智慧中国杯百万大奖赛解读 |今天你打怪了吗(四)
2016-12-30 00:00
337 查看
不知道看完前三篇的人里面,有没人真正操作过一遍,然后去智慧中国杯的官网提交结果的。如果有的话,说明你是FEA的真粉丝,我们应该支持你,同时你肯定也很沮丧,因为提交的结果不知道排到哪里去了(150名以内找不到)。
不要沮丧,不要灰心,前面三篇只是开胃菜,真正的大餐在这里,看完这篇包你能进前50强。
什么才前50?。。。
不错了,官方开源的一份代码你照做的话,基准得分是0.023,现在大概是100名开外。看完本篇应该得分是0.0259x的样子,最后的提高还是有难度的,需要智力和体力的结合,只要你每天坚持打怪升级(提交结果),你的成绩一定会提升的。
榜单刷新的很快的,不进则退哦!
好了,废话不多说,我们正式开始机器学习的优化之旅。
第一部分、优化路径
1、概述
结合本人的经验,绘制了一个大致做机器学习工程的方法,如下图:

接到一个项目或任务后,结合项目的需求和背景,对数据进行有针对性的探索,然后再评估数据样本是否不平衡,需要对数据重采样等处理,并能给出主要的维度信息出来。
接下来就可以精心于初步的算法选择和参数的确定,结合项目需求和自身对算法的了解程度来进行选择,没有唯一答案,一定要善于突破。
然后就可以进行训练评估,结果还基本满意就可以进入深入分析数据不断增加和变换维度上来,维度的选择对模型的成功起至关重要的作用。
当你实在没有新的维度增加时,可以考虑通过微调参数,看能不能提高模型的准确率,这时也一定要注意过拟合的问题,以免实验结果很好,一旦进入实际应用就不行的怪圈当中,最后固话模型。
还是那句话,这是脑力和体力的结合,坚持每天打怪升级,你可以的!
2、重采样
因为样本数据的不均衡性,势必会导致分类结果的倾斜,导致准确率虚高(比如都预测资助为0)。本次的样本中,得到资助的只占15%左右,如果不对数据进行过采样的话,势必影响训练的结果。
这时我们可以使用重采样的方式来平衡训练数据,重采样又分为两种:
过采样就是重复增加一部分小分类的样本数据;
欠采样就是删除一部分大分类的样本数据。
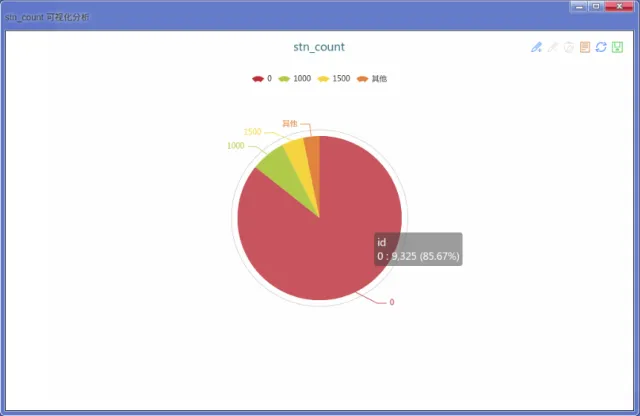
我们的样本总数不多,所以通过过采样的方式,在训练数据中增加小分类的数据,来达到均衡的目的。
#过采样
t1 = filter a by (money==1000)
t15 = filter a by (money==1500)
t20 = filter a by (money==2000)
#增加5倍
a = @udf a,t1 by udf0.append_df with 5
#增加8倍
a = @udf a,t15 by udf0.append_df with 8
#增加10倍
a = @udf a,t20 by udf0.append_df with 10
原始的训练数据分布

过采样后的数据分布

这个5,8,10是经验值,到最后的时候都可以进行微调。
3、算法选择
算法的选择对于初学者来说是一个障碍,因为算法实在太多了,想把每一个算法的每一个细节都吃透,往往是徒劳的。这就是好多人的一个疑惑,我要搞机器学习搞人工智能,是不是先要去念个博士?都说股票市场是经济的晴雨表,说明股票和经济是有很大关系的,那你有没听说哪个人为了炒股,先去读个经济学博士的。
不要踌躇千里不敢迈出一步,机器学习重在实干,对算法不全了解不要紧,你可以选择一到两个重点突破,其他的知道就行,真到用时再去深钻。
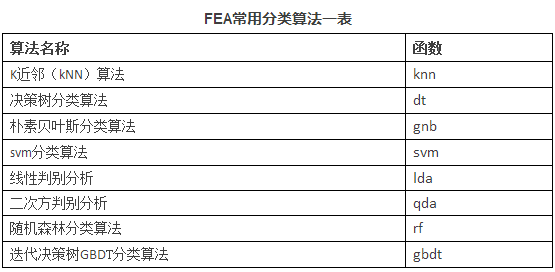
而真正在工程实践中,可以选择复合型的算法,如GBDT和随机森林,它们都是有多棵决策树组成,对结果进行多次迭代,效果更好。在多次大赛中都看到他们的身影。我还是给大家推荐几个算法,对于初学者可以先看决策树,这个算法比较简单且是个白盒算法,就是你建好模型后,可以将整个决策树图形展示出来,找到每个分支的边界,特别适合那些喜欢较真的同学。^V^
4、参数优化
