看FEA如何演绎10大机器学习算法
2016-12-30 10:13
253 查看
谈到机器学习算法,网上充斥着无数枯燥或看不懂的资料,但通过图文解读,并以自己的学习经历来介绍的,恐怕只有James Le了。他在 KDnuggets 上发布了一篇文章,逐一介绍了十大常用的机器学习算法。
(以下内容由OpenFEA编译,未经许可不得转载)。
机器学习算法分为三类:有监督学习、无监督学习、增强学习。有监督学习需要标识数据(用于训练,即有正例又有负例),无监督学习不需要标识数据,增强学习介于两者之间(有部分标识数据)。因此,算法的分类主要还是有监督和无监督。
这两类算法,FEA全部可以实现,而且语法结构极为简洁。以下我们将分别介绍。
一、有监督的学习
(一)决策树
1、概念
决策树是一种树形结构,为人们提供决策依据,决策树可以用来回答yes和no问题,它通过树形结构将各种情况组合都表示出来,每个分支表示一次选择(选择yes还是no),直到所有选择都进行完毕,最终给出正确答案。

2、FEA实现方法
(二)朴素贝叶斯分类
1、概念
朴素贝叶斯分类是一族基于贝叶斯定理和特征之间的强独立性(朴素)的简单分类器。显著特点是方程式—— P(A|B) 是后验概率,P(B|A) 是似然概率,P(A) 是类的先验概率,P(B) 是预测的先验概率。
目前,该算法用于解决如下问题:
标记一个电子邮件为垃圾邮件或非垃圾邮件;
将新闻文章分为技术类、政治类或体育类;
检查一段文字表达积极的情绪,或消极的情绪?
用于人脸识别软件。


2、FEA实现方法
(三)普通的最小二乘回归
1、概念
如果你了解统计学,你以前可能听说过线性回归。最小二乘法是一种进行线性回归的方法。你可以把线性回归当作使用一条直线来拟合一系列的点的任务。有多种可能的方法来做到这一点,最小二乘的策略是这样的——你可以画一条线,然后对于每一个数据点,计算数据点和这条线的垂直距离,然后把它们加起来;拟合的线就是那个总和的距离尽可能小的线。

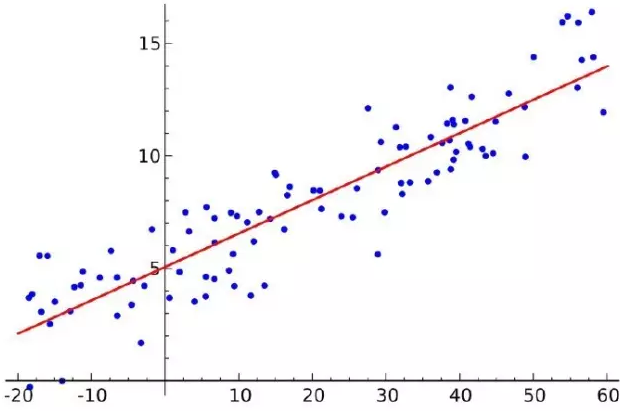
线性是指你用来拟合数据的模型,而最小二乘指的是你正在最小化的误差的度量。
2、FEA实现方法
(四)逻辑回归
1、概念
逻辑回归是一种强大的统计方法,它使用一个或者更多的解释变量对一个二项式结果建模。它通过使用logistic函数估计概率,这是累积logistic分布,来度量分类变量和一个或者更多的自变量之间的关系。

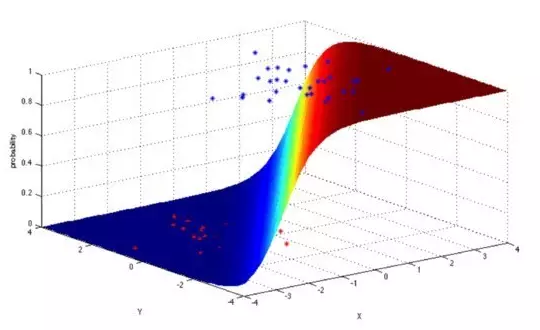
目前,该算法用于解决如下问题:
信用评分;
度量营销活动的成功率;
预测某一产品的收入;
在一个特定的日子里会发生地震吗?
2、FEA实现方法
(五)支持向量机(SVM)
1、概念
支持向量机是一个二分类算法。给出N维空间的一组二分类的点,支持向量机产生一个 N-1 维的超平面将这些点分成两组。假设你在一张纸上有一些线性可分的二分类的点,支持向量机将会找到一条直线,将这些点分成两类,并位于离所有这些点尽可能远的位置。

