[置顶] Zookeeper服务框架之介绍篇
2016-12-27 14:36
239 查看
Zookeeper服务框架之介绍篇
Zookeeper是一种分布式服务框架,是apache hadoop的子项目,完全开源存在,它的诞生主要用来处理分布式环境中数据管理问题,比如:分布式应用程序配置、集群管理、状态同步服务及命名服务等。这里,我们以3.4.8版本为例展开介绍,其最新的版本下载可以从地址:
http://hadoop.apache.org/zookeeper/ 中获取,并以java项目为例进行分析和使用Zookeeper,和以往文章一样,都是以安装配置开始!
l 安装配置
l 组件特点
l 入门使用
一、安装配置
Zookeeper的安装十分简单,我们只需要从如下地址下载并解压:
http://mirrors.cnnic.cn/apache/zookeeper/
然后,Zookeeper的安装配置,可以从单机和集群环境介绍:
1、配置
在开始服务前,有几个基本配置要准备下,Zookeeper的配置文件在conf文件夹下,默认名为zoo_sample.cfg,也是Zookeeper默认加载的配置文件,这里我们把它改个名字:
$sudo mv zoo_sample.cfg zoo.cfg
另外,当前版本的Zookeeper的conf下,还有log4j.properties和configuration.xsl文件,在后续文章中会陆续介绍它们的作用,那么接下来就先介绍zoo.cfg配置和使用情况。
2、单机环境
在单机环境下,满足服务基本需求的zoo.cfg基本内容如下:
tickTime=2000
dataDir=/zookeeper/zookeeper/build
clientPort=2181
参数说明:
tickTime:Zookeeper服务器间或客户端与服务器之间维持心跳的间隔时间,即每隔tickTime时间,就发送一次心跳检测。
dataDir:Zookeeper服务保存数据的位置,默认也是其存放写入数据的日志文件的位置。
clientPort:Zookeeper会监听这个端口,来知道客户端链接到它,也就是客户端链接Zookeeper服务器的端口。
当配置好之后,我们可以启动Zookeeper服务了,具体如下:
$sudo ./zkServer.sh start
启动的结果:

3、集群环境
Zookeeper不仅可以单机提供服务,同时也支持多机组成集群来提供服务。实际上 Zookeeper还支持另外一种伪集群的方式,也就是可以在一台物理机上运行多个Zookeeper 实例,下面将介绍集群模式的安装和配置。
Zookeeper的集群模式的安装和配置也不是很复杂,所要做的就是增加几个配置项。集群模式除了上面的三个配置项还要增加下面几个配置项:
initLimit=5
syncLimit=2
server.1=192.168.211.1:2888:3888
server.2=192.168.211.2:2888:3888
• initLimit:这个配置项是用来配置 Zookeeper接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到Leader
的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过5 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
• syncLimit:这个配置项标识 Leader与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime 的时间长度,总的时间长度就是
2*2000=4 秒
• server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D
表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
NOTE:
停止:zkServer.shstop
重启:zkServer.shrestart
启动: zkServer.sh start
二、组件特点
1、数据结构
Zookeeper本身提供和维护了一个有层次关系的数据结构,类似标准的文件系统,不同的是Zookeeper文件系统的每个节点znode,都可以存储数据,而znode目前有四种类型:临时节点、临时顺序编号节点、持久化节点及持久化顺序编号节点,那么接下来结合网络上的数据结构图说明:

特点说明:
A、每个znode节点,都可以拥有子节点,并且都可以存储数据(除了临时节点EPHEMERAL);
B、每个znode节点,都被它所在的路径唯一标注,比如:NameService下的Server1,被唯一的标识为:/NameService/Server1;
C、每个znode节点,都有版本的,也就是该节点的路径下,存放多份版本的数据;
D、每个znode节点,都可以自动编号,比如:已经存在App1节点,那么再创建App1节点时,会自动创建App2节点;
E、每个znode临时节点,当客户端与服务端断开链接后,znode也自动被删除;
F、每个znode节点都可以被监控,包含该节点存放的数据及其子目录结构或数据被修改时,会立即通知发起该设置的客户端;
G、客户端与服务端的链接为长链接,彼此间采用心跳方式保持通信,这个链接状态为session状态,所以如果某个znode节点为临时节点,那么这个session就不起作用了;
2、工作特点