参数优化是个大命题,这里同样以GBDT和随机森林为最常用的有:n_estimators(子模型数量),random_state(随机对象)等。子模型数量越大精度会越高,但有可能造成过拟合,预测时反而效果不好;随机对象对预测结果影响很小,根据自己的喜好先设置一个。
初步选择如下:
#GBDT
model = @udf a,b by ML.gbdt with (n_estimators=200,random_state=2016)
#随机森林
model = @udf a,b by ML.rf with (n_estimators=500,random_state=2016)
5、维度选择
经过前面几步之后,剩下最重要的就是基于业务的理解,做出好的维度特征数据来,这是一个模型能够成果的关键。
上篇文章中,只使用了消费数据的维度,并没有成绩,图书馆,教室等维度,这些信息对于提升准确率也是有用的。
成绩的维度
#装载成绩数据
score = load csv by $train_path/score_train.$efile with (header=-1)
rename score as (0:"id",1:"college",2:"order")
score1 = load csv by $test_path/score_test.$efile with (header=-1)
rename score1 as (0:"id",1:"college",2:"order")
score = union score,score1
#学院排名最大
sgt = group score by college
sgt_max = agg sgt.order by max_order:max
sgt_max = @udf sgt_max by udf0.df_reset_index
score2 = @udf score,sgt_max by udf0.df_ljoin with (college,college)
#排名比值
score2 = add real by (score2['order'] / score2['max_order'])
图书馆进出的维度
#装载图书馆进出数据
lt = load csv by $train_path/library_train.$efile with (header=-1)
lt1 := load csv by $test_path/library_test.$efile with (header=-1)
lt = union lt,lt1
rename lt as (0:"id",1:"gate",2:"time")
#以人为单位,计算图书进出的维度
lt_count = @udf lt by udf0.df_agg_count with (id)
lt_count = @udf lt_count by udf0.df_reset_index
rename lt_count as ("index":"id","count":"lt_count")
宿舍进出的维度
#宿舍进出数据
dt = load csv by $train_path/dorm_train.$efile with (header=-1)
dt1 := load csv by $test_path/dorm_test.$efile with (header=-1)
dt = union dt,dt1
dt = rename dt as (0:"id",1:"time",2:"isout")
#以人为单位,计算宿舍进出的维度
dt_io_count = @udf dt by udf0.df_agg_count with (id)
dt_io_count = @udf dt_io_count by udf0.df_reset_index
rename dt_io_count as ("index":"id","count":"io_count")
dt_in = filter dt by (isout==0)
