循环神经网络教程 第四部分 用Python 和 Theano实现GRU/LSTM RNN
2016-12-31 17:32
926 查看
本教程的github代码
在本文中,我们将了解LSTM(长期短期内存)网络和GRU(门控循环单元)。 LSTM是1997年由Sepp Hochreiter和JürgenSchmidhuber首次提出的,是当下最广泛使用的NLP深度学习模型之一。 GRU,首次在2014年使用,是一个更简单的LSTM变体,它们有许多相同的属性。我们先从LSTM开始,后面看到GRU的不同的之处。
ifogctst=σ(xtUi+st−1Wi)=σ(xtUf+st−1Wf)=σ(xtUo+st−1Wo)= tanh(xtUg+st−1Wg)=ct−1∘f+g∘i=tanh(ct)∘o
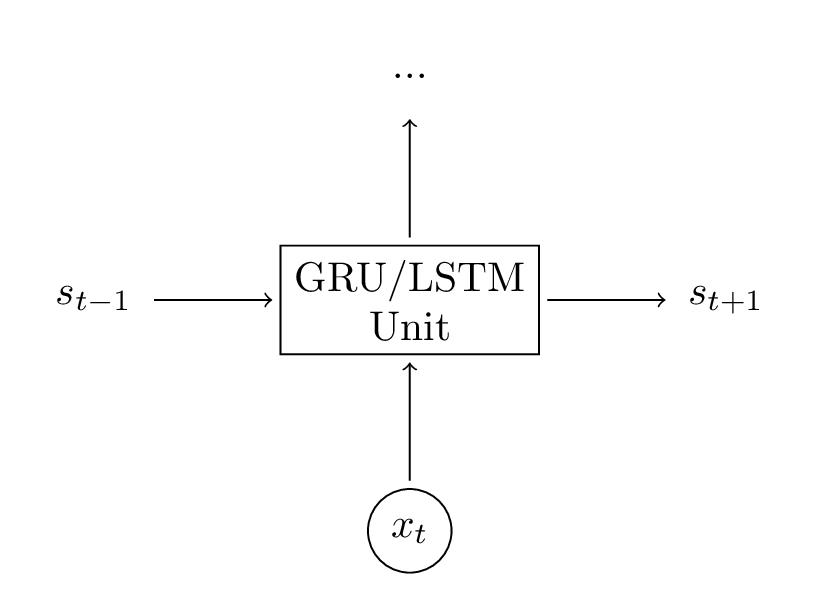
这些方程看起来相当复杂,但实际上并不那么难。首先,注意LSTM层只是另一种计算隐藏状态的方法。以前,我们计算隐藏状态为st=tanh(Uxt+Wst−1)。该单元的输入是当前时刻t的输入xt,以及前一个时刻的隐藏状态st−1。输出是一个新的隐藏状态st。LSTM单元做的事情是完全一样的,只是以不同的方式!这是理解整体的关键。你基本上可以将LSTM(和GRU)单元视为黑盒。给定当前输入和先前隐藏状态,它们以某种方式计算下一个隐藏状态。
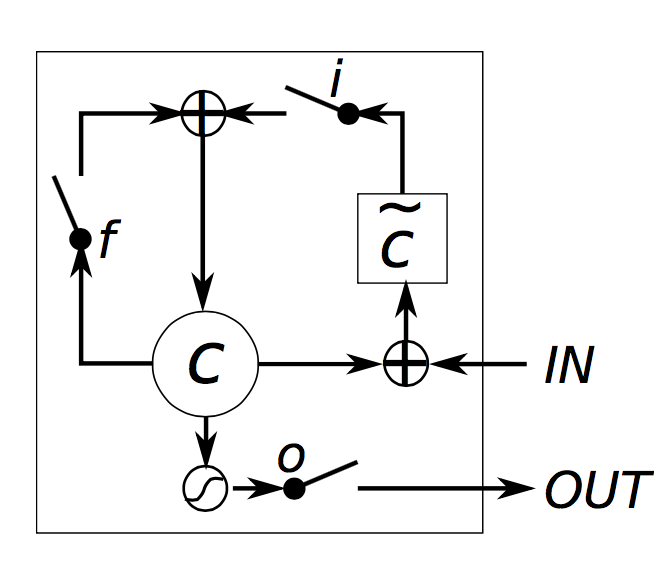
让我们试着对一个LSTM单元如何计算隐藏状态有一个直觉。Chris Olah拉有一个很好博客详细介绍了这一点,并避免重复他的工作,我只在这里简单的解释。我非常希望你阅读他的文章,以便有更深的见解和更好的视觉效果。但是,总结一下:
i,f,o分别称为输入门,遗忘门和输出门。注意,它们具有完全相同的方程,只是参数矩阵不同。被称作门是因为Sigmoid函数将这些向量的值压缩在0和1之间,通过elementwise方式乘以一个向量,这样可以限定你想让其“通过”多少(结果为0就是全部不通过,为1就是全部通过)。输入门定义了你想要为当前输入通过的新计算状态的多少。忘记门定义了你希望以前的状态通过的多少。最后,输出门定义了要暴露给外部网络(更深的层和下一个时刻)的内部状态的多少。所有的门的维度都是ds,即隐藏层的大小。
g是基于当前输入和先前隐藏状态计算的“候选”隐藏状态。它在vanilla RNN中有完全相同的方程,我们只是将参数U和W重命名为Ug和Wg。然而,我们不像在RNN中那样用g作为新的隐藏状态,而是使用上面的输入门来选择一些。
ct是神经单元的内部记忆。它由前一个记忆ct−1乘以遗忘门再加上新的隐藏状态g乘以输入门组合而成。因此,直观来讲,它是这样一个组合,即我们想要怎样结合先前的记忆和新的输入。我们可以选择完全忽略旧的记忆(遗忘门全为0)或者完全忽略新计算的状态(输入门全为0),但很可能我们想要在这两种极端之间的某种状态。
给定记忆ct,我们最后通过将其与输出门相乘来计算输出的隐藏状态st。不是所有的内部记忆都与网络中的其他单元使用的隐藏状态相关。
