Screen Space Reflection 学习笔记
2016-12-26 20:12
876 查看
[来源 by kode80]
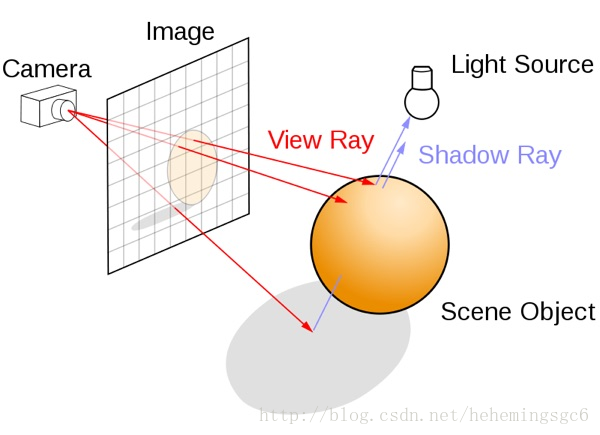
经典的对图像的光线追踪的做法是从镜头处发射一条射线,当其与物体相交时,计算这个点的颜色,并作为这条射线最近的像素的颜色值。通常来说光线追踪会需要获取场景中所有几何体、材质、光照的信息,并使用一个完整的Rendering pipeline来达成。我们也能使用类似的方法,利用延迟渲染中的GBuffers来达成期望的效果。
在Unity中我们可以获得所有所需的信息。我们可以将Camera的depthTextureMode设为DepthTextureMode.DepthNormals,从而使得任何这个镜头调用到的Shader都会获得一个sampler2D _CameraDepthNormalsTexture,这其中包含了当前镜头渲染图片的normal和depth信息;由此我们可以构建出每个像素对应的到三维空间中的位置,再使用reflect(lightDir,
normal)可以得到反射方向向量;
在Unity中的后处理效果都是通过渲染一个屏幕的四边形来实现的,我们可以在vert函数中获得对应的UV,将其转化为NDC坐标,再右乘一个inverse projection matrix,就可以获得到远裁剪面的四个顶点(在观察空间下)。将这个方向向量传给frag函数,我们便可以得到一个插值后的结果,这个结果就是对应各个像素的镜头到远裁剪面的射线。将这个射线乘以depth,我们便可以得到像素对应在三维空间中的位置。
为了实现这一点我们必须把射线作为一个在屏幕空间中的2D线段来看待。使用透视校正后插值的射线的开始点和结束点的Z值,我们可以在屏幕空间中追踪这个射线的同时得到观察空间的每个step的深度值。
(射线最大距离验证:
该操作是在观察空间下进行的,所以Z为负数,Z越小距离镜头越远;
使用投影矩阵我们可以将观察空间中射线的起始点转化为齐次坐标,然后再对其Z和W分量进行线性插值;对于每个ray casting loop,我们都将当前齐次Z分量除以W来得到该点在观察空间中的深度值;
(齐次坐标:http://blog.csdn.net/janestar/article/details/44244849)
-当镜头空间的顶点被投影矩阵转换后,得到的齐次坐标必须除以w分量来得到最终投影后的屏幕空间坐标;
(使用McGuire的光线追踪算法:将3D光线转换为2D,并对其进行插值从而获取深度)

