k近邻算法及python实现
2016-12-19 18:01
351 查看
k近邻算法是机器学习中最简单的一种算法,简单粗暴,给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,把这K个实例中出现最多的类作为输入实例的类。对于初学者可能会好奇,这个近邻是什么意思?例如调查一群人的信息,会对研究目标调查多个特征,记录人的头发长度、身高、年龄、体重、肤色,性别,对这些特征采用数值进行刻画。假设现在我们需要通过头发长度、身高、年龄、体重和肤色这些数据来判断一个人的性别,我们会计算这个人的数据与其他(她)人的数据的差值,对差值取绝对值求和,找出差别最小的k个人,而把这k个人中性别多数作为这个人的性别判断结果。
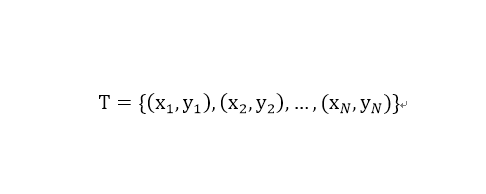
其中,xi属于特征向量,yi为实例的类别,i=1,2,...,N
输出:实例x所属的类y
(1)根据给定的距离度量,在训练集T中找出与x最近的k个点,涵盖这个k个点的x的领域记做Nk(x).
(2)根据分类决策规则决定x的类别y,通常采用多数表决策略:
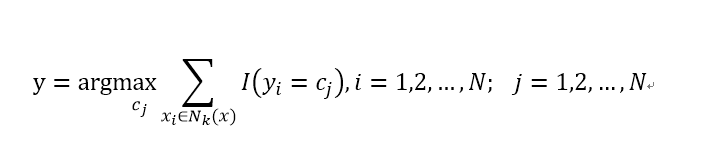
上式中I为指示函数,当yi=cj是I为1,否则为零。
从上面的算法可以看出,K近邻算法并不像其它的机器学习算法那样通过训练数据得到一个模型,通过这个学习到的模型来对数据进行预测。而是需要对每个预测数据计算与样本数据集中的每个实例的距离,因此,k近邻算法的时间代价是随着样本空间的递增而递增的,所以对于大型数据集k近邻不是一个很好的选择,一次预测可能要好几天甚至更久才能得到结果。可以尝试将训练数据复制粘贴多次扩大训练样本(仅作为测试时间变化),比较计算时间的变化。
k近邻算法,是通过训练数据对特征空间的一个划分,每个样本点都有一个距离该样本点比其它样本点都近的领域,如果将k值设置为1,那么任何落入这个领域的测试样例都可以认为是和该样本点有着相同的类。 因此当一个k近邻算法,给定了训练样本、距离度量和k值,任何一个测试样例的类别是唯一确定的。
k近邻的相似度通过两个实例点的距离度量,常用的距离度量有,曼哈顿距离,欧式距离等,这些距离的通式如下:
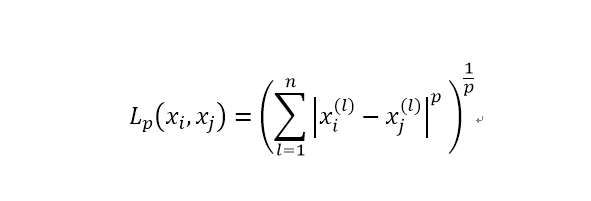
当P取1时即为曼哈顿距离,当p取2时即为欧式距离。不同的取值,与中心点围成多维图形的区域大小也会不同,因此预测的结果也会有所不同。
loadDataSet函数传入一个文件名,读取文件中的数据并返回特征数据集和标签集。
因为在数据中不同的特征的取值范围可能不同,例如人的身高和年龄,数值的取值范围不同,在计算距离的时候取值范围大的特征列对最后的结果影响大,而这种影响可能会掩盖取值小的数据对结果的影响。在没有任何先验知识的情况下,认为任何特征对结果的影响相同,因此有必要将数据规范化,通常的做法是将数据变化为0-1的范围内。
下面的minMax函数计算每一列的取值最小值,和取值范围:
然后通过autoNormal函数将数据规范化:
这里采用的是欧式距离:
通过计算输入数据与训练数据中的每个实例距离,按照从小到大排序,选择最小的k个,并从找出这k个实例中出现最多的类:
我对整个算法进行了一个封装,通过初始化函数设置算法的k值,在fit()函数中传入训练数据,通过predict()函数对给定的数据进行预测。Knn类完整代码如下:
参考自:《机器学习实战》、《统计学习方法》
测试数据下载地址:http://download.csdn.net/detail/u013732444/9715691
k近邻算法
输入:训练数据集其中,xi属于特征向量,yi为实例的类别,i=1,2,...,N
输出:实例x所属的类y
(1)根据给定的距离度量,在训练集T中找出与x最近的k个点,涵盖这个k个点的x的领域记做Nk(x).