直观地,简单RNN可以被认为是LSTM的特殊情况。如果你固定输入门全为1,忘记门全为0(总是忘记前一个记忆),输出门全为1(暴露整个记忆),那么你几乎可以得到标准RNN。只有一个额外的tanh 压缩一点输出。门控机制允许LSTM显式地对长期依赖建模。通过学习门的参数,网络可以学习到它的记忆应该如何表现。
值得注意的是,在基本LSTM架构上存在几种变化。一个常见的问题是创建窥视孔连接,其可以让门不仅取决于先前的隐藏状态st−1,而且取决于先前的内部状态ct−1,同时也可以在门方程中添加附加项。LSTM还有更过的变体, LSTM:搜索空间Odyssey 可以评估不同的LSTM架构。
zrhst=σ(xtUz+st−1Wz)=σ(xtUr+st−1Wr)=tanh(xtUh+(st−1∘r)Wh)=(1−z)∘h+z∘st−1
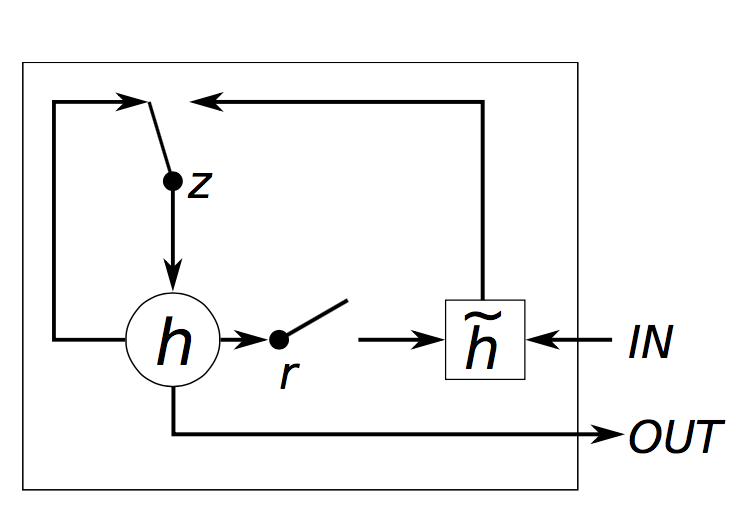
GRU具有两个门,复位门r和更新门z。直观地,复位门确定如何将新输入与先前记忆组合,更新门定义先前记忆中保留多少。如果我们将复位门设置为全1,将更新门设为全0,在此形成了普通RNN。使用门控机制学习长期依赖性的基本思想与LSTM中的相同,但有一些主要区别:
GRU具有两个门,LSTM具有三个门。
GRU不具有与内部记忆(ct)。它们没有LSTM中的输出门。
输入门和遗忘门通过更新门z耦合,复位门r被直接应用于先前的隐藏状态。因此,LSTM中的复位门的责任实际上分为r和z两者。
在计算输出时,我们不再用非线性函数。
我们的代码基于以前的Theano实现。记住,GRU(LSTM)层只是计算隐藏状态的另一种方式。所以我们真正需要做的是改变在前向传播函数中的隐藏状态计算。
在本文中,我们将了解LSTM(长期短期内存)网络和GRU(门控循环单元)。 LSTM是1997年由Sepp Hochreiter和JürgenSchmidhuber首次提出的,是当下最广泛使用的NLP深度学习模型之一。 GRU,首次在2014年使用,是一个更简单的LSTM变体,它们有许多相同的属性。我们先从LSTM开始,后面看到GRU的不同的之处。
LSTM 网络
在第3部分,我们了解了梯度消失问题是如何阻止标准RNN学习长期依赖的。 LSTM通过门控机制来抵消梯度消失。要理解这是什么意思,让我们看看LSTM如何计算隐藏状态st(∘表示elementwise 乘法):ifogctst=σ(xtUi+st−1Wi)=σ(xtUf+st−1Wf)=σ(xtUo+st−1Wo)= tanh(xtUg+st−1Wg)=ct−1∘f+g∘i=tanh(ct)∘o
这些方程看起来相当复杂,但实际上并不那么难。首先,注意LSTM层只是另一种计算隐藏状态的方法。以前,我们计算隐藏状态为st=tanh(Uxt+Wst−1)。该单元的输入是当前时刻t的输入xt,以及前一个时刻的隐藏状态st−1。输出是一个新的隐藏状态st。LSTM单元做的事情是完全一样的,只是以不同的方式!这是理解整体的关键。你基本上可以将LSTM(和GRU)单元视为黑盒。给定当前输入和先前隐藏状态,它们以某种方式计算下一个隐藏状态。