(关于透视矫正插值:http://blog.csdn.net/bbvs1/article/details/7964689)
第一种是计算当前点的Depth,并与深度纹理中对应的Depth相比较判断是否相交;
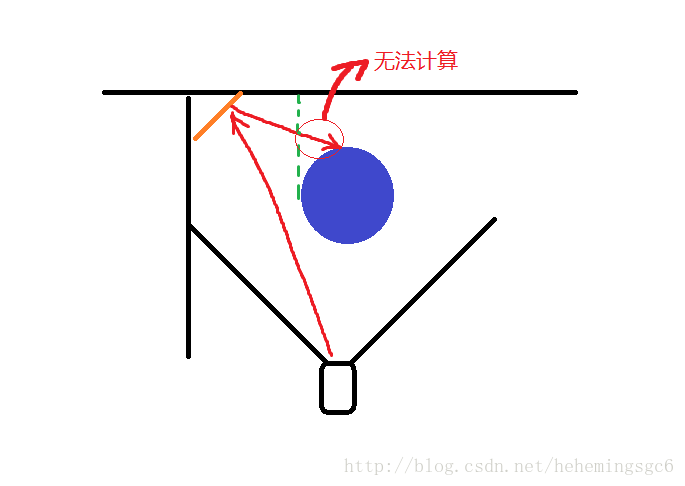
这种方法的缺点在于容易造成误算(false positive),因为在这种方法下在物体背面的反射光线无法被计算;
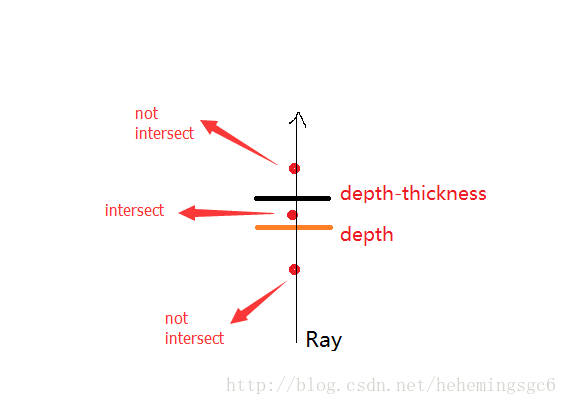
第二种方法就是设置一个thickness(厚度)临界值,当step的depth介乎于depth和depth-thickness之间时可以判定为相交;
这种方法的缺点在于如果同一场景中物体的厚度差距过大,则会产生错误的结果(想象一下人和一座大山);
最终的解决方案:参考次表面散射的方法,剔除物体的正面,单独渲染背面并获得其对应的深度贴图,然后再使用正面的深度贴图减去这个背面的深度贴图,得到物体的厚度贴图;此外在渲染Back-depth的时候可以进行6X的降采样,依然能够得到可以接受的结果。

front-depth

back-depth

thickness
使用二进制搜索我们能够以十分微小的代价重新得到一些精度(通过重新定义ray trace的final step),具体做法为:
先定义一个步进,当发现某个step与几何体相交时,将step的步进/2,并以该step的起点为总体起点重新进行step march,并找到新的相交点;以此循环N次,N=iteration;
这种方法在对于非常薄的物体时依然会出现问题,但是效果已经非常不错了(假设stride=40,iteration=10),再配合上jitter,基本上可以得到比较完美的反射,如下图:

No binary search

with binary search

binary search + jitter
射向镜头椎体(camera frustum)之外的射线;
射向镜头的射线;
射线超出了最大检测距离/循环次数的部分;
最后我们将a*b*c*d得到最终的透明度;
下一个选项就是使用模糊,在ray trace pass后进行image blur(在另一篇文章中用的是高斯模糊),通过基于GBuffer中的粗糙度值来调整模糊半径(kernel radius),可以获得一种近似而廉价的粗糙表面反射效果;使用这种模糊需要我们将计算得出的alpha存储在一个输出图像上,然后对这个输出图像进行blur,然后再使用这个模糊处理后的alpha和原图像进行Blend;

