewalld.service systemctl disable firewalld.service1
2
1
2
配置Hadoop集群
(一)、namenode配置如下:修改配置文件----添加Java环境
sed -i 's/\${JAVA_HOME}/\/usr\/local\/jdk1.8\//' $HADOOP_HOME/etc/hadoop/hadoop-env.sh
sed -i 's/# export JAVA_HOME=\/home\/y\/libexec\/jdk1.6.0\//export JAVA_HOME=\/usr\/local\/jdk1.8\//' $HADOOP_HOME/etc/hadoop/yarn-env.sh
sed -i 's/# export JAVA_HOME=\/home\/y\/libexec\/jdk1.6.0\//export JAVA_HOME=\/usr\/local\/jdk1.8\//' $HADOOP_HOME/etc/hadoop/mapred-env.sh12
3
4
5
6
1
2
3
4
5
6
配置从节点主机名
echo node1 > $HADOOP_HOME/etc/hadoop/slaves echo node2 >> $HADOOP_HOME/etc/hadoop/slaves echo node3 >> $HADOOP_HOME/etc/hadoop/slaves1
2
3
1
2
3
拷贝文件并覆盖以下文件
/home/hadoop/hadoop2.7/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node:9000/</value>
<description>namenode settings</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp/hadoop-${user.name}</value>
<description> temp folder </description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/home/hadoop/hadoop2.7/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.http-address</name> <value>node:50070</value> <description> fetch NameNode images and edits.注意主机名称 </description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node1:50090</value> <description> fetch SecondNameNode fsimage </description> </property> <property> <name>dfs.replication</name> <value>3</value> <description> replica count </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoop/hadoop2.7/hdfs/name</value> <description> namenode </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoop/hadoop2.7/hdfs/data</value> <description> DataNode </description> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>file:///home/hadoop/hadoop2.7/hdfs/namesecondary</value> <description> check point </description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.stream-buffer-size</name> <value>131072</value> <description> buffer </description> </property> <property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> <description> duration </description> </property> </configuration>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
/home/hadoop/hadoop2.7/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobtracker.address</name> <value>hdfs://trucy:9001</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>node:10020</value> <description>MapReduce JobHistory Server host:port, default port is 10020.</description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node:19888</value> <description>MapReduce JobHistory Server Web UI host:port, default port is 19888.</description> </property> </configuration>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/home/hadoop/hadoop2.7/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>node</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>node:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>node:8088</value> </property> </configuration>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
(二)datanode配置
1、所有datanode都重复“配置Hadoop集群”前的操作2、拷贝jdk和Hadoop文件到node1、node2、node3节点与node节点相应的路径下(scp 命令,不懂得百度一大堆)