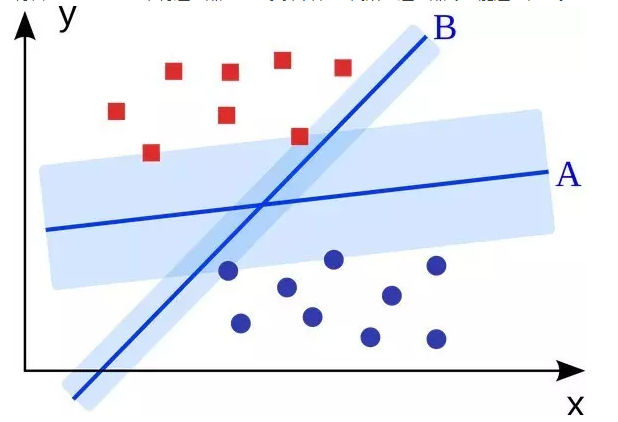
就规模而言,其中一些最主要的问题已经使用支持向量机解决了(通过适当的修改),如,广告显示,人类的剪接位点识别,基于图像的性别检测,大规模图像分类等等。
2、FEA实现方法
(六)集成方法
1、概念
集成方法是构建一组分类器,然后通过对预测结果进行加权投票来对新的数据点进行分类。原始的集成方法是贝叶斯平均,但最近的算法包括纠错输出编码,bagging, 和boosting。

那么集成方法是怎样工作的,为什么他们会优于单个的模型?
(1)他们拉平了输出偏差:如果你将具有民主党倾向的民意调查和具有共和党倾向的民意调查取平均,你将得到一个中和的没有倾向一方的结果。
(2)它们减小了方差:一堆模型的聚合结果和单一模型的结果相比具有更少的噪声。在金融领域,这被称为多元化——多只股票的混合投资要比一只股票变化更小。这就是为什么数据点越多你的模型会越好,而不是数据点越少越好。
(3)它
bb49
们不太可能产生过拟合:如果你有一个单独的没有过拟合的模型,你是用一种简单的方式(平均,加权平均,逻辑回归)将这些预测结果结合起来,然后就没有产生过拟合的空间了。
2、FEA实现方法
二、非监督学习
(一)聚类算法
1、概念
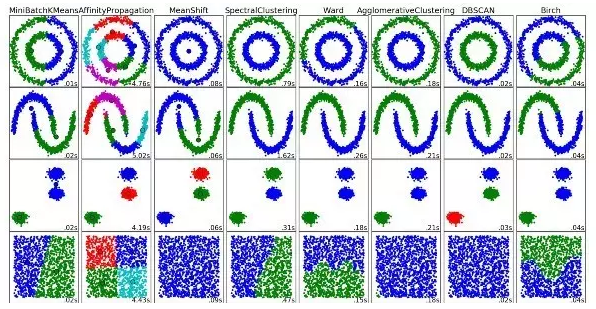
聚类是将一组对象进行分组,使得同一组(簇)内的对象相似性远大于不同组之间的相似性。
每一种聚类算法都不太一样,但常见的有:基于质心的算法、基于连通性的算法、基于密度的算法、概率聚类、降维、神经网络/深度学习等。

2、FEA实现方法
(二)主成分分析(PCA)
1、概念
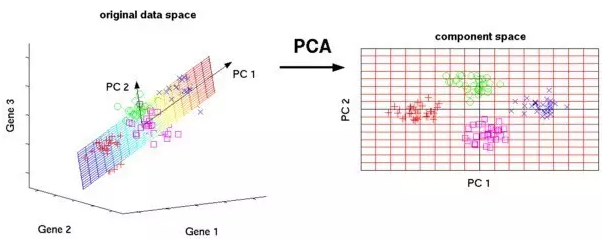
主成分分析是一个统计过程,它使用正交变换,将一组可能相关的变量的一组观测值变换成线性不相关的变量,这些变量称为主成分。
PCA的应用包括压缩,简化数据使它们更容易学习,可视化。注意,选择是否使用主成分分析,领域知识是非常重要的。当数据充满噪声时,主成分分析是不合适的(主成分分析的所有成分都有很高的方差)。

