用python 通过12306api抓取列车信息
2017-01-09 17:28
453 查看
参考:
12306官方火车票api
12306火车票查询
PS:本文为学习参考实例。代码与上述大体相同。
12306网站通过chrome可以看到查询票的api
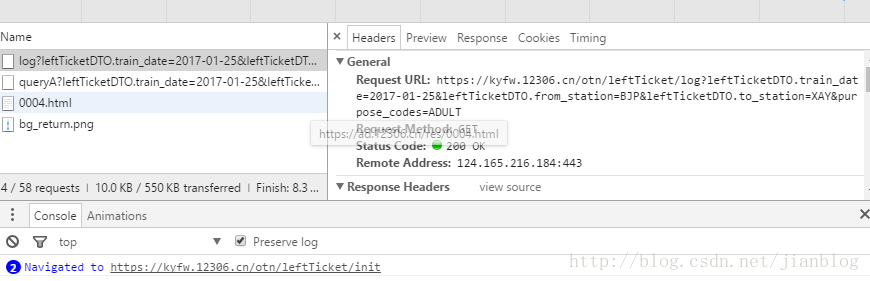
其中有log? 和 queryA?两种开头的接口,网上介绍log是判断服务是否正常,用queryA进行查询
车次 出发站/到达站 出发时间/达到时间 历时 商务座 特等座 一等座 二等座 高级软卧 软卧 硬卧 软座 硬座 无座 其他 备注
分析g653对应的key分别为:
station_train_code from_station_name/to_station_name start_time/arrive_time lishi/day_difference swz_num tz_num zy_num ze_num gr_num rw_num yw_num rz_num yz_num wz_num qt_num
车次类型分(G,D,Z,T,K)首位不是字母的是普快。
如下代码根据以上通过接口查询的结果,并根据指定列车类型过滤
程序期望的执行方法是输入形如
python tickets.py -gdt beijing shanghai 2016-08-25来查询展示。
首先,需要将参数中的-gdt 转换为内部使用的不带-大写形式的字符列表。
可以接受的列车类型包含types = [‘-d’, ‘-g’, ‘-t’, ‘-z’, ‘-k’, ‘-p’]
train_type = []
for i in types:
if i in args.keys():
train_type.append(i[-1].upper())
其次,参数需要将接收的地名拼音转换为内部的唯一地名代码
站名代码基本不变,参考中介绍了通过一个接口预先导出所有站名代码供程序直接使用。
执行脚本并定向到stations.py中,修改其中的字典头部赋值为stations = {…}
这样在之后脚本导入该模块时可以使用其中的字典变量stations.
最终代码:
该查询需要完善的地方:
1. 时间参数的多种格式,这里仅支持2017-01-11格式,应该增加其他类型。同时对于日期不再范围内,需要人为控制,避免报错
2. 站名拼音参数的搜索似乎并非严格,而是有一定模糊,比如beijing shanghai 会包含北京南。看来不用人为进行模糊匹配
12306官方火车票api
12306火车票查询
PS:本文为学习参考实例。代码与上述大体相同。
首先了解这些查询接口是怎么来的
chrome是个好东西,特别是它的控制台能看到很多细节。12306网站通过chrome可以看到查询票的api
其中有log? 和 queryA?两种开头的接口,网上介绍log是判断服务是否正常,用queryA进行查询
#在python控制台测试 > import requests > url = 'https://kyfw.12306.cn/otn/leftTicket/log?leftTicketDTO.train_date=2017-01-11&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=XAY&purpose_codes=ADULT' # 这里传入了三个变量, train_date from_station to_station 站名为缩写标准,获得方法见后面介绍 r = requests.get(url, verify = False) #chrome可以看到它用的是get方法, verify为忽略https 解析结果r.text为字典形式的字符串,通过r.json()得到解析后结果, ticks = r.json() 分析结构, ticks['data']保存所有车次的信息。G653车次的查询结果表示为 g653 = ticks['data'][1]['queryLeftNewDTO']
从结果中提取需要的字段展示
12306查询结果列表的表头包含如下字段:车次 出发站/到达站 出发时间/达到时间 历时 商务座 特等座 一等座 二等座 高级软卧 软卧 硬卧 软座 硬座 无座 其他 备注
分析g653对应的key分别为:
station_train_code from_station_name/to_station_name start_time/arrive_time lishi/day_difference swz_num tz_num zy_num ze_num gr_num rw_num yw_num rz_num yz_num wz_num qt_num
车次类型分(G,D,Z,T,K)首位不是字母的是普快。
如下代码根据以上通过接口查询的结果,并根据指定列车类型过滤
#代码与参考中大体相同
#coding=utf-8
from prettytable import PrettyTable
class TrainCollection(object):
"""
解析列车信息
"""
header = '序号 车次 出发站/到达站 出发时间/达到时间 历时 商务座 特等座 一等座 二等座 高级软卧 软卧 硬卧 软座 硬座 无座'.split()
def __init__(self, rows, traintypes):
self.rows = rows
self.traintypes = traintypes
def _get_duration(self, row):
"""
获取列车运行时间
这里的row = row['queryLeftNewDTO']
"""
duration = row.get('lishi').replace(':', '小时') + '分'
if duration.startswith('00'):
return duration[4:]
elif duration.startswith('0'):
return duration[1:]
return duration
@property #将方法trains装饰为属性,之后以属性方式访问
def trains(self):
"""
解析原有采集数据,提取需要的字段保留
"""
result = []
flag = 0
for row in self.rows:
row = row['queryLeftNewDTO']
if row['station_train_code'][0] in self.traintypes or row['station_train_code'].isdigit() and 'P' in self.traintypes:
# 如果全是数字为普快类型,自定义为P
flag += 1
train = [
flag, row['station_train_code'],
