Java并发框架Disruptor实现原理与源码分析(三) RingBuffer原理模型与源码分析
2017-01-07 00:00
1151 查看
摘要: 本章节我们将开始分析在Disruptor中RingBuffer的实现原理与一些技巧,作为源码分析的开始我们会先了解一下RingBuffer的原理。

图 1-1 (画图对于程序员来讲真的不是一件容易的事) 是我们对RingBuffer的一个抽象描述。比如我们现在假定我们有一个8个槽的RingBuffer,那事实上只是一个8个长度的数组。然后我们有一个从0一直递增的序列号,我们之前提到过。那么怎么样才能模拟一个环形队列?也就是通过序列号(sequence)来映射到给定大小的数组的元素上面去,如果你看一下图 1-2 你或许一下子就能明白他们之间的关系。从数学模型的角度讲其实是一个很简单的等式,index = sequence - ( arrayLenght * (round - 1 ) ),其中round是记录圈数的。但是用于计算机处理我们有一个更高效的处理方式 index = sequence & (array length-1)。我们下面通过代码来分析一下,此部分内容我们通过代码注释来描述。

缓存行填充:这个前面已经讲过
位操作:这个虽然不是取巧的方法,但是加快了系统的计算速度,通过递增系列获取元素下标模拟一个环的算法真的很有技巧
数组预填充:这个又是一个很取巧的方法,避免了垃圾回收代来的系统开销
最后一个就是使用数组+系列号的这种方法最大限度的提高了速度。因为如果使用传统的队列的话在多线程环境下对队列头和队列尾的锁竞争是一种很大的系统开销*(这个后面讲)*
Ring based store of reusable entries containing the data representing an event being exchanged between event producer and EventProcessors.
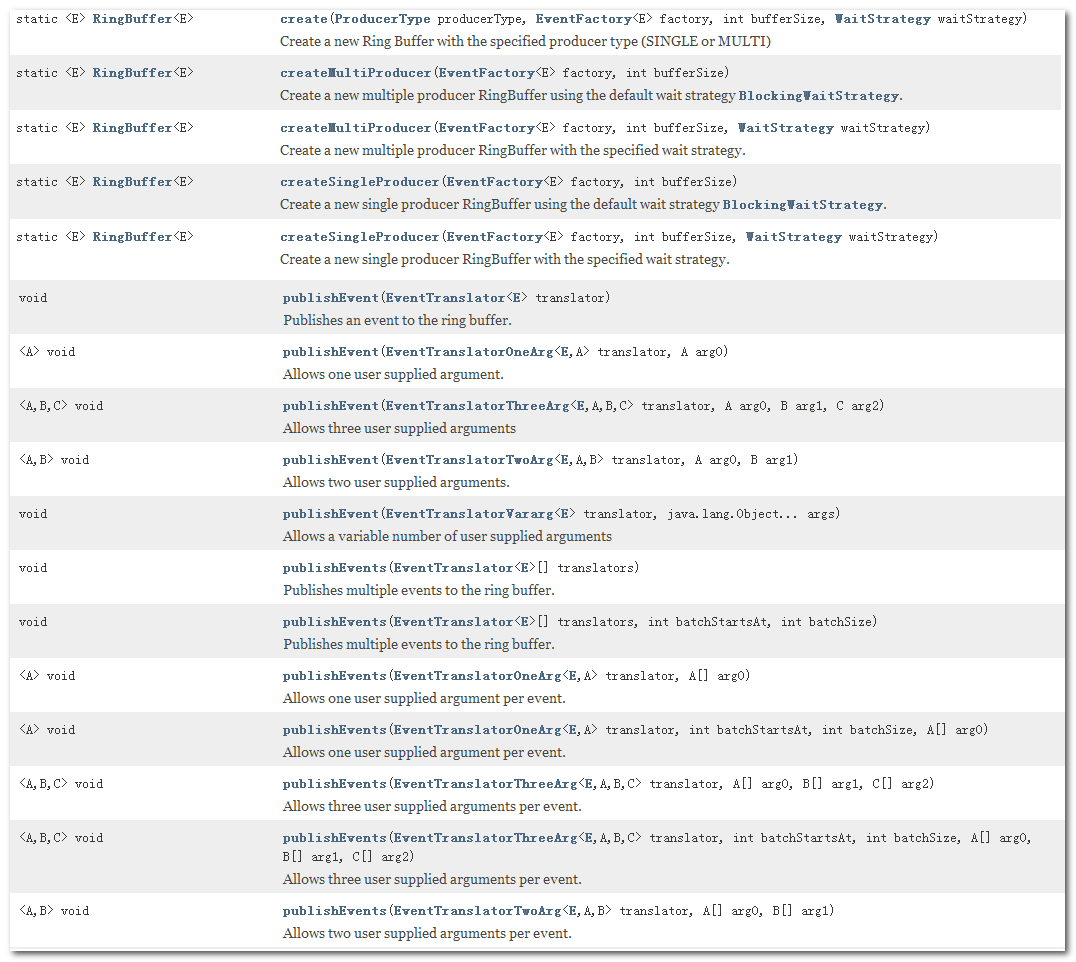
其次RingBuffer还实现了三个接口,分别是 Cursored、EventSequencer 和 EventSink,以及继承了 RingBufferFields,也就是说在RingBuffer中可以直接操作事件对象数组。
图1-4 是RingBuffer中方法的一部分,从它的方法我们可以看出RingBuffer主要的作用是用于发布事件和创建生产者,至于它是如何发布事件以及怎么样处理事件我们会在后面详细阐述。
###Sequence
Sequence在RingBuffer中是一个很重要的类,它就是指我们用来发布事件的递增系列,只不过为了更好的使用Disruptor对其做了进一步的封装。下面我们看一下它的代码*(老规矩代码解释在代码中进行)*
###Sequencer 序列跟踪器
Sequencer 是一个序列跟踪与处理的接口,它继承了Cursored与Sequenced两个接口用于对序列的处理。
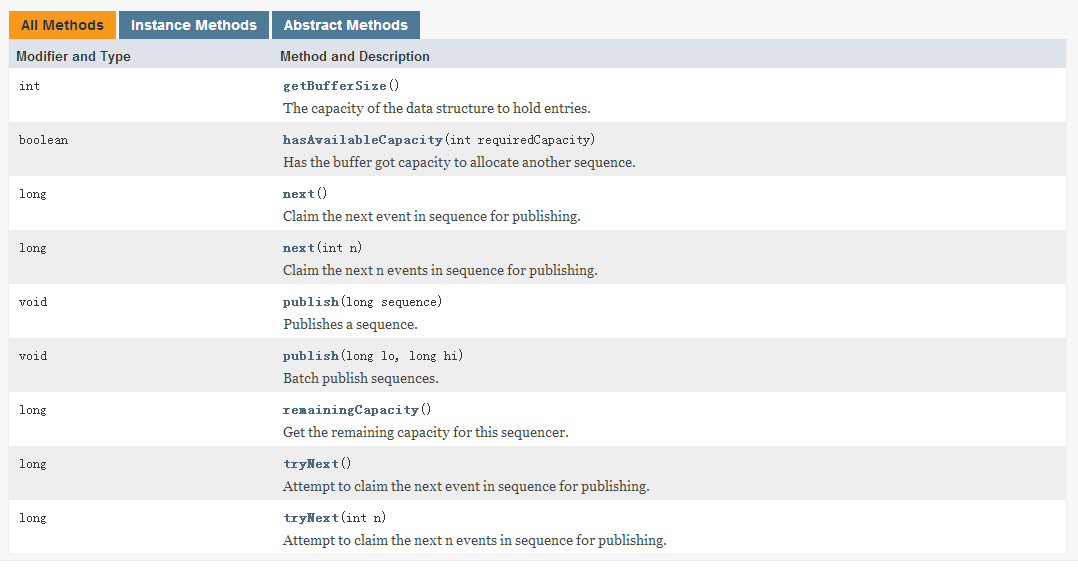
我们首先看Cursored这个接口,Cursored只提供了一个方法getCursor(),用于获取当前的游标值,这个游标值就是当前事件的发布序列号。Sequenced 接口是一个序列操作接口,用于支持对运行时的序列进行管理,下面图1-5是它的主要方法。
