Python实现简单爬虫功能--批量下载百度贴吧里的图片
2016-12-23 15:01
1036 查看
在上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。如何批量的保存图片呢,Python几行代码就能搞定。
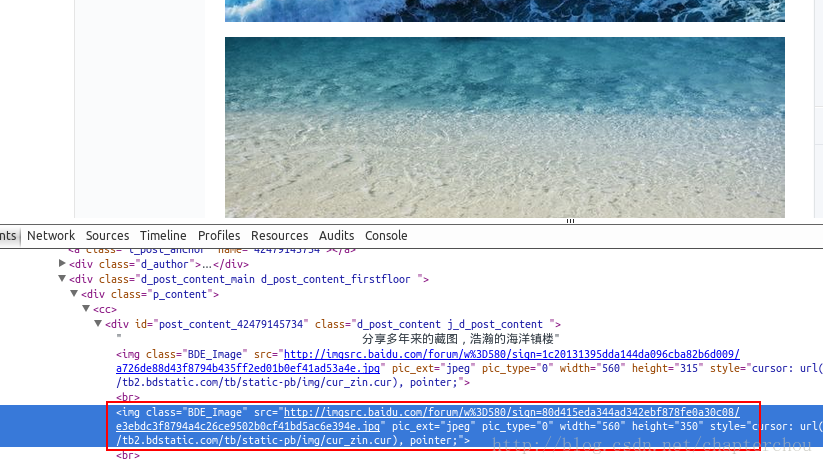
通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum……jpg”pic_ext=”jpeg”
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。如何批量的保存图片呢,Python几行代码就能搞定。
获取页面数据
到http://tieba.baidu.com/p/2460150866 去查看通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum……jpg”pic_ext=”jpeg”
代码
# coding=utf-8
import urllib.request
import re
def downloadPage(url):
h = urllib.request.urlopen(url)
return h.read().decode('utf-8')
def downloadImg(content):
pattern = r'src="(.+?\.jpg)" pic_ext'
m = re.compile(pattern)
urls = re.findall(m, content)
for i, url in enumerate(urls):
urllib.request.urlretrieve(url, "%s.jpg" % (i,))
content = downloadPage("http://tieba.baidu.com/p/2460150866")
downloadImg(content)

相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- 爬虫笔记
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- 用python+selenium抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答并保存至html文件