2、FEA实现方法
(三)奇异值分解(SVD)
1、概念
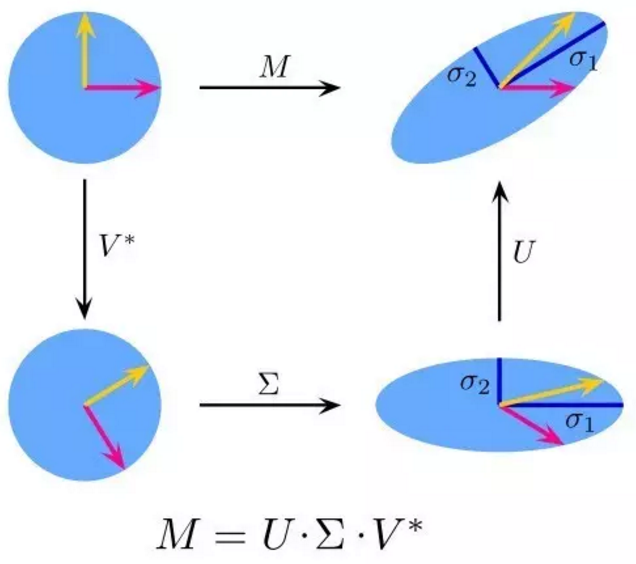
在线性代数中,SVD是分解一个实数的比较复杂的矩阵。对于一个给定的m*n的矩阵M,存在一个分解M = UΣV,这里U和V是酉矩阵,Σ是一个对角矩阵。
PCA 是 SVD 的一个简单应用,在计算机视觉中,第一个人脸识别算法,就运用了 PCA 和 SVD 算法。使用这两个算法可以将人脸表示为 “特征脸”线性组合,降维,然后通过简单的方法匹配人脸的身份;虽然现代的方法复杂得多,但许多仍然依赖于类似的技术。

2、FEA实现方法
(四)独立成分分析(ICA)
1、概念
独立成分分析是一种统计方法,用来揭示随机变量集测试,信号集中的隐藏因素。独立成分分析为观测到的多变量的集合定义生成模型,它通常作为大型的样本数据数据库。在这个模型中,数据变量被假定为与一些潜在的未知变量的线性混合,混合系统也不知道。潜在变量被假设为非高斯并且相互独立的,它们被称为所观察到的数据的独立成分。