Sequencer有一个最直接的子类AbstractSequencer,从它的名称上就可以看出这是一个抽象类,它实现了Sequencer的一些方法,它是MultiProducerSequencer和 SingleProducerSequencer类的父类,后面我们会分析这两个类,下面我们先看AbstractSequencer这个类。
下面我们要分析的是RingBuffer中很重要的一部分,就是事件轮询机制的实现。
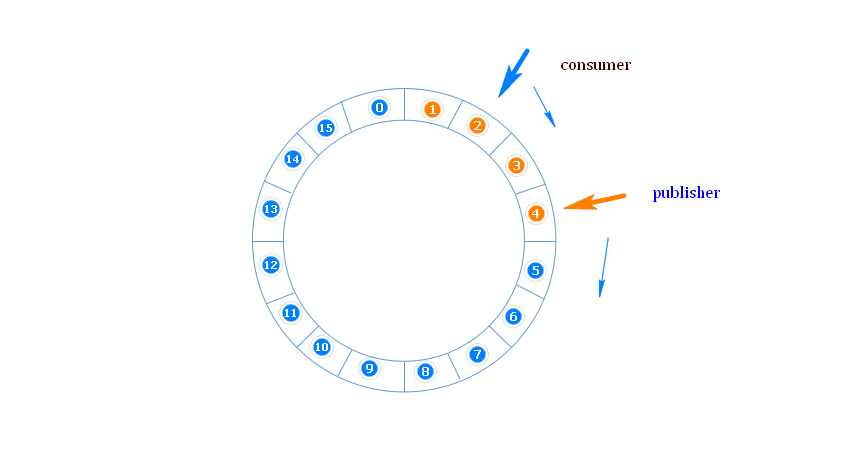
上面这幅图是RingBuffer的事件处理模型,也就是一个类似环的数组,从目前我们分析过的代码来看,Disruptor处理事件的时候依然有自己的缺陷,比如对事件的处理过程中不能发生阻塞,一旦发生阻塞就会使得整个处理系统都发生阻塞,系统将没有办法重新发布事件。
RingBuffer实现原理
我们在前面第一章节中就已经讲过RingBuffer是一个环形队列。但是今天我们要改变这样的看法,因为说它是环形队列只是找一种和它更像的数据结构去描述它。事实上它不是一个队列,因为它不具备队列的特性,比如FIFO等。RingBuffer就是一个数组,没有别的,之所以说它是环形队列是因为它通过算法维持了一个类似环形队列的数据结构。图 1-1 (画图对于程序员来讲真的不是一件容易的事) 是我们对RingBuffer的一个抽象描述。比如我们现在假定我们有一个8个槽的RingBuffer,那事实上只是一个8个长度的数组。然后我们有一个从0一直递增的序列号,我们之前提到过。那么怎么样才能模拟一个环形队列?也就是通过序列号(sequence)来映射到给定大小的数组的元素上面去,如果你看一下图 1-2 你或许一下子就能明白他们之间的关系。从数学模型的角度讲其实是一个很简单的等式,index = sequence - ( arrayLenght * (round - 1 ) ),其中round是记录圈数的。但是用于计算机处理我们有一个更高效的处理方式 index = sequence & (array length-1)。我们下面通过代码来分析一下,此部分内容我们通过代码注释来描述。
/*
RingBufferPad 作为RingBufferFields的超类他的作用只是通过7个long变量去填充缓存行
RingBufferFields 是RingBuffer的超类,也是其中很重要的组成部分,它里面维护了一个Event对象的环形数组
*/
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
private static final int BUFFER_PAD;
private static final long REF_ARRAY_BASE;
private static final int REF_ELEMENT_SHIFT;
private static final Unsafe UNSAFE = Util.getUnsafe();
static
{
/*
UNSAFE.arrayIndexScale 是获取一个数组在内存中的scale,也就是每个数组元素在内存中的大小