3、修改slaves文件, 除了做secondnamenode节点外(这里是node1),其他节点均清空slaves
[hadoop@node ~]$> /home/hadoop/hadoop2.7/etc/hadoop/slaves
配置无密码登录
在所有主机上创建目录并赋予权限-----root安装此步骤省略mkdir /home/hadoop/.ssh chomod 700 /home/hadoop/.ssh1
2
1
2
在node主机上生成RSA文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa1
1
生成并拷贝 authorized_keys文件
cp /home/hadoop/.ssh/id_rsa.pub authorized_keys scp /home/hadoop/.ssh/authorized_keys node1:/home/hadoop/.ssh scp /home/hadoop/.ssh/authorized_keys node2:/home/hadoop/.ssh scp /home/hadoop/.ssh/authorized_keys node3:/home/hadoop/.ssh1
2
3
4
5
6
7
1
2
3
4
5
6
7
在所有主机上修改拥有者和权限-----root安装此步骤省略
chmod 600 .ssh/authorized_keys chown -R hadoop:hadoop .ssh1
2
1
2
修改ssh 配置文件
注释掉 # AuthorizedKeysFile .ssh/authorized_keys1
2
3
4
1
2
3
4
重新启动ssh
service sshd restart1
1
Note: 第一次连接仍然需要输入密码。
启动Hadoop
进入Node 主机,并切换到Hadoop账号su hadoop1
1
格式化 namenode
/home/hadoop/hadoop2.7/bin/hdfs namenode -format1
1
启动 hdfs
/home/hadoop/hadoop2.7/sbin/start-dfs.sh1
1
验证 hdfs 状态
启动 yarn
/home/hadoop/hadoop2.7/sbin/start-yarn.sh1
1
验证 yarn 状态
默认举例
创建文件夹/home/hadoop/hadoop2.7/bin/hadoop fs -mkdir -p /data/wordcount /home/hadoop/hadoop2.7/bin/hadoop fs -mkdir -p /output/1
2
3
1
2
3
上传文件
hadoop fs -put /home/hadoop/hadoop2.2/etc/hadoop/*.xml /data/wordcount/ hadoop fs -ls /data/wordcount1
2
3
1
2
3
执行Map-Reduce
hadoop jar /home/hadoop/hadoop2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount1
1
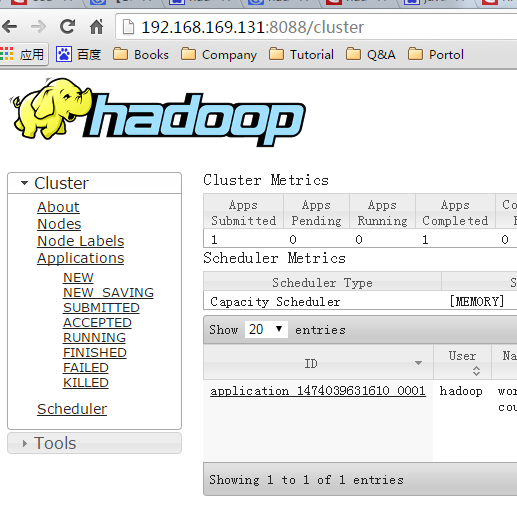
查看状态
http://192.168.169.131:8088/cluster1
1
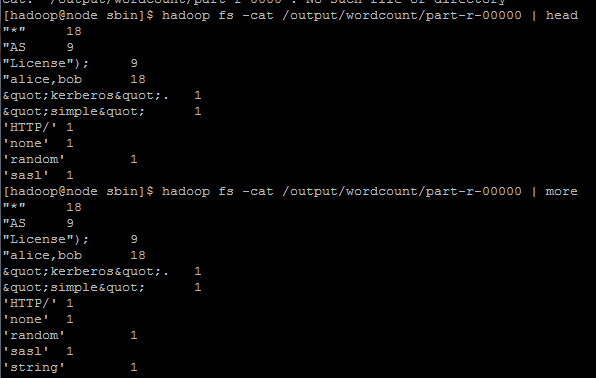
浏览结果
hadoop fs -cat /output/wordcount/part-r-00000 | more1
1
https://www.baidu.com/s?wd=hadoop%E9%9B%86%E7%BE%A4%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA&rsv_spt=1&rsv_iqid=0xffb1db6f0002def2&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&rqlang=cn&tn=baiduhome_pg&rsv_enter=1&oq=shell%20%E5%88%9B%E5%BB%BA%E6%96%87%E4%BB%B6%E5%A4%B9&rsv_t=b457e81oNfX2KqE2N62rZkxga5NJ4LA1PBga1gBeH2Y2RZr1dK5cXsG6jPkERHUs8L6b&inputT=7316&rsv_pq=8f6d21860003ff4f&rsv_sug3=177&rsv_sug1=134&rsv_sug7=100&bs=shell%20%E5%88%9B%E5%BB%BA%E6%96%87%E4%BB%B6%E5%A4%B9
http://www.cnblogs.com/liuling/archive/2013/06/16/2013-6-16-01.html
本文转子博主:小杭嘟嘟嘟,在此表示感谢!!!

相关文章推荐
- CentOS7 从零开始搭建 Hadoop2.7集群
- CentOS7 从零开始搭建 Hadoop2.7集群
- [置顶] CentOS7 基于Hadoop2.7 的Spark2.0集群搭建
- CentOS7 基于Hadoop2.7 的Spark2.0集群搭建
- CentOS7 搭建Hadoop 集群
- Hadoop2.7与Spark1.6的集群搭建
- Centos7搭建hadoop2.7
- CentOS6.5搭建Hadoop2.7集群环境前要注意的问题
- 从零开始搭建hadoop分布式集群环境:(一)新建hadoop用户以及用户组
- spark 1.5、hadoop 2.7 集群环境搭建
- VM+CentOS+hadoop2.7搭建hadoop完全分布式集群
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第五讲Hadoop图文训练课程:解决典型Hadoop分布式集群环境搭建问题
- 【Hadoop】hadoop2.7完全分布式集群搭建以及任务测试
- # 从零开始搭建Hadoop2.7.1的分布式集群
- CentOS7 基于Hadoop2.7 的Spark2.0集群搭建
- centos7下安装编译并搭建hadoop2.6.0单节点伪分布式集群
- windows+vmware+centos7+hadoop2.7搭建伪分布式集群
- hadoop2.7完全分布式集群搭建以及任务测试
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第五讲Hadoop图文训练课程:解决典型Hadoop分布式集群环境搭建问题
- linux(CentOS7)上搭建hadoop2.7分布式集群环境完整操作实战