dt_in_count = @udf dt_in by udf0.df_agg_count with (id)
dt_in_count = @udf dt_in_count by udf0.df_reset_index
rename dt_in_count as ("index":"id","count":"in_count")
dt_count = join dt_io_count,dt_in_count by id,id
第二部分、注意事项
在整个维度计算和选择的过程中,我也发现了几个好玩的事情,给大家介绍一下,避免大家重新跳到坑里面去。
1、学生ID
在刚做这个系列的时候,我就一直和官方提供的开源程序做对比,明明我的维度比之前要多要好,但在成绩上就是没有超过官方的。最后经过我仔细的排查才发现少了一个我一直认为和这个预测没有关系的学生ID。
这个ID是从0开始,显然是经过脱敏处理的,但按照什么样的规则我们并不清楚,但不要少了这个维度,他可能包含了某方面的信息,加上这个维度后我就彻底超过了官方提供的基准成绩。
2、成绩数据要训练和测试集合并后再分拆
本次竞赛的数据直接分成了训练和测试数据,如果没有交集是没必要合并后才分拆的。但成绩数据只有排名,如果不合并,你根本不知道这个排名的意义,所以要合并起来,找出最大值,计算每个人的排名比值(自身排名/最大排名),然后再根据预测人数据进行分拆。这里面包括了学院ID等信息,都对预测有影响。
3、不是所有维度都是积极的
我讲了维度很重要,维度的质量和多少都很关键,一般意义上来讲有效维度越多越好,但维度并不是都是积极向上的,有些维度的引入反而会带来消极作用,影响你的成绩。
在第二篇的《学霸去哪了》文中我分析了深夜出入宿舍的维度,我就没多想,直接加入进行训练了,结果反而导致成绩大幅下降。看来深夜出入宿舍的维度和资助关系不大,至少和本次的数据关系不大。
所以大家在选择维度时,也要精心考虑设计过。
第三部分、小结
通过本文的详细解读,精准教育资助的这个话题就告一段落了,下一篇将开启金融用户贷款风险预测的解读。
喜欢这个系列的朋友不要忘记给我点赞哦,你的支持是我更新的最大动力。
哦!再次重申一下,需要完整代码的朋友请关注我们的微信公众号openfea,发送关键字“fea”,将微信自动回复的文章“OpenFEA一次学个够,全程 or 周末由您选”转发到您的朋友圈后,将分享成功的截图发送至邮箱fea@hzhz.co即可获得,先到先得哦!
往期精彩文章:
智慧中国杯算法赛解读 | 精准资助数据探索(一)
智慧中国杯百万大奖赛解读 | 学霸去哪了(二)
智慧中国杯百万大奖赛解读 | 精准资助机器学习(三)
不要沮丧,不要灰心,前面三篇只是开胃菜,真正的大餐在这里,看完这篇包你能进前50强。
什么才前50?。。。
不错了,官方开源的一份代码你照做的话,基准得分是0.023,现在大概是100名开外。看完本篇应该得分是0.0259x的样子,最后的提高还是有难度的,需要智力和体力的结合,只要你每天坚持打怪升级(提交结果),你的成绩一定会提升的。
榜单刷新的很快的,不进则退哦!
好了,废话不多说,我们正式开始机器学习的优化之旅。
第一部分、优化路径
1、概述
结合本人的经验,绘制了一个大致做机器学习工程的方法,如下图:
接到一个项目或任务后,结合项目的需求和背景,对数据进行有针对性的探索,然后再评估数据样本是否不平衡,需要对数据重采样等处理,并能给出主要的维度信息出来。
接下来就可以精心于初步的算法选择和参数的确定,结合项目需求和自身对算法的了解程度来进行选择,没有唯一答案,一定要善于突破。
然后就可以进行训练评估,结果还基本满意就可以进入深入分析数据不断增加和变换维度上来,维度的选择对模型的成功起至关重要的作用。
当你实在没有新的维度增加时,可以考虑通过微调参数,看能不能提高模型的准确率,这时也一定要注意过拟合的问题,以免实验结果很好,一旦进入实际应用就不行的怪圈当中,最后固话模型。
还是那句话,这是脑力和体力的结合,坚持每天打怪升级,你可以的!