physical-base result

blur result
原始的做法
经典的对图像的光线追踪的做法是从镜头处发射一条射线,当其与物体相交时,计算这个点的颜色,并作为这条射线最近的像素的颜色值。通常来说光线追踪会需要获取场景中所有几何体、材质、光照的信息,并使用一个完整的Rendering pipeline来达成。我们也能使用类似的方法,利用延迟渲染中的GBuffers来达成期望的效果。
在Unity中我们可以获得所有所需的信息。我们可以将Camera的depthTextureMode设为DepthTextureMode.DepthNormals,从而使得任何这个镜头调用到的Shader都会获得一个sampler2D _CameraDepthNormalsTexture,这其中包含了当前镜头渲染图片的normal和depth信息;由此我们可以构建出每个像素对应的到三维空间中的位置,再使用reflect(lightDir,
normal)可以得到反射方向向量;
在Unity中的后处理效果都是通过渲染一个屏幕的四边形来实现的,我们可以在vert函数中获得对应的UV,将其转化为NDC坐标,再右乘一个inverse projection matrix,就可以获得到远裁剪面的四个顶点(在观察空间下)。将这个方向向量传给frag函数,我们便可以得到一个插值后的结果,这个结果就是对应各个像素的镜头到远裁剪面的射线。将这个射线乘以depth,我们便可以得到像素对应在三维空间中的位置。
// Calculate camera to far plane ray in vertex shader float4 cameraRay = float4( vertex.uv * 2.0 - 1.0, 1.0, 1.0); cameraRay = mul( _CameraInverseProjectionMatrix, cameraRay); output.cameraRay = cameraRay.xyz / cameraRay.w; // Calculate camera space pixel position in fragment shader float3 decodedNormal; float decodedDepth; DecodeDepthNormal( tex2D( _CameraDepthNormalsTexture, input.uv), decodedDepth, decodedNormal); float3 pixelPosition = input.cameraRay * decodedDepth;
Camera vs GBuffer Normal
_CameraDepthNormalsTexture是一个32bit的图像,其中depth和normal各占用16bit,使用它会使得两者的精度下降。我们可以使用GBuffer中的_CameraGBufferTexture2来获取世界空间的normal,再通过传入一个转换为观察空间的矩阵(camera.worldToCameraMatrix)将其转到观察空间,从而获得normal,这样我们就能使用32bit来存储一个完整的depth图像,从而提高精度(将Camera的depthTextureMode设为DepthTextureMode.Depth);// In C# script material.SetMatrix( "_NormalMatrix", camera.worldToCameraMatrix); // In fragment shader float3 worldSpaceNormal = tex2D( _CameraGBufferTexture2, i.uv).rgb * 2.0 - 1.0; float3 cameraSpaceNormal = mul( (float3x3)_NormalMatrix, worldSpaceNormal);
绘制2D射线(3D转2D)
3D射线有一个主要的问题,就是其可能在实际的屏幕空间中的起始点只有几个甚至一个像素的距离,在这种情况下进行过多的step计算就非常浪费;同时也可能起点与终点之间像素距离非常大,此时step数不足又会造成效果的瑕疵。为了解决这个问题,我们需要一种方法来保证Raycast的每一个step至少会垂直或水平移动一个像素。为了实现这一点我们必须把射线作为一个在屏幕空间中的2D线段来看待。使用透视校正后插值的射线的开始点和结束点的Z值,我们可以在屏幕空间中追踪这个射线的同时得到观察空间的每个step的深度值。
(射线最大距离验证:
该操作是在观察空间下进行的,所以Z为负数,Z越小距离镜头越远;
// Clip to the near plane // 该操作是在观察空间下进行的,所以Z为负数,Z越小距离镜头越远; // 求出最远交叉点的Z值,如果小于Z,则说明在Frustum之中,否则说明其在Near Clip Plane之外,需要将射线长度裁剪到Near Clip Plane之内 float rayLength = ((rayOrigin.z + rayDirection.z * _MaxRayDistance) > -_ProjectionParams.y) ? (-_ProjectionParams.y - rayOrigin.z) / rayDirection.z : _MaxRayDistance; float3 rayEnd = rayOrigin + rayDirection * rayLength; )
使用投影矩阵我们可以将观察空间中射线的起始点转化为齐次坐标,然后再对其Z和W分量进行线性插值;对于每个ray casting loop,我们都将当前齐次Z分量除以W来得到该点在观察空间中的深度值;
(齐次坐标:http://blog.csdn.net/janestar/article/details/44244849)
-当镜头空间的顶点被投影矩阵转换后,得到的齐次坐标必须除以w分量来得到最终投影后的屏幕空间坐标;
(使用McGuire的光线追踪算法:将3D光线转换为2D,并对其进行插值从而获取深度)
(关于透视矫正插值:http://blog.csdn.net/bbvs1/article/details/7964689)
计算几何体的厚度
计算每个step与场景物体相交一般有两种算法:第一种是计算当前点的Depth,并与深度纹理中对应的Depth相比较判断是否相交;
这种方法的缺点在于容易造成误算(false positive),因为在这种方法下在物体背面的反射光线无法被计算;
第二种方法就是设置一个thickness(厚度)临界值,当step的depth介乎于depth和depth-thickness之间时可以判定为相交;
这种方法的缺点在于如果同一场景中物体的厚度差距过大,则会产生错误的结果(想象一下人和一座大山);
最终的解决方案:参考次表面散射的方法,剔除物体的正面,单独渲染背面并获得其对应的深度贴图,然后再使用正面的深度贴图减去这个背面的深度贴图,得到物体的厚度贴图;此外在渲染Back-depth的时候可以进行6X的降采样,依然能够得到可以接受的结果。
front-depth
back-depth
thickness
二进制搜索改进法(Binary Search Refinement)
当我们发射一个线性的射线时,我们可以通过增加每个step的长度来减少(检测)循环的次数。在屏幕空间使得我们可以引入一个叫做像素步进(pixel stride)的概念,用来控制每个step步进多少个像素。使用二进制搜索我们能够以十分微小的代价重新得到一些精度(通过重新定义ray trace的final step),具体做法为:
先定义一个步进,当发现某个step与几何体相交时,将step的步进/2,并以该step的起点为总体起点重新进行step march,并找到新的相交点;以此循环N次,N=iteration;
这种方法在对于非常薄的物体时依然会出现问题,但是效果已经非常不错了(假设stride=40,iteration=10),再配合上jitter,基本上可以得到比较完美的反射,如下图:
No binary search
with binary search
binary search + jitter
Hiding Artifact
由于SSR是后处理效果,所以造成非真实性的第一原因就是缺乏场景的信息。为了隐藏这些非真实性,我们需要检测出射线与没有信息的位置的交点(比如不在屏幕内的位置),并且平滑地淡出这些反射。我们需要重点关注以下三种情况:射向镜头椎体(camera frustum)之外的射线;
射向镜头的射线;
射线超出了最大检测距离/循环次数的部分;
情况1
当射线与场景中的物体在depth buffer中相交时,我们可以获得这个UV坐标从而从frame buffer中获得这个像素。通过把UV坐标转化为NDC坐标(如何转换?),我们能够轻易地检测这个像素离屏幕的边缘(上下左右)有多远;通过定义一个a∈(0, 1)范围我们能够轻易地基于距离屏幕边缘的距离控制反射的淡出与淡入;情况2
我们可以认为射向镜头方向的射线会碰到场景中物体的背面,所以也需要平滑地淡出;由于我们在观察空间中进行计算,所以任何Z值为正的射线都是射向镜头,所以我们定义另一个b∈(0, 1)范围来平滑地根据Z值淡出;情况3
当一个射线与场景物体相交时我们首先获取step的number,并将其除以maximum iteration setting(最大step数)(c);然后计算镜头到交点的距离,并将这个距离除以最大射线检测距离(d);最后我们将a*b*c*d得到最终的透明度;
模拟粗糙表面的反射(Faking Glossy Reflection)
最开始我尝试模拟粗糙度的方法是使用GBuffer中的值作为一个随机向量缩放量(scaler),这个随机向量会加到reflection vector上。这是符合微表面原理的做法,并且从某些角度上来说确实有一定的效果。但是在非常模糊的表面上会有非常多的噪点(shimmering),即便进行了blur pass也很难消除;下一个选项就是使用模糊,在ray trace pass后进行image blur(在另一篇文章中用的是高斯模糊),通过基于GBuffer中的粗糙度值来调整模糊半径(kernel radius),可以获得一种近似而廉价的粗糙表面反射效果;使用这种模糊需要我们将计算得出的alpha存储在一个输出图像上,然后对这个输出图像进行blur,然后再使用这个模糊处理后的alpha和原图像进行Blend;
physical-base result
blur result