让我们试着对一个LSTM单元如何计算隐藏状态有一个直觉。Chris Olah拉有一个很好博客详细介绍了这一点,并避免重复他的工作,我只在这里简单的解释。我非常希望你阅读他的文章,以便有更深的见解和更好的视觉效果。但是,总结一下:
i,f,o分别称为输入门,遗忘门和输出门。注意,它们具有完全相同的方程,只是参数矩阵不同。被称作门是因为Sigmoid函数将这些向量的值压缩在0和1之间,通过elementwise方式乘以一个向量,这样可以限定你想让其“通过”多少(结果为0就是全部不通过,为1就是全部通过)。输入门定义了你想要为当前输入通过的新计算状态的多少。忘记门定义了你希望以前的状态通过的多少。最后,输出门定义了要暴露给外部网络(更深的层和下一个时刻)的内部状态的多少。所有的门的维度都是ds,即隐藏层的大小。
g是基于当前输入和先前隐藏状态计算的“候选”隐藏状态。它在vanilla RNN中有完全相同的方程,我们只是将参数U和W重命名为Ug和Wg。然而,我们不像在RNN中那样用g作为新的隐藏状态,而是使用上面的输入门来选择一些。
ct是神经单元的内部记忆。它由前一个记忆ct−1乘以遗忘门再加上新的隐藏状态g乘以输入门组合而成。因此,直观来讲,它是这样一个组合,即我们想要怎样结合先前的记忆和新的输入。我们可以选择完全忽略旧的记忆(遗忘门全为0)或者完全忽略新计算的状态(输入门全为0),但很可能我们想要在这两种极端之间的某种状态。
给定记忆ct,我们最后通过将其与输出门相乘来计算输出的隐藏状态st。不是所有的内部记忆都与网络中的其他单元使用的隐藏状态相关。
直观地,简单RNN可以被认为是LSTM的特殊情况。如果你固定输入门全为1,忘记门全为0(总是忘记前一个记忆),输出门全为1(暴露整个记忆),那么你几乎可以得到标准RNN。只有一个额外的tanh 压缩一点输出。门控机制允许LSTM显式地对长期依赖建模。通过学习门的参数,网络可以学习到它的记忆应该如何表现。
值得注意的是,在基本LSTM架构上存在几种变化。一个常见的问题是创建窥视孔连接,其可以让门不仅取决于先前的隐藏状态st−1,而且取决于先前的内部状态ct−1,同时也可以在门方程中添加附加项。LSTM还有更过的变体, LSTM:搜索空间Odyssey 可以评估不同的LSTM架构。
GRUS
GRU层背后的想法与LSTM层的思想非常相似,方程式也是如此。zrhst=σ(xtUz+st−1Wz)=σ(xtUr+st−1Wr)=tanh(xtUh+(st−1∘r)Wh)=(1−z)∘h+z∘st−1
GRU具有两个门,复位门r和更新门z。直观地,复位门确定如何将新输入与先前记忆组合,更新门定义先前记忆中保留多少。如果我们将复位门设置为全1,将更新门设为全0,在此形成了普通RNN。使用门控机制学习长期依赖性的基本思想与LSTM中的相同,但有一些主要区别:
GRU具有两个门,LSTM具有三个门。
GRU不具有与内部记忆(ct)。它们没有LSTM中的输出门。
输入门和遗忘门通过更新门z耦合,复位门r被直接应用于先前的隐藏状态。因此,LSTM中的复位门的责任实际上分为r和z两者。
在计算输出时,我们不再用非线性函数。