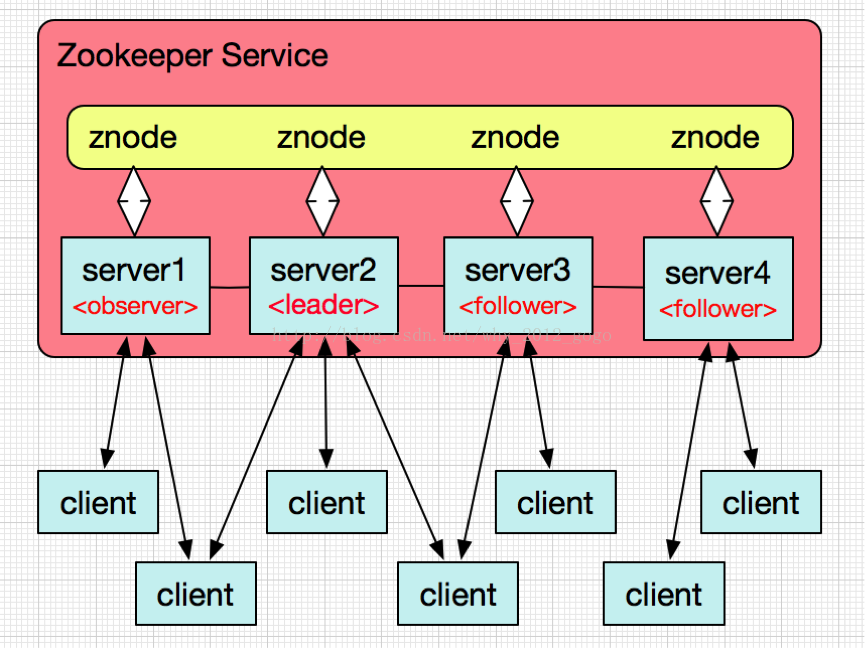
原理说明:
A、Zookeeper服务核心是原子广播,它保证了各个参与的Server间同步,实现它协议为Zab协议,它分为恢复模式和广播模式。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
B、Zookeeper服务持续监听所有注册的znode节点,一旦节点的结构、数据发生变化时,leader节点会监控到变化并更新系统状态值,所有follower和observer节点,会向leader节点的数据状态同步,这也是Zookeeper在分布式环境的核心作用;
C、所有的observer的znode节点,都可接收客户端的链接,也会从leader节点同步更新最新的数据版本,但其不参与leader的投票动作,会将客户端的写入数据请求转发给leader节点处理;
D、所有的follower的znode节点,都有资格参与leader的投票选择,也会自动从leader节点更新同步数据版本,也处理客户端的请求及返回结果;
3、设计目的
A、原子性,各个znode节点数据只有更新成功或失败,没有中间状态;
B、可靠性,如果一条消息被一台服务器接收,那么其它各个服务器都会接收,保证了数据的一致性;
C、实时性,Zookeeper可保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到最新的数据,如果需要最新数据,应该在读取数据之前调用sync()接口,来手动获取最新的数据版本;
D、等待无关性,无效的或是阻塞的客户端链接,不影响其它任务客户端链接,各个链接客户端彼此独立链接;
E、一致性,客户端不论连接到哪个服务器上,展示给它都是同一个视图,这是Zookeeper最重要的性能。
三、如何使用
基本使用如下,比较简单:
publicstatic void
main(String[] args) {
try{
// 创建一个与服务器的连接
ZooKeeper zk =
new ZooKeeper("localhost:"+ 2181,
200000,
new Watcher() {
//
监控所有被触发的事件
public voidprocess(WatchedEvent event) {
log("已经触发了" + event.getType() + "事件!");
}
});
// 创建一个目录节点
zk.create("/testRootPath", "testRootData".getBytes(),Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
// 创建一个子目录节点
zk.create("/testRootPath/testChildPathOne","testChildDataOne".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
log(new String(zk.getData("/testRootPath",false,null)));
// 取出子目录节点列表
log(zk.getChildren("/testRootPath",true));
// 修改子目录节点数据
zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1);
log("目录节点状态:["+zk.exists("/testRootPath",true)+"]");
// 创建另外一个子目录节点
zk.create("/testRootPath/testChildPathTwo","testChildDataTwo".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
log(new String(zk.getData("/testRootPath/testChildPathTwo",true,null)));
// 删除子目录节点
zk.delete("/testRootPath/testChildPathTwo",-1);
zk.delete("/testRootPath/testChildPathOne",-1);
// 删除父目录节点
zk.delete("/testRootPath",-1);
// 关闭连接
zk.close();
}catch (IOException e) {
e.printStackTrace();
}catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
privatestatic void log(Object msg) {
System.out.println(msg);
}
运行结果如下:

分布式服务框架之Zookeeper就介绍到这里,由于作者水平有限,如有问题请在评论发言或是QQ群(245389109(新))讨论,谢谢。
Zookeeper是一种分布式服务框架,是apache hadoop的子项目,完全开源存在,它的诞生主要用来处理分布式环境中数据管理问题,比如:分布式应用程序配置、集群管理、状态同步服务及命名服务等。这里,我们以3.4.8版本为例展开介绍,其最新的版本下载可以从地址:
http://hadoop.apache.org/zookeeper/ 中获取,并以java项目为例进行分析和使用Zookeeper,和以往文章一样,都是以安装配置开始!