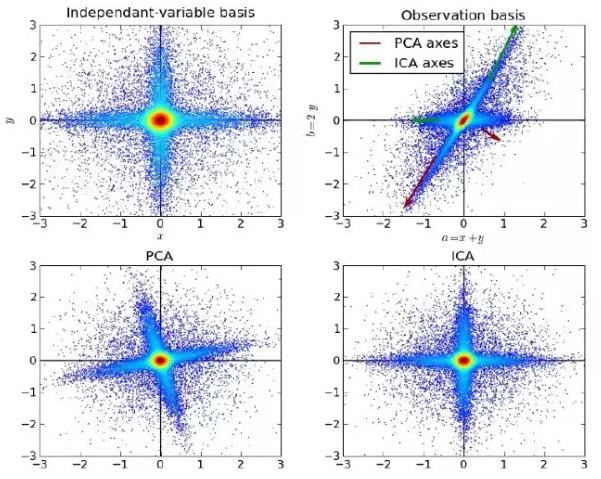
ICA 和 PCA 是相关的,但是它是一种更强大的技术,当那些经典的方法完全失效的时候,它能够从数据源中发现潜在的因素。它的应用包括数字图像,文档数据库,经济指标和心理测量。
2、FEA实现方法
除了上述10大算法外,FEA里还集成了KNN分类算法、lda线性判别分析、tsne二维可视化等算法,总之你搞机器学习,选FEA就对了。
(以下内容由OpenFEA编译,未经许可不得转载)。
机器学习算法分为三类:有监督学习、无监督学习、增强学习。有监督学习需要标识数据(用于训练,即有正例又有负例),无监督学习不需要标识数据,增强学习介于两者之间(有部分标识数据)。因此,算法的分类主要还是有监督和无监督。
这两类算法,FEA全部可以实现,而且语法结构极为简洁。以下我们将分别介绍。
一、有监督的学习
(一)决策树
1、概念
决策树是一种树形结构,为人们提供决策依据,决策树可以用来回答yes和no问题,它通过树形结构将各种情况组合都表示出来,每个分支表示一次选择(选择yes还是no),直到所有选择都进行完毕,最终给出正确答案。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 训练模型 | dt = @udf dfx,dfy by ML.dt |
| 预测 | df = @udf dfz by ML.predict with (dt@public) |
| 打分 | score = @udf dfx,dfy by ML.score with (dt@public) |
| 决策条件图形输出 | dot = @udf df0@sys by ML.dt2dot with (dt@public) |
1、概念
朴素贝叶斯分类是一族基于贝叶斯定理和特征之间的强独立性(朴素)的简单分类器。显著特点是方程式—— P(A|B) 是后验概率,P(B|A) 是似然概率,P(A) 是类的先验概率,P(B) 是预测的先验概率。
目前,该算法用于解决如下问题:
标记一个电子邮件为垃圾邮件或非垃圾邮件;
将新闻文章分为技术类、政治类或体育类;
检查一段文字表达积极的情绪,或消极的情绪?
用于人脸识别软件。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 训练模型 | gnb = @udf dfx,dfy by ML.gnb |
| 预测 | df = @udf dfz by ML.predict with (gnb@public) |
| 打分 | score = @udf dfx,dfy by ML.score with (gnb@public) |
1、概念
如果你了解统计学,你以前可能听说过线性回归。最小二乘法是一种进行线性回归的方法。你可以把线性回归当作使用一条直线来拟合一系列的点的任务。有多种可能的方法来做到这一点,最小二乘的策略是这样的——你可以画一条线,然后对于每一个数据点,计算数据点和这条线的垂直距离,然后把它们加起来;拟合的线就是那个总和的距离尽可能小的线。
线性是指你用来拟合数据的模型,而最小二乘指的是你正在最小化的误差的度量。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 训练模型 | model = @udf dfx,dfy by ML.LR |
| 预测 | df = @udf dfz by ML.predict with (model@public) |
| 打分 | score = @udf dfx,dfy by ML.score with (model@public) |
1、概念
逻辑回归是一种强大的统计方法,它使用一个或者更多的解释变量对一个二项式结果建模。它通过使用logistic函数估计概率,这是累积logistic分布,来度量分类变量和一个或者更多的自变量之间的关系。
目前,该算法用于解决如下问题:
信用评分;
度量营销活动的成功率;
预测某一产品的收入;
在一个特定的日子里会发生地震吗?
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 训练模型 | model = @udf dfx,dfy by ML.lr |
| 预测 | df = @udf dfz by ML.predict with (model@public) |
| 打分 | score = @udf dfx,dfy by ML.score with (model@public) |
1、概念
支持向量机是一个二分类算法。给出N维空间的一组二分类的点,支持向量机产生一个 N-1 维的超平面将这些点分成两组。假设你在一张纸上有一些线性可分的二分类的点,支持向量机将会找到一条直线,将这些点分成两类,并位于离所有这些点尽可能远的位置。
就规模而言,其中一些最主要的问题已经使用支持向量机解决了(通过适当的修改),如,广告显示,人类的剪接位点识别,基于图像的性别检测,大规模图像分类等等。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 训练模型 | model = @udf dfx,dfy by ML.svm |
| 预测 | df = @udf dfz by ML.predict with (model@public) |
| 打分 | score = @udf dfx,dfy by ML.score with (model@public) |
| SVM回归 | model2 = @udf dfx,dfy by ML.SVR |
1、概念
集成方法是构建一组分类器,然后通过对预测结果进行加权投票来对新的数据点进行分类。原始的集成方法是贝叶斯平均,但最近的算法包括纠错输出编码,bagging, 和boosting。