(2)根据分类决策规则决定x的类别y,通常采用多数表决策略:
上式中I为指示函数,当yi=cj是I为1,否则为零。
从上面的算法可以看出,K近邻算法并不像其它的机器学习算法那样通过训练数据得到一个模型,通过这个学习到的模型来对数据进行预测。而是需要对每个预测数据计算与样本数据集中的每个实例的距离,因此,k近邻算法的时间代价是随着样本空间的递增而递增的,所以对于大型数据集k近邻不是一个很好的选择,一次预测可能要好几天甚至更久才能得到结果。可以尝试将训练数据复制粘贴多次扩大训练样本(仅作为测试时间变化),比较计算时间的变化。
k近邻算法,是通过训练数据对特征空间的一个划分,每个样本点都有一个距离该样本点比其它样本点都近的领域,如果将k值设置为1,那么任何落入这个领域的测试样例都可以认为是和该样本点有着相同的类。 因此当一个k近邻算法,给定了训练样本、距离度量和k值,任何一个测试样例的类别是唯一确定的。
k近邻的相似度通过两个实例点的距离度量,常用的距离度量有,曼哈顿距离,欧式距离等,这些距离的通式如下:
当P取1时即为曼哈顿距离,当p取2时即为欧式距离。不同的取值,与中心点围成多维图形的区域大小也会不同,因此预测的结果也会有所不同。
Python实现一个简单的k近邻算法:
首先需要从文件中读取数据def loadDataSet(fileName):
dataSet=[]
labelSet=[]
fr=open(fileName)
for line in fr.readlines():
curLine=line.strip().split('\t')
dataArr=[]
for feat in curLine[:-1]:
dataArr.append(float(feat.strip()))
dataSet.append(dataArr)
labelSet.append(int(curLine[-1].strip()))
return np.array(dataSet),np.array(labelSet)loadDataSet函数传入一个文件名,读取文件中的数据并返回特征数据集和标签集。
因为在数据中不同的特征的取值范围可能不同,例如人的身高和年龄,数值的取值范围不同,在计算距离的时候取值范围大的特征列对最后的结果影响大,而这种影响可能会掩盖取值小的数据对结果的影响。在没有任何先验知识的情况下,认为任何特征对结果的影响相同,因此有必要将数据规范化,通常的做法是将数据变化为0-1的范围内。
下面的minMax函数计算每一列的取值最小值,和取值范围:
def minMax(self): self.min=dataSet.min(0) self.range=dataSet.max(0)-self.min
然后通过autoNormal函数将数据规范化:
def autoNorm(self,dataSet): self.minMax() dataSet=dataSet-self.min return dataSet/self.range
这里采用的是欧式距离:
def distance(self,x,y): return np.sum(pow(x-y,2))
通过计算输入数据与训练数据中的每个实例距离,按照从小到大排序,选择最小的k个,并从找出这k个实例中出现最多的类:
def calculate(self,test):
distances=[]
for data in self.dataSet:
distances.append(self.distance(data,test))
sortedIndicies=np.argsort(np.array(distances))
classCount={}
for i in range(self.k):
voteILabel=self.labelSet[sortedIndicies[i]]
classCount[voteILabel]=classCount.get(voteILabel,0)+1
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]我对整个算法进行了一个封装,通过初始化函数设置算法的k值,在fit()函数中传入训练数据,通过predict()函数对给定的数据进行预测。Knn类完整代码如下:
class Knn:
dataSet=[]
labelSet=[]
#初始化,设置K值