l 安装配置
l 组件特点
l 入门使用
一、安装配置
Zookeeper的安装十分简单,我们只需要从如下地址下载并解压:
http://mirrors.cnnic.cn/apache/zookeeper/
然后,Zookeeper的安装配置,可以从单机和集群环境介绍:
1、配置
在开始服务前,有几个基本配置要准备下,Zookeeper的配置文件在conf文件夹下,默认名为zoo_sample.cfg,也是Zookeeper默认加载的配置文件,这里我们把它改个名字:
$sudo mv zoo_sample.cfg zoo.cfg
另外,当前版本的Zookeeper的conf下,还有log4j.properties和configuration.xsl文件,在后续文章中会陆续介绍它们的作用,那么接下来就先介绍zoo.cfg配置和使用情况。
2、单机环境
在单机环境下,满足服务基本需求的zoo.cfg基本内容如下:
tickTime=2000
dataDir=/zookeeper/zookeeper/build
clientPort=2181
参数说明:
tickTime:Zookeeper服务器间或客户端与服务器之间维持心跳的间隔时间,即每隔tickTime时间,就发送一次心跳检测。
dataDir:Zookeeper服务保存数据的位置,默认也是其存放写入数据的日志文件的位置。
clientPort:Zookeeper会监听这个端口,来知道客户端链接到它,也就是客户端链接Zookeeper服务器的端口。
当配置好之后,我们可以启动Zookeeper服务了,具体如下:
$sudo ./zkServer.sh start
启动的结果:
3、集群环境
Zookeeper不仅可以单机提供服务,同时也支持多机组成集群来提供服务。实际上 Zookeeper还支持另外一种伪集群的方式,也就是可以在一台物理机上运行多个Zookeeper 实例,下面将介绍集群模式的安装和配置。
Zookeeper的集群模式的安装和配置也不是很复杂,所要做的就是增加几个配置项。集群模式除了上面的三个配置项还要增加下面几个配置项:
initLimit=5
syncLimit=2
server.1=192.168.211.1:2888:3888
server.2=192.168.211.2:2888:3888
• initLimit:这个配置项是用来配置 Zookeeper接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到Leader
的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过5 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
• syncLimit:这个配置项标识 Leader与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime 的时间长度,总的时间长度就是
2*2000=4 秒
• server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D
表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
NOTE:
停止:zkServer.shstop
重启:zkServer.shrestart
启动: zkServer.sh start
二、组件特点
1、数据结构
Zookeeper本身提供和维护了一个有层次关系的数据结构,类似标准的文件系统,不同的是Zookeeper文件系统的每个节点znode,都可以存储数据,而znode目前有四种类型:临时节点、临时顺序编号节点、持久化节点及持久化顺序编号节点,那么接下来结合网络上的数据结构图说明:
特点说明:
A、每个znode节点,都可以拥有子节点,并且都可以存储数据(除了临时节点EPHEMERAL);
B、每个znode节点,都被它所在的路径唯一标注,比如:NameService下的Server1,被唯一的标识为:/NameService/Server1;
C、每个znode节点,都有版本的,也就是该节点的路径下,存放多份版本的数据;
D、每个znode节点,都可以自动编号,比如:已经存在App1节点,那么再创建App1节点时,会自动创建App2节点;
E、每个znode临时节点,当客户端与服务端断开链接后,znode也自动被删除;
F、每个znode节点都可以被监控,包含该节点存放的数据及其子目录结构或数据被修改时,会立即通知发起该设置的客户端;
G、客户端与服务端的链接为长链接,彼此间采用心跳方式保持通信,这个链接状态为session状态,所以如果某个znode节点为临时节点,那么这个session就不起作用了;
2、工作特点
原理说明:
A、Zookeeper服务核心是原子广播,它保证了各个参与的Server间同步,实现它协议为Zab协议,它分为恢复模式和广播模式。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
B、Zookeeper服务持续监听所有注册的znode节点,一旦节点的结构、数据发生变化时,leader节点会监控到变化并更新系统状态值,所有follower和observer节点,会向leader节点的数据状态同步,这也是Zookeeper在分布式环境的核心作用;