那么集成方法是怎样工作的,为什么他们会优于单个的模型?
(1)他们拉平了输出偏差:如果你将具有民主党倾向的民意调查和具有共和党倾向的民意调查取平均,你将得到一个中和的没有倾向一方的结果。
(2)它们减小了方差:一堆模型的聚合结果和单一模型的结果相比具有更少的噪声。在金融领域,这被称为多元化——多只股票的混合投资要比一只股票变化更小。这就是为什么数据点越多你的模型会越好,而不是数据点越少越好。
(3)它
bb49
们不太可能产生过拟合:如果你有一个单独的没有过拟合的模型,你是用一种简单的方式(平均,加权平均,逻辑回归)将这些预测结果结合起来,然后就没有产生过拟合的空间了。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 训练模型 | model = @udf dfx,dfy by ML.gbdt |
| 预测 | df = @udf dfz by ML.predict with (model@public) |
| 打分 | score = @udf dfx,dfy by ML.score with (model@public) |
| 弱分类 | model2 = @udf dfx,dfy by ML.adaBoost |
| 随机森林 | model2 = @udf dfx,dfy by ML.rf |
(一)聚类算法
1、概念
聚类是将一组对象进行分组,使得同一组(簇)内的对象相似性远大于不同组之间的相似性。
每一种聚类算法都不太一样,但常见的有:基于质心的算法、基于连通性的算法、基于密度的算法、概率聚类、降维、神经网络/深度学习等。
2、FEA实现方法
| 聚类 | 分成4类,对应的FEA原语 |
| kmeans | k = @udf df by ML.kmeans with 4 |
| 均值漂移聚类 | k = @udf df by ML.means with 4 |
| 谱聚类 | k = @udf df by ML.sc with 4 |
| 密度聚类 | k = @udf df by ML.db |
| 传播聚类 | k = @udf df by ML.ap |
| 综合层次聚类 | k = @udf df by ML.brich |
1、概念
主成分分析是一个统计过程,它使用正交变换,将一组可能相关的变量的一组观测值变换成线性不相关的变量,这些变量称为主成分。
PCA的应用包括压缩,简化数据使它们更容易学习,可视化。注意,选择是否使用主成分分析,领域知识是非常重要的。当数据充满噪声时,主成分分析是不合适的(主成分分析的所有成分都有很高的方差)。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 降维 | df2 = @udf df by ML.pca with (2) |
| 模型数据 | cmpts = @udf df by ML.pca_cmpts |
| 各变量占比 | ratio = @udf df by ML.pca_ratio |
1、概念
在线性代数中,SVD是分解一个实数的比较复杂的矩阵。对于一个给定的m*n的矩阵M,存在一个分解M = UΣV,这里U和V是酉矩阵,Σ是一个对角矩阵。
PCA 是 SVD 的一个简单应用,在计算机视觉中,第一个人脸识别算法,就运用了 PCA 和 SVD 算法。使用这两个算法可以将人脸表示为 “特征脸”线性组合,降维,然后通过简单的方法匹配人脸的身份;虽然现代的方法复杂得多,但许多仍然依赖于类似的技术。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 降维 | df2 = @udf df by ML.svd with (2) |
| 模型数据 | cmpts = @udf df by ML.svd_cmpts |
| 各变量占比 | ratio = @udf df by ML.svd_ratio |
1、概念
独立成分分析是一种统计方法,用来揭示随机变量集测试,信号集中的隐藏因素。独立成分分析为观测到的多变量的集合定义生成模型,它通常作为大型的样本数据数据库。在这个模型中,数据变量被假定为与一些潜在的未知变量的线性混合,混合系统也不知道。潜在变量被假设为非高斯并且相互独立的,它们被称为所观察到的数据的独立成分。
ICA 和 PCA 是相关的,但是它是一种更强大的技术,当那些经典的方法完全失效的时候,它能够从数据源中发现潜在的因素。它的应用包括数字图像,文档数据库,经济指标和心理测量。
2、FEA实现方法
| 功能 | 对应的FEA原语,默认public工作区 |
| 降维 | df2 = @udf df by ML.ica with (2) |
| 模型数据 | cmpts = @udf df by ML.ica_cmpts |

相关文章推荐
- 机器学习实战之k-近邻算法(4)--- 如何归一化数据
- 机器学习10大经典算法
- 机器学习10大经典算法
- 机器学习实战之k-近邻算法(3)---如何可视化数据
- 机器学习10大经典算法
- 看FEA如何演绎10大机器学习算法
- 机器学习10大经典算法
- 机器学习10大经典算法
- 学习机器学习之如何根据需求选择一种算法
- 机器学习实战学习笔记 一 k-近邻算法
- 解读御坂美琴みさか的菱形打印程序——谈如何学习算法
- 如何学习算法
- 机器学习_算法_神经网络_BP
- 如何将机器学习应用到测试领域
- 从如何解决问题到如何学习算法
- 由快速排序引申而来--如何学习算法
- 机器学习经典算法4-logistic回归
- 由快速排序引申而来--如何学习算法
- 与算法无关的机器学习方法之主动学习
- 到底该如何学习算法?