决策树(含python源代码)
2016-12-31 21:55
225 查看
因为最近实习的需要,所以用python里的sklearn包重新写了一次决策树
工具:sklearn,http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy;将dot文件转化为pdf格式(是为了将形成的决策树可视化)graphviz-2.38,下载解压之后将其中的bin文件的目录添加进环境变量
源代码如下:
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
from xml.sax.handler import feature_external_ges
from numpy.distutils.fcompiler import dummy_fortran_file
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'E:/DeepLearning/resources/AllElectronics.csv', 'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
featureList = []
lableList = []
for row in reader:
lableList.append(row[len(row)-1])
rowDict = {}
#不包括len(row)-1
for i in range(1,len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
vec = DictVectorizer()
dummX = vec.fit_transform(featureList).toarray()
print(str(dummX))
lb = preprocessing.LabelBinarizer()
dummY = lb.fit_transform(lableList)
print(str(dummY))
#entropy=>ID3
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummX, dummY)
print("clf:"+str(clf))
#可视化tree
with open("resultTree.dot",'w')as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(),out_file = f)
#对于新的数据怎样来查看它的分类
oneRowX = dummX[0,:]
print("oneRowX: "+str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
predictedY = clf.predict(newRowX)
print("predictedY: "+ str(predictedY))
这里的AllElectronics.csv,形式如下图所示:
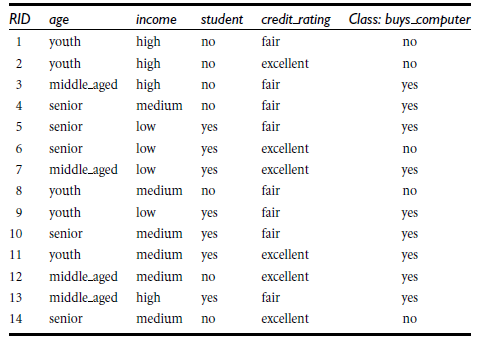
今天早上好不容易将jdk、eclipse以及pydev装进linux,但是,但是,但是,想装numpy的时候,总是报错,发现是没有gcc,然后又去装gcc,真是醉了,到现在gcc还是没有装成功,再想想法子,实在不行过段时间去问大神
工具:sklearn,http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy;将dot文件转化为pdf格式(是为了将形成的决策树可视化)graphviz-2.38,下载解压之后将其中的bin文件的目录添加进环境变量
源代码如下:
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import tree
from sklearn import preprocessing
from sklearn.externals.six import StringIO
from xml.sax.handler import feature_external_ges
from numpy.distutils.fcompiler import dummy_fortran_file
# Read in the csv file and put features into list of dict and list of class label
allElectronicsData = open(r'E:/DeepLearning/resources/AllElectronics.csv', 'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
featureList = []
lableList = []
for row in reader:
lableList.append(row[len(row)-1])
rowDict = {}
#不包括len(row)-1
for i in range(1,len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
vec = DictVectorizer()
dummX = vec.fit_transform(featureList).toarray()
print(str(dummX))
lb = preprocessing.LabelBinarizer()
dummY = lb.fit_transform(lableList)
print(str(dummY))
#entropy=>ID3
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummX, dummY)
print("clf:"+str(clf))
#可视化tree
with open("resultTree.dot",'w')as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(),out_file = f)
#对于新的数据怎样来查看它的分类
oneRowX = dummX[0,:]
print("oneRowX: "+str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
predictedY = clf.predict(newRowX)
print("predictedY: "+ str(predictedY))
这里的AllElectronics.csv,形式如下图所示:
今天早上好不容易将jdk、eclipse以及pydev装进linux,但是,但是,但是,想装numpy的时候,总是报错,发现是没有gcc,然后又去装gcc,真是醉了,到现在gcc还是没有装成功,再想想法子,实在不行过段时间去问大神

相关文章推荐
- Python 源代码中有中文的问题
- [转载]Python实现ASP+ACCESS注入的工具源代码
- 【转载】用source insight 看python源代码
- Python源代码文件的文本编码
- 决策树ID3和C4.5算法Python实现源码
- source insight中阅读python源代码
- source insight中阅读python源代码
- 利用Python统计源代码行数以及对源代码排版
- python源代码中需要加入中文注释
- 源代码,让.NET 平台上可以运行Python
- Python源代码中使用中文的方法
- 转:编译Python源代码
- 转:Python源代码编译成 pyc pyo
- Python入门的36个例子——00 源代码下载
- 发现Python的源代码中关于字符串fastsearch算法的一个笔误!
- Python源代码目录结构
- 调入源代码运行的python
- 关于python源代码中中文问题
- Python算法(含源代码下载)
- python 3.2 实现快速排序 源代码