2、重采样
因为样本数据的不均衡性,势必会导致分类结果的倾斜,导致准确率虚高(比如都预测资助为0)。本次的样本中,得到资助的只占15%左右,如果不对数据进行过采样的话,势必影响训练的结果。
这时我们可以使用重采样的方式来平衡训练数据,重采样又分为两种:
过采样就是重复增加一部分小分类的样本数据;
欠采样就是删除一部分大分类的样本数据。
我们的样本总数不多,所以通过过采样的方式,在训练数据中增加小分类的数据,来达到均衡的目的。
#过采样
t1 = filter a by (money==1000)
t15 = filter a by (money==1500)
t20 = filter a by (money==2000)
#增加5倍
a = @udf a,t1 by udf0.append_df with 5
#增加8倍
a = @udf a,t15 by udf0.append_df with 8
#增加10倍
a = @udf a,t20 by udf0.append_df with 10
原始的训练数据分布
过采样后的数据分布
这个5,8,10是经验值,到最后的时候都可以进行微调。
3、算法选择
算法的选择对于初学者来说是一个障碍,因为算法实在太多了,想把每一个算法的每一个细节都吃透,往往是徒劳的。这就是好多人的一个疑惑,我要搞机器学习搞人工智能,是不是先要去念个博士?都说股票市场是经济的晴雨表,说明股票和经济是有很大关系的,那你有没听说哪个人为了炒股,先去读个经济学博士的。
不要踌躇千里不敢迈出一步,机器学习重在实干,对算法不全了解不要紧,你可以选择一到两个重点突破,其他的知道就行,真到用时再去深钻。
而真正在工程实践中,可以选择复合型的算法,如GBDT和随机森林,它们都是有多棵决策树组成,对结果进行多次迭代,效果更好。在多次大赛中都看到他们的身影。我还是给大家推荐几个算法,对于初学者可以先看决策树,这个算法比较简单且是个白盒算法,就是你建好模型后,可以将整个决策树图形展示出来,找到每个分支的边界,特别适合那些喜欢较真的同学。^V^
4、参数优化
参数优化是个大命题,这里同样以GBDT和随机森林为最常用的有:n_estimators(子模型数量),random_state(随机对象)等。子模型数量越大精度会越高,但有可能造成过拟合,预测时反而效果不好;随机对象对预测结果影响很小,根据自己的喜好先设置一个。
初步选择如下:
#GBDT
model = @udf a,b by ML.gbdt with (n_estimators=200,random_state=2016)
#随机森林
model = @udf a,b by ML.rf with (n_estimators=500,random_state=2016)
5、维度选择
经过前面几步之后,剩下最重要的就是基于业务的理解,做出好的维度特征数据来,这是一个模型能够成果的关键。
上篇文章中,只使用了消费数据的维度,并没有成绩,图书馆,教室等维度,这些信息对于提升准确率也是有用的。
成绩的维度
#装载成绩数据
score = load csv by $train_path/score_train.$efile with (header=-1)
rename score as (0:"id",1:"college",2:"order")
score1 = load csv by $test_path/score_test.$efile with (header=-1)
rename score1 as (0:"id",1:"college",2:"order")
score = union score,score1
#学院排名最大
sgt = group score by college
sgt_max = agg sgt.order by max_order:max
sgt_max = @udf sgt_max by udf0.df_reset_index
score2 = @udf score,sgt_max by udf0.df_ljoin with (college,college)
#排名比值
score2 = add real by (score2['order'] / score2['max_order'])
图书馆进出的维度
#装载图书馆进出数据
lt = load csv by $train_path/library_train.$efile with (header=-1)
lt1 := load csv by $test_path/library_test.$efile with (header=-1)
lt = union lt,lt1
rename lt as (0:"id",1:"gate",2:"time")
#以人为单位,计算图书进出的维度
lt_count = @udf lt by udf0.df_agg_count with (id)
lt_count = @udf lt_count by udf0.df_reset_index
