sklearn中SVM简单使用
2017-01-04 20:34
246 查看
在看周志华老师的机器学习书时,利用sklearn中的SVM解决第六章的一些课后习题。
*************************************************************************************************************
1、在西瓜数据集3.0alpha上分别用线性和高斯核训练一个SVM,并比较其支持向量的差别。
2、以“密度”为输入,“含糖量”为输出,训练一个SVR。
数据如下:
编号 密度 含糖率 好瓜
1 0.697 0.46 是
2 0.774 0.376 是
3 0.634 0.264 是
4 0.608 0.318 是
5 0.556 0.215 是
6 0.403 0.237 是
7 0.481 0.149 是
8 0.437 0.211 是
9 0.666 0.091 否
10 0.243 0.267 否
11 0.245 0.057 否
12 0.343 0.099 否
13 0.639 0.161 否
14 0.657 0.198 否
15 0.36 0.37 否
16 0.593 0.042 否
17 0.719 0.103 否
代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Dec 29 21:14:16 2016
@author: ZQ
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.svm import SVR
def plot_decision_function(X,classifier,sample_weight,axis,title):
xx,yy = np.meshgrid(np.linspace(-4,5,500),np.linspace(-4,5,500))
Z = classifier.decision_function(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
axis.contourf(xx,yy,Z,alpha = 0.75,cmap = plt.cm.bone)
axis.scatter(X[:,0],X[:,1],c=y,s=100*sample_weight,alpha = 0.9,
cmap = plt.cm.bone)
axis.axis('off')
axis.set_title(title)
def loadData(filename):
data = []
with open(filename) as f:
for line in f.readlines():
data.append(line.strip().split('\t')[1:])
return np.array(data[1:])
def initData(data):
m,n = np.shape(data)
retDat = np.zeros((m,n))
for i in range(m):
for j in range(n):
if data[i][j] == '是':
retDat[i][j] = 0
elif data[i][j] == '否':
retDat[i][j] = 1
else:
retDat[i][j] = float(data[i][j])
return retDat
if __name__ == '__main__':
data = loadData('watermelon3.0Alpha.txt')
num_data = initData(data)
x = num_data[:,:2]
y = num_data[:,-1]
"""
#线性画图
lclf = SVC(C = 1.0,gamma=0.1,kernel='linear')
bclf = SVC(C = 1.0,gamma = 0.1)
plt.scatter(x[:,0],x[:,1],c = y)
xx = np.linspace(-5,5)
lclf.fit(x,y)
lw = lclf.coef_[0]
la = -lw[0]/lw[1]
ly = la*xx - lclf.intercept_[0]/lw[1]
h0 = plt.plot(xx,ly,'k-',label = 'linear')
"""
"""
#高斯画图
bclf.fit(x,y)
weight = np.ones(len(x))
fig,axis = plt.subplots(1,1)
plot_decision_function(x,bclf,weight,axis,'test')
"""
#训练的SVR
结果如下:
对于线性和高斯核的SVC的支持向量都是相同的,如下:

更为直观的画图显示,第一个为线性核,第二个为高斯核。
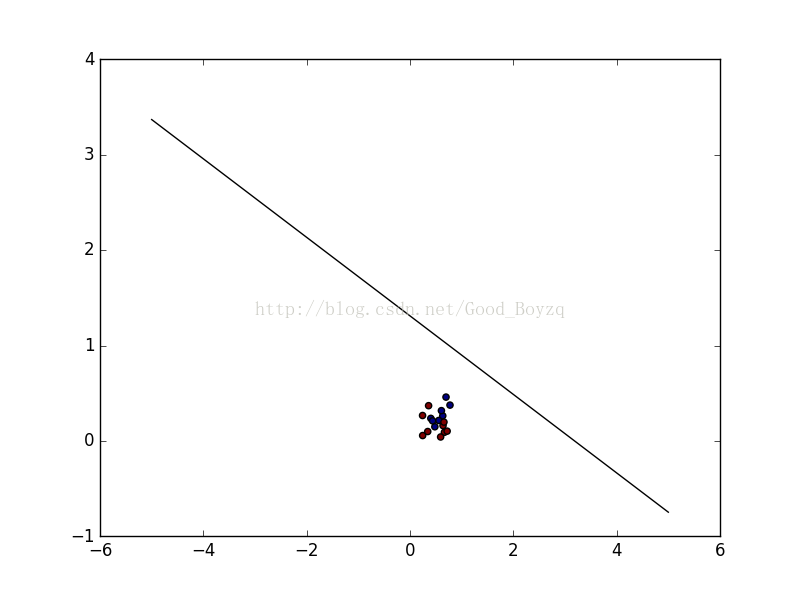

不知道是代码原因还是数据原因导致结果不是很好。希望大家能多多指正。
SVR的结果如下:
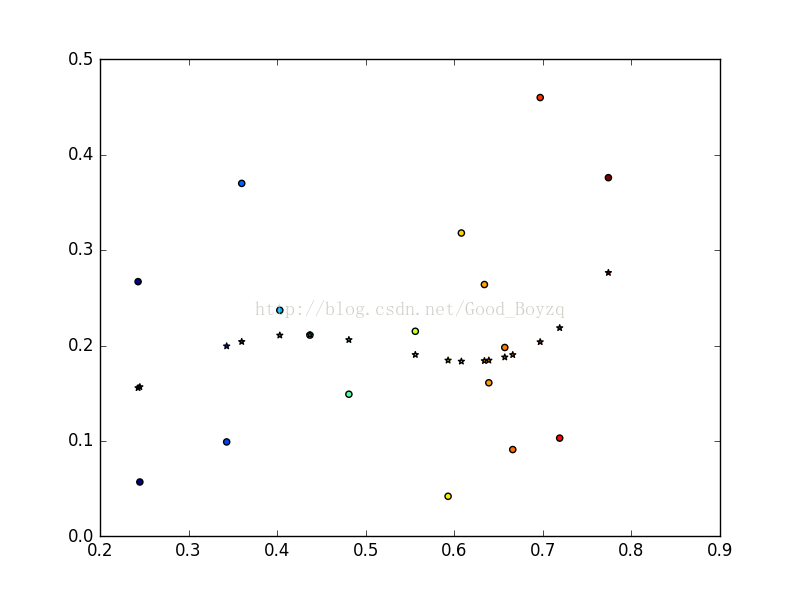
*************************************************************************************************************
1、在西瓜数据集3.0alpha上分别用线性和高斯核训练一个SVM,并比较其支持向量的差别。
2、以“密度”为输入,“含糖量”为输出,训练一个SVR。
数据如下:
编号 密度 含糖率 好瓜
1 0.697 0.46 是
2 0.774 0.376 是
3 0.634 0.264 是
4 0.608 0.318 是
5 0.556 0.215 是
6 0.403 0.237 是
7 0.481 0.149 是
8 0.437 0.211 是
9 0.666 0.091 否
10 0.243 0.267 否
11 0.245 0.057 否
12 0.343 0.099 否
13 0.639 0.161 否
14 0.657 0.198 否
15 0.36 0.37 否
16 0.593 0.042 否
17 0.719 0.103 否
代码:
# -*- coding: utf-8 -*-
"""
Created on Thu Dec 29 21:14:16 2016
@author: ZQ
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.svm import SVR
def plot_decision_function(X,classifier,sample_weight,axis,title):
xx,yy = np.meshgrid(np.linspace(-4,5,500),np.linspace(-4,5,500))
Z = classifier.decision_function(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
axis.contourf(xx,yy,Z,alpha = 0.75,cmap = plt.cm.bone)
axis.scatter(X[:,0],X[:,1],c=y,s=100*sample_weight,alpha = 0.9,
cmap = plt.cm.bone)
axis.axis('off')
axis.set_title(title)
def loadData(filename):
data = []
with open(filename) as f:
for line in f.readlines():
data.append(line.strip().split('\t')[1:])
return np.array(data[1:])
def initData(data):
m,n = np.shape(data)
retDat = np.zeros((m,n))
for i in range(m):
for j in range(n):
if data[i][j] == '是':
retDat[i][j] = 0
elif data[i][j] == '否':
retDat[i][j] = 1
else:
retDat[i][j] = float(data[i][j])
return retDat
if __name__ == '__main__':
data = loadData('watermelon3.0Alpha.txt')
num_data = initData(data)
x = num_data[:,:2]
y = num_data[:,-1]
"""
#线性画图
lclf = SVC(C = 1.0,gamma=0.1,kernel='linear')
bclf = SVC(C = 1.0,gamma = 0.1)
plt.scatter(x[:,0],x[:,1],c = y)
xx = np.linspace(-5,5)
lclf.fit(x,y)
lw = lclf.coef_[0]
la = -lw[0]/lw[1]
ly = la*xx - lclf.intercept_[0]/lw[1]
h0 = plt.plot(xx,ly,'k-',label = 'linear')
"""
"""
#高斯画图
bclf.fit(x,y)
weight = np.ones(len(x))
fig,axis = plt.subplots(1,1)
plot_decision_function(x,bclf,weight,axis,'test')
"""
#训练的SVR
svr_rbf = SVR(kernel = 'rbf',C = 1e3,gamma = 3) X = x[:,0].reshape((17,1)) y = x[:,1].reshape((17,1)) y_rbf = svr_rbf.fit(X,y.ravel()).predict(X) plt.scatter(x[:,0],x[:,1],c = x[:,0]) plt.scatter(x[:,0],y_rbf,c = x[:,0],marker = '*') plt.show()
结果如下:
对于线性和高斯核的SVC的支持向量都是相同的,如下:
更为直观的画图显示,第一个为线性核,第二个为高斯核。
不知道是代码原因还是数据原因导致结果不是很好。希望大家能多多指正。
SVR的结果如下:

相关文章推荐
- opencv下使用SVM进行简单颜色分类
- python中sklearn的朴素贝叶斯方法(sklearn.naive_bayes.GaussianNB)的简单使用
- SVM对文字识别的简单使用
- 使用sklearn的RandomForestClassifier做简单的二分类
- Logistic Regression 简单原理和 Sklearn and Theano中使用
- 基于Python使用SVM识别简单的字符验证码的完整代码开源分享
- sklearn的简单使用
- 机器学习作业5 - 使用SkLearn中的SVM进行学习
- 使用SVM预测大盘涨跌的简单策略
- 使用sklearn中svm做多分类时难点解惑
- 支持向量机(SVM)理解以及在sklearn库中的简单应用
- sklearn中 svm.SVC 函数使用方法和参数说明
- Python机器学习包的sklearn中的Gridsearch简单使用
- 关于sklearn的简单使用1(分类)
- 如何使用sklearn中的SVM
- 如何使用sklearn中的SVM(SVC;SVR)
- 机器学习-python通过使用sklearn编写支持向量机SVM
- 支持向量机(SVM)理解以及在sklearn库中的简单应用
- Python3.5+sklearn 使用SVM自动识别字母验证码
- 封装JDBC,简单快捷的使用PreparedStatement对象