def __init__(self,k):
self.k=k
#设置模型的数据
def fit(self,dataSet,label):
self.labelSet=label
self.minMax(dataSet)
self.dataSet=self.autoNorm(dataSet)
#计算各列的最小值和取值范围
def minMax(self,dataSet):
self.min=dataSet.min(0)
self.range=dataSet.max(0)-self.min
#在对数据无任何先验知识的情况下默认各列的重要性相同,对各列进行标准化
def autoNorm(self,dataSet):
dataSet=dataSet-self.min
return dataSet/self.range
#计算两个数据点的距离(x1-y1)^2+(x2-y2)^2+...(xn-yn)^2
def distance(self,x,y):
return np.sum(pow(x-y,2))
def predict(self,data):
data=self.autoNorm(data)
predictLabel=[]
for temp in data:
predictLabel.append(self.calculate(temp))
return predictLabel
def calculate(self,test): distances=[] for data in self.dataSet: distances.append(self.distance(data,test)) sortedIndicies=np.argsort(np.array(distances)) classCount={} for i in range(self.k): voteILabel=self.labelSet[sortedIndicies[i]] classCount[voteILabel]=classCount.get(voteILabel,0)+1 sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0]
小结:
K近邻算法对K值的选择对预测结果影响非常大,较小的取值会对异常值敏感,例如K取1,刚好落在一个异常点的区域内,则预测会出错。k值太小,只有较小的邻域对预测有影响,意味着整体模型的复杂度变得复杂,容易发生过拟合。K值取得太大,较远距离的点会影响数据的预测,极端情况下,取整个训练数据集,这时任何数据的预测结果一定是数据集中出现最多的类,这种情况忽略了训练数据中的有用信息。k值的增大,意味着模型复杂度降低,但是模型趋于简单,容易发生欠拟合。因此k值的选取很重要,通常采用交叉验证的方法,通过网格搜索方法选择合适的K值。参考自:《机器学习实战》、《统计学习方法》
测试数据下载地址:http://download.csdn.net/detail/u013732444/9715691

相关文章推荐
- 【机器学习算法-python实现】KNN-k近邻算法的实现(附源码)
- K近邻算法原理及实现(Python)
- 【机器学习系列】kNN(k近邻算法)的python实现
- 用python实现k近邻算法的示例代码
- python K近邻算法的kd树实现
- 机器学习实战笔记(Python实现)-02-k近邻算法(kNN)
- K近邻算法讲解与python实现(附源码demo下载链接)
- python实现:K近邻算法改进约会网站匹配效果
- 用Python从零开始实现K近邻算法
- 【机器学习算法-python实现】KNN-k近邻算法的实现(附源代码)
- 用Python实现机器学习算法---k近邻算法
- 【机器学习算法-python实现】KNN-k近邻算法的实现(附源码)
- k近邻算法详解及Python实现
- k近邻算法识别手写数字Python实现
- 机器学习实战笔记(Python实现)-02-k近邻算法(kNN)
- 【机器学习算法-python实现】KNN-k近邻算法的实现(附源码)
- 机器学习实战笔记(Python实现)-02-k近邻算法(kNN)
- 机器学习算法的python实现(1)---k近邻算法(kNN)
- 最简单的K近邻算法 KNN python实现
- python实现文件传输