因为我们的event是任意一个对象,所以在这里用一个Object的数组class来求scale
*/
final int scale = UNSAFE.arrayIndexScale(Object[].class);
//不同的JVM设置,它的指针大小是不一样的
if (4 == scale)
{
REF_ELEMENT_SHIFT = 2;
}
else if (8 == scale)
{
REF_ELEMENT_SHIFT = 3;
}
else
{
throw new IllegalStateException("Unknown pointer size");
}
BUFFER_PAD = 128 / scale;
// 获取数组在内存中的偏移量,也就是第一个元素的内存偏移量
REF_ARRAY_BASE = UNSAFE.arrayBaseOffset(Object[].class) + (BUFFER_PAD << REF_ELEMENT_SHIFT);
}
private final long indexMask;
private final Object[] entries;//申明一个对象数组
protected final int bufferSize;
protected final Sequencer sequencer;
RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer)
{
this.sequencer = sequencer;
this.bufferSize = sequencer.getBufferSize();
if (bufferSize < 1)
{
throw new IllegalArgumentException("bufferSize must not be less than 1");
}
if (Integer.bitCount(bufferSize) != 1)
{
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.indexMask = bufferSize - 1;//indexMask 就是数组的最大下标
//可以看出在创建数组的时候预留了两个单位的缓存填充
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];//这个地方我认为有BUG存在,请大神解答
/*
一次性填充慢整个数组,这样做又是一个比较有技巧的做法
他通过填充慢数组,在运行时改变对象的值来达到防止Java垃圾回收(GC)产生的系统开销
换句话说就是它不需要垃圾回收
*/
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory)
{
for (int i = 0; i < bufferSize; i++)
{
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
/*
获取指定序列号对应的数组元素,也就是event
*/
@SuppressWarnings("unchecked")
protected final E elementAt(long sequence)
{
//这个地方就是我们讲的通过递增序列号获取与序列号对应的数组元素