C、所有的observer的znode节点,都可接收客户端的链接,也会从leader节点同步更新最新的数据版本,但其不参与leader的投票动作,会将客户端的写入数据请求转发给leader节点处理;
D、所有的follower的znode节点,都有资格参与leader的投票选择,也会自动从leader节点更新同步数据版本,也处理客户端的请求及返回结果;
3、设计目的
A、原子性,各个znode节点数据只有更新成功或失败,没有中间状态;
B、可靠性,如果一条消息被一台服务器接收,那么其它各个服务器都会接收,保证了数据的一致性;
C、实时性,Zookeeper可保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到最新的数据,如果需要最新数据,应该在读取数据之前调用sync()接口,来手动获取最新的数据版本;
D、等待无关性,无效的或是阻塞的客户端链接,不影响其它任务客户端链接,各个链接客户端彼此独立链接;
E、一致性,客户端不论连接到哪个服务器上,展示给它都是同一个视图,这是Zookeeper最重要的性能。
三、如何使用
基本使用如下,比较简单:
publicstatic void
main(String[] args) {
try{
// 创建一个与服务器的连接
ZooKeeper zk =
new ZooKeeper("localhost:"+ 2181,
200000,
new Watcher() {
//
监控所有被触发的事件
public voidprocess(WatchedEvent event) {
log("已经触发了" + event.getType() + "事件!");
}
});
// 创建一个目录节点
zk.create("/testRootPath", "testRootData".getBytes(),Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
// 创建一个子目录节点
zk.create("/testRootPath/testChildPathOne","testChildDataOne".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
log(new String(zk.getData("/testRootPath",false,null)));
// 取出子目录节点列表
log(zk.getChildren("/testRootPath",true));
// 修改子目录节点数据
zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1);
log("目录节点状态:["+zk.exists("/testRootPath",true)+"]");
// 创建另外一个子目录节点
zk.create("/testRootPath/testChildPathTwo","testChildDataTwo".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
log(new String(zk.getData("/testRootPath/testChildPathTwo",true,null)));
// 删除子目录节点
zk.delete("/testRootPath/testChildPathTwo",-1);
zk.delete("/testRootPath/testChildPathOne",-1);
// 删除父目录节点
zk.delete("/testRootPath",-1);
// 关闭连接
zk.close();
}catch (IOException e) {
e.printStackTrace();
}catch (KeeperException | InterruptedException e) {
e.printStackTrace();
}
}
privatestatic void log(Object msg) {
System.out.println(msg);
}
运行结果如下:
分布式服务框架之Zookeeper就介绍到这里,由于作者水平有限,如有问题请在评论发言或是QQ群(245389109(新))讨论,谢谢。

相关文章推荐
- [置顶] arcgis api for js入门开发系列十四 GP服务一框架介绍
- [置顶] 【Java】Dubbo+zookeeper搭建分布式服务框架
- 分布式服务框架 Zookeeper(一)介绍
- Zookeeper -- 分布式服务框架介绍,管理分布式环境中的数据
- 分布式服务框架 Zookeeper(二)官方介绍
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper
- 使用ArcGIS GP服务之一框架介绍
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- python模块介绍- SocketServer 网络服务框架
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- QQ机器人开放式服务框架 Version 0.1 Draft - 测试用QQ机器人介绍