《Hadoop 2.x HDFS源码剖析》1 — HDFS 体系结构与基本概念
2017-01-06 20:29
513 查看
1. HDFS 体系结构
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)最开始作为Apache Nutch搜索引擎的基础架构而开发的,是Apache Hadoop Core项目的一部分。HDFS是一个可以运行在通用硬件上、提供流式数据操作、处理超大文件的分布式文件系统。HDFS是一个主/从(master/slave)体系结构的分布式系统,如下图所示。HDFS集群拥有一个Namenode和多个Datanode,用户可以通过 HDFS 客户端通 Namenode 和 Datanodes 交互以访问文件系统。
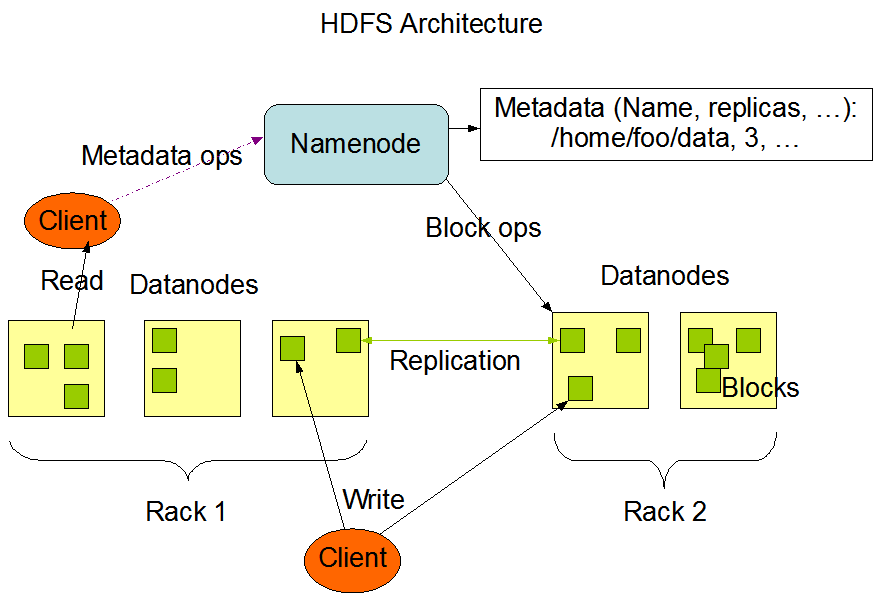
Figure 1. HDFS Architecture
在 HDFS 中,Namenode 是 HDFS 的 Master 节点,负责管理文件系统的命名空间(namespace)和数据块到具体 Datanode 节点的映射等信息。集群中的 Datanode一般是一个节点一个,负责管理 Datanode 所在节点上的数据存储。从内部看,一个文件分成多个数据块(block)存储在一组 Datanode 上,其数据块与 Datanode 的映射信息存储在 Namenode 的 metadata 中,Datanode以本地文件的形式保存数据以及校验信息。
用户通过 HDFS 客户端发起读写 HDFS 文件的请求,同时可通过 HDFS 客户端对文件系统的命名空间操作,如打开、关闭、重命名文件或目录。
2. HDFS基本概念
2.1 数据块(Block)
HDFS 的数据块的概念与 Linux 文件系统(ext2、ext3)的数据块类似,是 HDFS 文件处理的最小单元。由于 HDFS 处理的文件比较大,为了最小化寻址开销,所以 HDFS 数据块也比较大,默认 128M。public static final String DFS_BLOCK_SIZE_KEY = "dfs.blocksize"; // HDFS 的数据块的默认大小 128M public static final long DFS_BLOCK_SIZE_DEFAULT = 128*1024*1024;
在 HDFS 中,所有文件都会被切分成若干数据块分布在数据节点上存储,同时每个数据块会冗余备份到不同的数据节点上(机架感知,默认保存3份)。
public static final String DFS_REPLICATION_KEY = "dfs.replication"; public static final short DFS_REPLICATION_DEFAULT = 3;
HDFS 的读写操作中,数据块是最小单元。在读操作中,HDFS 客户端会首先请求 Namenode 获取包含该数据块的位置信息,然后根据数据块的位置信息进行读操作(流处理)。在写操作中,HDFS 客户端首先申请新的数据块,然后根据新申请的数据块的位置信息建立数据流管道写数据。
2.2 名字节点(Namenode)