return (E) UNSAFE.getObject(entries, REF_ARRAY_BASE + ((sequence & indexMask) << REF_ELEMENT_SHIFT));
}
}原理技巧总结
通过上面的分析,我们可以看出在实现RingBufferFields这个对象的时候有很多非常取巧的地方*(取巧不一定是贬义,也是创新的表现,最恨那句投机取巧,扼杀了多少孩子的创新*)。缓存行填充:这个前面已经讲过
位操作:这个虽然不是取巧的方法,但是加快了系统的计算速度,通过递增系列获取元素下标模拟一个环的算法真的很有技巧
数组预填充:这个又是一个很取巧的方法,避免了垃圾回收代来的系统开销
最后一个就是使用数组+系列号的这种方法最大限度的提高了速度。因为如果使用传统的队列的话在多线程环境下对队列头和队列尾的锁竞争是一种很大的系统开销*(这个后面讲)*
RingBuffer 概览##
RingBuffer 官方的说法是保存事件生产者与事件操作者之间的数据载体,下面是官方原版Ring based store of reusable entries containing the data representing an event being exchanged between event producer and EventProcessors.
其次RingBuffer还实现了三个接口,分别是 Cursored、EventSequencer 和 EventSink,以及继承了 RingBufferFields,也就是说在RingBuffer中可以直接操作事件对象数组。
图1-4 是RingBuffer中方法的一部分,从它的方法我们可以看出RingBuffer主要的作用是用于发布事件和创建生产者,至于它是如何发布事件以及怎么样处理事件我们会在后面详细阐述。
Sequence相关实现
为了更好的去观察整个RingBuffer的时间发布与事件处理机制我们先需要分析一下和时间发布密切相关的sequence 的一些类和方法。###Sequence
Sequence在RingBuffer中是一个很重要的类,它就是指我们用来发布事件的递增系列,只不过为了更好的使用Disruptor对其做了进一步的封装。下面我们看一下它的代码*(老规矩代码解释在代码中进行)*
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;//volatile 语义
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
/**
* Concurrent sequence class used for tracking the progress of
* the ring buffer and event processors. Support a number
* of concurrent operations including CAS and order writes.
*
* Also attempts to be more efficient with regards to false
* sharing by adding padding around the volatile field.