rename lt_count as ("index":"id","count":"lt_count")
宿舍进出的维度
#宿舍进出数据
dt = load csv by $train_path/dorm_train.$efile with (header=-1)
dt1 := load csv by $test_path/dorm_test.$efile with (header=-1)
dt = union dt,dt1
dt = rename dt as (0:"id",1:"time",2:"isout")
#以人为单位,计算宿舍进出的维度
dt_io_count = @udf dt by udf0.df_agg_count with (id)
dt_io_count = @udf dt_io_count by udf0.df_reset_index
rename dt_io_count as ("index":"id","count":"io_count")
dt_in = filter dt by (isout==0)
dt_in_count = @udf dt_in by udf0.df_agg_count with (id)
dt_in_count = @udf dt_in_count by udf0.df_reset_index
rename dt_in_count as ("index":"id","count":"in_count")
dt_count = join dt_io_count,dt_in_count by id,id
第二部分、注意事项
在整个维度计算和选择的过程中,我也发现了几个好玩的事情,给大家介绍一下,避免大家重新跳到坑里面去。
1、学生ID
在刚做这个系列的时候,我就一直和官方提供的开源程序做对比,明明我的维度比之前要多要好,但在成绩上就是没有超过官方的。最后经过我仔细的排查才发现少了一个我一直认为和这个预测没有关系的学生ID。
这个ID是从0开始,显然是经过脱敏处理的,但按照什么样的规则我们并不清楚,但不要少了这个维度,他可能包含了某方面的信息,加上这个维度后我就彻底超过了官方提供的基准成绩。
2、成绩数据要训练和测试集合并后再分拆
本次竞赛的数据直接分成了训练和测试数据,如果没有交集是没必要合并后才分拆的。但成绩数据只有排名,如果不合并,你根本不知道这个排名的意义,所以要合并起来,找出最大值,计算每个人的排名比值(自身排名/最大排名),然后再根据预测人数据进行分拆。这里面包括了学院ID等信息,都对预测有影响。
3、不是所有维度都是积极的
我讲了维度很重要,维度的质量和多少都很关键,一般意义上来讲有效维度越多越好,但维度并不是都是积极向上的,有些维度的引入反而会带来消极作用,影响你的成绩。
在第二篇的《学霸去哪了》文中我分析了深夜出入宿舍的维度,我就没多想,直接加入进行训练了,结果反而导致成绩大幅下降。看来深夜出入宿舍的维度和资助关系不大,至少和本次的数据关系不大。
所以大家在选择维度时,也要精心考虑设计过。
第三部分、小结
通过本文的详细解读,精准教育资助的这个话题就告一段落了,下一篇将开启金融用户贷款风险预测的解读。
喜欢这个系列的朋友不要忘记给我点赞哦,你的支持是我更新的最大动力。
哦!再次重申一下,需要完整代码的朋友请关注我们的微信公众号openfea,发送关键字“fea”,将微信自动回复的文章“OpenFEA一次学个够,全程 or 周末由您选”转发到您的朋友圈后,将分享成功的截图发送至邮箱fea@hzhz.co即可获得,先到先得哦!
往期精彩文章:
智慧中国杯算法赛解读 | 精准资助数据探索(一)
智慧中国杯百万大奖赛解读 | 学霸去哪了(二)
智慧中国杯百万大奖赛解读 | 精准资助机器学习(三)

相关文章推荐
- 智慧中国杯百万大奖赛解读 |今天你打怪了吗(四)
- 智慧中国杯百万大奖赛解读 | 精准资助机器学习(三)
- 智慧中国杯百万大奖赛解读 | 精准资助机器学习(三)
- Follow me!百万奖金由你拿 | 今天你打怪了吗(四)
- IDC分析师解读IT服务商如何抓住中国“智慧制造”商机
- 智慧中国杯算法赛解读 | 精准资助数据探索(一)
- 智慧中国杯算法赛解读 | 精准资助数据探索(一)
- Follow me!百万奖金由你拿 | 今天你打怪了吗(四)
- 中国智慧VS西方智慧-看中国IT风云与IT产业怪状
- 【认知计算】IBM报告解读《认知中国》— 拉近人工智能未来与现实的距离,中国企业争当认知创新者
- 网络分流器|美国分分钟断中国网络?谣言,看权威专家解读
- 今天开书 十句话说尽中国历史……
- 真理在大炮的射程以内-乌克兰的今天就是中国的昨天
- 《专注——解读中国隐形冠军企业》读书笔记
- 给中国学生的第六封信——选择的智慧
- 解读谷歌中国低俗门,谷歌被陷害证据不足?
- 马云:今天的中国是最佳经商时代 全世界无可比
- 十分钟让你了解今天中国经济真相(ZT)