相关文章推荐
- java se 学习笔记 之 reflection(反射机制)1
- Net反射(Reflection)学习笔记
- 【D3D11游戏编程】学习笔记二十四:切线空间(Tangent Space)
- Part2:Unity学习笔记十四 - Space Shooter(从视频最后一课向Done_Main.unity场景修改的过程)
- JAVA学习笔记(六十一)- 反射Reflection
- 【deep learning学习笔记】New Directions in Vector Space Models of Meaningful_Edward_acl2014Tutorial
- IOS学习笔记2-IOS屏幕 [[UIScreen mainScreen] bounds] 与[UIScreen mainScreen] applicationFrame]区别
- C#学习笔记之四(Attribute, Reflection, Thread, Thread Syn
- 魔兽世界的Screen Space Local Reflection
- PHP反射ReflectionClass、ReflectionMethod 学习笔记 (一)
- Java Reflection(反射) 入门学习笔记 之一
- java se 学习笔记 之 reflection(反射机制之Array_2)3
- java se 学习笔记 之 reflection(反射机制之Array_1)2
- 【Deep Learning学习笔记】Efficient Estimation of Word Representations in Vector Space_google2013
- 微分流形与黎曼几何学习笔记(转自http://blog.sciencenet.cn/home.php?mod=space&uid=81613&do=blog&id=333317)
- oracle 学习笔记 transport tablespace
- java se 学习笔记 之 reflection(在类外部调用private成员的方式)5
- java se 学习笔记 之 reflection(完成一个对象copy的demo)4
- 快速学习js 笔记四 screen 对象
- java学习笔记 反射reflection相关知识点小结