上面这段是官方解释,意思就是说为事件的并发操作提供一个原子的数字,同时通过缓存行填充来解决假共享来提高运行效率
*/
public class Sequence extends RhsPadding
{
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static
{
UNSAFE = Util.getUnsafe();
try
{ //这是一段内存操作,用来获取超类中value字段的内存偏移地址
VALUE_OFFSET = UNSAFE.objectFieldOffset(Value.class.getDeclaredField("value"));
}
catch (final Exception e)
{
throw new RuntimeException(e);
}
}
/**
* 这个是一个初始化方法,默认系列号是-1
*/
public Sequence()
{
this(INITIAL_VALUE);
}
/**
初始化方法,通过unsafe的putOrderedLong方法将value立即回写到主内存中以保证其对其他线程的可见性
我们在前面讲过,一个volatile语义的变量在它的写之前,编译器会加一个Store/Store内存屏障
关于这部分内容可以查看之前的博客,或者详细了解volatile语言的实现原理
*/
public Sequence(final long initialValue)
{
UNSAFE.putOrderedLong(this, VALUE_OFFSET, initialValue);
}
/**
获取当前保存的系列值
*/
public long get()
{
return value;
}
/**
这个和前面的那个初始化方法是一致的,只不过用于在运行期进行值操作
*/
public void set(final long value)
{
UNSAFE.putOrderedLong(this, VALUE_OFFSET, value);
}
/**
这是一个实现了Volatile语义的写方法(变量必须实现Volatile语义),和上面的方法一样,它也会在写操作前面加内存屏障
*/
public void setVolatile(final long value)
{
UNSAFE.putLongVolatile(this, VALUE_OFFSET, value);
}
/**
这个就是我们前面讲过的CAS原子操作,用来原子的给某个变量赋值,
*/
public boolean compareAndSet(final long expectedValue, final long newValue)
{
return UNSAFE.compareAndSwapLong(this, VALUE_OFFSET, expectedValue, newValue);
}
/**
获取一个+1后的long值,值得注意的是这个方法是原子的,请看下面
*/
public long incrementAndGet()
{
return addAndGet(1L);
}
/**
它是通过CAS操作来实现原子性
*/
public long addAndGet(final long increment)
{
long currentValue;
long newValue;
//从这里可以看出,通过一个循环来进行值的原子操作,直到操作成功
//循环的原因就是,当其他线程对这个值进行操作的时候会对缓存行加锁,所以这里需要不断的进行CAS操作
//(这个地方是系统中相对比较耗费的地方)
do
{
currentValue = get();
newValue = currentValue + increment;
}
while (!compareAndSet(currentValue, newValue));
return newValue;
}
@Override
public String toString()
{
return Long.toString(get());
}
}###Sequencer 序列跟踪器
Sequencer 是一个序列跟踪与处理的接口,它继承了Cursored与Sequenced两个接口用于对序列的处理。
我们首先看Cursored这个接口,Cursored只提供了一个方法getCursor(),用于获取当前的游标值,这个游标值就是当前事件的发布序列号。Sequenced 接口是一个序列操作接口,用于支持对运行时的序列进行管理,下面图1-5是它的主要方法。
Sequencer有一个最直接的子类AbstractSequencer,从它的名称上就可以看出这是一个抽象类,它实现了Sequencer的一些方法,它是MultiProducerSequencer和 SingleProducerSequencer类的父类,后面我们会分析这两个类,下面我们先看AbstractSequencer这个类。
public abstract class AbstractSequencer implements Sequencer
{
//AtomicReferenceFieldUpdater 是Java并发包中的一个原子操作类,它的newUpdater用于对volatile语义的对象进行原子更新
private static final AtomicReferenceFieldUpdater<AbstractSequencer, Sequence[]> SEQUENCE_UPDATER =
AtomicReferenceFieldUpdater.newUpdater(AbstractSequencer.class, Sequence[].class, "gatingSequences");
protected final int bufferSize;//数组的大小,也就是RingBuffer环的大小
protected final WaitStrategy waitStrategy;//等待策略,这个后面分析
protected final Sequence cursor = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);//当前发布的事件的游标,它也是一个序列
protected volatile Sequence[] gatingSequences = new Sequence[0];//事件序列,用于做事件控制
/**
初始化方法,一个简单的初始化,这里就不过多赘述
*/
public AbstractSequencer(int bufferSize, WaitStrategy waitStrategy)
{
if (bufferSize < 1)
{
throw new IllegalArgumentException("bufferSize must not be less than 1");
}
if (Integer.bitCount(bufferSize) != 1)
{
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.bufferSize = bufferSize;
this.waitStrategy = waitStrategy;
}
/**