'/'.join([row['from_station_name'], row['to_station_name']]),
'/'.join([row['start_time'], row['arrive_time']]),
self._get_duration(row),
row['swz_num'], row['tz_num'],row['zy_num'],
row['ze_num'],row['gr_num'],row['rw_num'],
row['yw_num'],row['rz_num'], row['yz_num'],row['wz_num']
]
result.append(train)
return result
def print_pretty(self):
"""
通过prettytable模块将列表字段美观输出
"""
pt = PrettyTable()
pt._set_field_names(self.header)
for train in self.trains:
pt.add_row(train)
print(pt)命令行参数方式查询
参考中用来解析命令行参数使用了docopt[介绍]模块。程序期望的执行方法是输入形如
python tickets.py -gdt beijing shanghai 2016-08-25来查询展示。
首先,需要将参数中的-gdt 转换为内部使用的不带-大写形式的字符列表。
可以接受的列车类型包含types = [‘-d’, ‘-g’, ‘-t’, ‘-z’, ‘-k’, ‘-p’]
train_type = []
for i in types:
if i in args.keys():
train_type.append(i[-1].upper())
其次,参数需要将接收的地名拼音转换为内部的唯一地名代码
站名代码基本不变,参考中介绍了通过一个接口预先导出所有站名代码供程序直接使用。
#coding=utf-8
import requests
import re
from pprint import pprint
def get_stations():
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8968'
#浏览器中直接输入上面链接不用带version版本,也可以看到
r = requests.get(url, verify = False)
patter = re.compile('([A-Z]+)\|([a-z]+)')
items = dict(re.findall(patter, r.text))
# 将结果中的大写字母代码,车站拼音 反转为 车站拼音->代码的字典结构
stations = dict(zip(items.values(), items.keys()))
pprint(stations, indent=4)
if __name__ == '__main__':
get_stations()执行脚本并定向到stations.py中,修改其中的字典头部赋值为stations = {…}
这样在之后脚本导入该模块时可以使用其中的字典变量stations.
最终代码:
#coding=utf-8
"""
12306 tickets 查询
Usage:
tickets.py [-gdtkz] <from> <to> <date>
Options:
-h --help Show this screen.
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
-p 普快
Example:
tickets.py -gdt beijing shanghai 2016-11-12
"""
import requests
from docopt import docopt
from TrainCollection import TrainCollection
from stations import stations
class TicketsSearch(object):
def __init__(self):
"""
通过类的初始化获取脚本命令行参数
"""
self.args = docopt(__doc__) #通过解析脚本__doc__文本得到参数结构
def _get_traintype(self):
"""
获取列车类型
"""
types = ['-d', '-g', '-t', '-z', '-k', '-p']
train_type = []
for i in types:
if i in self.args.keys():
train_type.append(i[-1].upper())
if train_type:
return train_type
else:
return ['G', 'D', 'T', 'Z', 'K', 'P']
def cli(self):
"""根据变量执行查询"""
from_station = stations.get(self.args['<from>'])
to_station = stations.get(self.args['<to>'])
leave_time = self.args['<date>']
url = 'https://kyfw.12306.cn/otn/leftTicket/queryA?leftTicketDTO.train_date={0}&leftTicketDTO.from_station={1}&leftTicketDTO.to_station={2}&purpose_codes=ADULT'.format(leave_time, from_station, to_station)
#查询
r = requests.get(url, verify=False)
if 'data' not in r.json().keys():
print("查询日期错误,或不再预售期")
exit
traindatas = r.json()['data']
#筛选
traintypes = self._get_traintype()
trains = TrainCollection(traindatas, traintypes)
#打印
trains.print_pretty()
if __name__ == '__main__':
cli = TicketsSearch()
cli.cli()该查询需要完善的地方:
1. 时间参数的多种格式,这里仅支持2017-01-11格式,应该增加其他类型。同时对于日期不再范围内,需要人为控制,避免报错
2. 站名拼音参数的搜索似乎并非严格,而是有一定模糊,比如beijing shanghai 会包含北京南。看来不用人为进行模糊匹配

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例
- 通过构建一个简单的掷骰子游戏去学习怎么用 Python 编程