GRU VS LSTM
现在你已经知道了用来对抗梯度消失问题的两个模型,你可能想知道:使用哪一个? GRU是相当新的(2014年),他们之间的权衡尚未完全探索。根据序列建模的门控循环神经网络的经验评价和循环网络架构的实验探索的评价,没有一个明确的胜者。在许多任务中,两种架构的性能都不相上下,调整超参数(如层大小)可能比选择理想架构更重要。 GRU具有较少的参数(U和W较小),因此可以训练更快一点或需要更少的数据来推广。另一方面,如果你有足够的数据,LSTM的强大的表达力可能会有更好的结果。实验
让我们回到第二部分的语言模型的实现,在RNN中使用GRU单元。在这部分我选择GRU而不是LSTM(其他我也想更熟悉GRU)。他们的实现几乎是相同的,所以你应该很容易地修改代码从GRU变为LSTM通过改变方程。我们的代码基于以前的Theano实现。记住,GRU(LSTM)层只是计算隐藏状态的另一种方式。所以我们真正需要做的是改变在前向传播函数中的隐藏状态计算。

相关文章推荐
- 循环神经网络教程第四部分-用Python和Theano实现GRU/LSTM循环神经网络
- 循环神经网络教程4-用Python和Theano实现GRU/LSTM RNN, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano
- 循环神经网络教程第二部分-用python,numpy,theano实现一个RNN
- 循环神经网络教程-第二部分 用python numpy theano实现RNN
- 循环神经网络在Python 、Numpy和Theano中的实现
- 循环神经网络(RNN)中的LSTM和GRU模型的内部结构与意义
- (Unfinished)RNN-循环神经网络之LSTM和GRU-04介绍及推导
- 循环神经网络RNN以及LSTM的推导和实现
- TensorFlow人工智能引擎入门教程之九 RNN/LSTM循环神经网络长短期记忆网络使用
- 三种循环神经网络(RNN)算法的实现(From scratch、Theano、Keras)
- tensorflow 学习笔记12 循环神经网络RNN LSTM结构实现MNIST手写识别
- YJango的循环神经网络——实现LSTM YJango的循环神经网络——实现LSTM YJango YJango 7 个月前 介绍 描述最常用的RNN实现方式:Long-Short Term Me
- RNN-LSTM循环神经网络-03Tensorflow进阶实现
- RNN 教程-part4,用python实现LSTM/GRU
- 循环神经网络——实现LSTM/GRU
- [置顶] 【深度学习】RNN循环神经网络Python简单实现
- 三种循环神经网络(RNN)算法的实现(From scratch、Theano、Keras)
- 深度学习(08)_RNN-LSTM循环神经网络-03-Tensorflow进阶实现
- 深度学习(08)_RNN-LSTM循环神经网络-03-Tensorflow进阶实现
- RNN-LSTM循环神经网络-03Tensorflow进阶实现