* 返回当前的游标
*/
@Override
public final long getCursor()
{
return cursor.get();
}
/**
* 获取bufferSize
*/
@Override
public final int getBufferSize()
{
return bufferSize;
}
/**
* 这个方法我们在后面分析SequenceGroups的时候讲
*/
@Override
public final void addGatingSequences(Sequence... gatingSequences)
{
SequenceGroups.addSequences(this, SEQUENCE_UPDATER, this, gatingSequences);
}
@Override
public boolean removeGatingSequence(Sequence sequence)
{
return SequenceGroups.removeSequence(this, SEQUENCE_UPDATER, sequence);
}
/**
* 这个方法用于返回当前游标与给定序列中的最小值
用于做事件的控制,比如当前处理速度最慢的游标
*/
@Override
public long getMinimumSequence()
{
return Util.getMinimumSequence(gatingSequences, cursor.get());
}
/**
* SequenceBarrier 会在后面讲
*/
@Override
public SequenceBarrier newBarrier(Sequence... sequencesToTrack)
{
return new ProcessingSequenceBarrier(this, waitStrategy, cursor, sequencesToTrack);
}
/**
创建一个事件轮询器
*/
@Override
public <T> EventPoller<T> newPoller(DataProvider<T> dataProvider, Sequence... gatingSequences)
{
return EventPoller.newInstance(dataProvider, this, new Sequence(), cursor, gatingSequences);
}
}下面我们要分析的是RingBuffer中很重要的一部分,就是事件轮询机制的实现。
//这部分的代码是事件轮询的具体实现
public PollState poll(final Handler<T> eventHandler) throws Exception
{
final long currentSequence = sequence.get();
long nextSequence = currentSequence + 1;
final long availableSequence = sequencer.getHighestPublishedSequence(nextSequence, gatingSequence.get());
//从下面这段代码我们可以看出,它的作用就是防止事件发布的时候当前发布的事件将正在处理的事件覆盖掉
//为了防止超过正在处理的事件它会在这个位置进行等待,知道可以发布为止
//所以从这段代码我们得出一个结论,就是在事件处理方法中不要发生阻塞,如果阻塞它会影响整个系统运行
//发生阻塞会使得整个系统都阻塞在一个地方
if (nextSequence <= availableSequence)
{
boolean processNextEvent;
long processedSequence = currentSequence;
try
{
do
{
final T event = dataProvider.get(nextSequence);
processNextEvent = eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
processedSequence = nextSequence;
nextSequence++;
}
while (nextSequence <= availableSequence & processNextEvent);
}
finally
{
sequence.set(processedSequence);
}
return PollState.PROCESSING;
}
else if (sequencer.getCursor() >= nextSequence)
{
return PollState.GATING;
}
else
{
return PollState.IDLE;
}
}上面这幅图是RingBuffer的事件处理模型,也就是一个类似环的数组,从目前我们分析过的代码来看,Disruptor处理事件的时候依然有自己的缺陷,比如对事件的处理过程中不能发生阻塞,一旦发生阻塞就会使得整个处理系统都发生阻塞,系统将没有办法重新发布事件。

相关文章推荐
- Java并发框架Disruptor实现原理与源码分析(二) 缓存行填充与CAS操作
- java并发编程之源码分析ThreadPoolExecutor线程池实现原理
- java并发容器CopyOnWriteArrayList实现原理及源码分析
- Java并发(4)深入分析java线程池框架及实现原理(一)
- Java 并发框架 Disruptor 源码分析:RingBuffer
- Java并发(5)深入分析java线程池框架及实现原理(二)
- java并发锁ReentrantLock源码分析一 可重入支持中断锁的实现原理
- 【1】Java 并发编程--深入分析Volatile的实现原理
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包含增删改查、JavaBean反射原理,附源码)
- java非并发容器ArrayList 和 LinkedList 优缺点比较及其实现源码分析
- [转]Java7中的ForkJoin并发框架初探(中)——JDK中实现简要分析
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包含增删改查、JavaBean反射原理,附源码)
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包含增删改查、JavaBean反射原理,附源码)
- 【源码分享】WPF漂亮界面框架实现原理分析及源码分享
- JAVA并发框架之Semaphore实现生产者与消费者模型
- Java集合ArrayList实现原理——源码分析
- 【源码分享】WPF漂亮界面框架实现原理分析及源码分享
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包含增删改查、JavaBean反射原理,附源码)
- 高性能并发框架 Disruptor 介绍 实现生产者消费者模型
- [转]Java7中的ForkJoin并发框架初探(中)——JDK中实现简要分析