学习小记 - Python爬虫 (3) 利用Python爬取wanimal所有图片
2016-12-30 00:07
796 查看
这是辆车…
本次调用urlretrieve()方法实现对媒体文件的本地存储,其他和之前类似。
由于Ubutun下不能全局翻墙(我不会><),本次代码在windows下运行。
代码跑起来咯~!
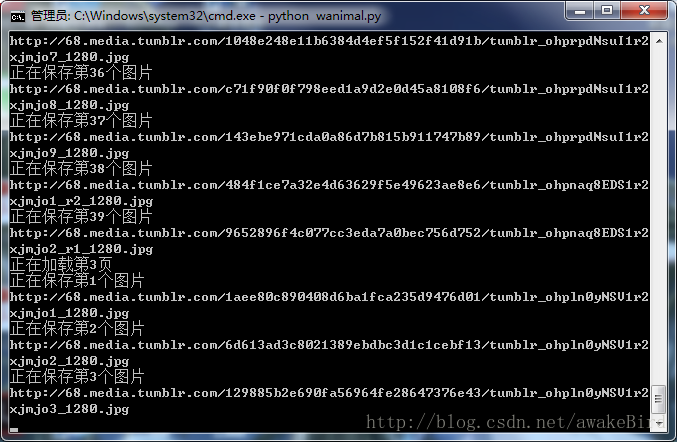
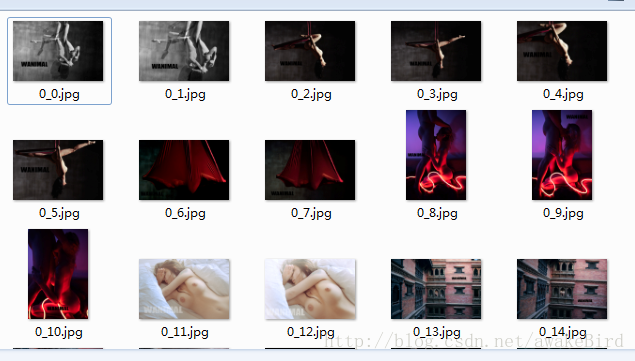
本次调用urlretrieve()方法实现对媒体文件的本地存储,其他和之前类似。
from urllib.request import urlopen, urlretrieve
from bs4 import BeautifulSoup
from urllib.error import URLError, HTTPError
import requests
class Wanimal:
def __init__(self, page):
self.page = page
self.imgs = []
def getPage(self, page):
try:
html = urlopen("http://wanimal1983.org/page/"+str(page))
bsobj = BeautifulSoup(html, "html.parser")
return bsobj
except (URLError, HTTPError) as e:
print (e)
return None
def getImages(self, page):
print ("正在加载第%d页" % page)
bsobj = self.getPage(page)
imgTags = bsobj.findAll("div", {"class": "photo-sets"})
self.imgs = []
for imgTag in imgTags:
for img in imgTag.findAll("img"):
self.imgs.append(img)
def download(self):
for page in range(self.page):
self.getImages(page+1)
for i in range(len(self.imgs)):
print ("正在保存第%d个图片" % (i+1))
path = str(page)+'_'+str(i)+".jpg"
print (self.imgs[i].attrs["src"])
urlretrieve(self.imgs[i].attrs["src"], "wanimal/"+path)
w = Wanimal(100000)
print (w.imgs)
w.download()由于Ubutun下不能全局翻墙(我不会><),本次代码在windows下运行。
代码跑起来咯~!

相关文章推荐
- python 爬虫学习<将某一页的所有图片下载下来>
- Python爬虫框架Scrapy 学习笔记 10.3 -------【实战】 抓取天猫某网店所有宝贝详情
- 利用Python和goagent代理爬取1024帖子所有图片
- python爬虫:下载百度贴吧图片学习笔记
- python学习笔记(8)--爬虫下载占位图片
- 学习小记 - Python爬虫 (1) 静态网页糗事百科的爬取
- python爬虫学习(1)__抓取煎蛋图片
- python爬虫:下载百度贴吧图片(多页)学习笔记
- 【Python开发】【神经网络与深度学习】网络爬虫之图片自动下载器
- python学习(4):python爬虫入门案例-爬取图片
- python学习:urllib库学习:制作简易爬虫下载图片
- python网络爬虫学习(六)利用Pyspider+Phantomjs爬取淘宝模特图片
- Python Requests爬虫——获取一个收藏夹下所有答案的图片
- 利用python网络爬虫批量下载花瓣中个人主页中收藏的所有图片
- Python爬虫框架Scrapy 学习笔记 10.1 -------【实战】 抓取天猫某网店所有宝贝详情
- [python 爬虫学习]利用cookie模拟网站登录
- Python爬虫学习笔记一:简单网页图片抓取
- Python爬虫学习笔记二:百度贴吧网页图片抓取
- 学习小记 - Python爬虫 (2) 爬虫闯关系列
- 爬虫 scrapy 框架学习 2. Scrapy框架业务逻辑的理解 + 爬虫案例 下载指定网站所有图片