名字节点(Namenode)管理文件系统的命名空间(namespace),包括文件目录树、文件/目录信息以及数据块索引(映射信息)等,这些信息保存在命名空间镜像文件(fsimage)和编辑日志文件(editlog)。同时名字节点还保存数据块与数据节点的映射关系,这些信息是在名字节点启动时动态构建的,即映射关系保存在内存中。名字节点是 HDFS的单一故障点,Hadoop 2.x 引入了名字节点高可用性(HA)的支持。在 HA 实现中,同一个 HDFS 集群中会配置两个名字节点——活动名字节点(Active Namenode)和备用名字节点(Standby Namenode)。活动名字节点发生故障时,备用名字节点可立即切换为活动状态。
名字节点的内存中保存了文件系统的命名空间和数据块的映射信息,所以在集群中文件数据量很大的时候,名字节点的内存将成为限制系统横向扩张的瓶颈。为解决这个问题,Hadoop 2.x 引入了联邦 HDFS 机制(HDFS Federation)。联邦 HDFS 机制可以添加名字节点实现命名空间的扩展,每个名字节点管理文件系统命名空间的一部分,作为独立的命名空间卷(namespace volume)。
2.3 数据节点(Datanode)
数据节点是 HDFS 中的从节点,数据节点会根据 HDFS 客户端请求或 Namenode 调度将新的数据块写入本地存储,或读出本地存储上保存的数据块。数据节点会不断向名字节点发送心跳信息、数据块汇报以及缓存汇报等信息,名字节点会通过心跳、数据块汇报以及缓存汇报的响应(Datanode调用汇报信息接口的返回值)向数据节点发送指令,数据节点执行这些指令,如创建、删除或复制数据。
2.4 客户端
HDFS 提供了多种客户端接口供应用程序及用户使用,包括命令行接口、HTTP 接口、API 接口,使用这些接口可以很方便地使用 HDFS,而不需要考虑底层实现细节。这些 HDFS 客户端接口的实现建立在
DFSClient类额基础上,
DFSClient类封装了客户端与 HDFS 其他节点间的复杂交互。
2.5 HDFS 通信协议
HDFS 涉及数据节点、名字节点和客户端之间的配合、相互调用,为了降低节点间代码的耦合性,提高单个节点代码的内聚性,HDFS 将这些节点间的通信抽象城不同的接口。HDFS 节点间的接口主要有如下两种:Hadoop RPC 接口:HDFS 中基于 Hadoop RPC 框架实现的接口;
流式接口:HDFS 中基于 TCP 或者 HTTP 实现的接口;

相关文章推荐
- [Azure]基于Invoke-Parallel对Azure ARM虚拟机批量开关机
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
- LNMP环境下安装DiscuzX3.3
- windows下安装Spark
- 在Linux下操作MySQL的简单命令
- 【Linux】简单实现进度条
- linux centos7 安装出现 license information(license not accepted)解决办法
- nginx启动脚本(样本)
- tinyxml解析xml文件
- 【Bash百宝箱】awk
- linux最基础的命令
- tomcat启动和配置
- Linux下手工大件本地Yum仓库
- docker配置独立桥接IP
- Linux 中强大且常用命令:find、grep
- 博客园博客转至个人网站博客声明
- docker常用命令
- linux at命令的使用
- linux中cp,用户切换
- tomcat 启动时初始化log4j时报NullPointerException