在这个浮躁的社会,很多人只是粘贴一份算法,跑一遍,就算懂了,我们应该沉下心来
2016-12-15 23:34
761 查看
1.概述
排序是计算机程序设计中的一个重要操作,它的功能是将一个数据记录(或记录)的任意序列,重新排列成一个按关键字有序的序列。
为了方便描述,我们先确切定义排序:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},要确定一种序列,该序列的关键字满足非递减(或非递增)关系,这种操作称之为排序。
若n个记录的序列中的任意两个记录排序前后的顺序一致则称这种排序是稳定的。
例如:原序列中Ri排在Rj之前,1<=i<=n,1<=j<=n,i!=j,排序之后依旧Ri排在Rj之前,这就是稳定排序,反之,不稳定排序。
如果排序只在RAM中进行则称之为内部排序,如果涉及到了外部存储器(比如磁盘、固态硬盘、软盘和闪存等)则称之为外部排序。
为什么会有这两种方式呢,很简单,如果处理的数据极大,一次不能全部读入内存,则需要借助外部存储器进行排序。
2.插入排序
2.1直接插入排序
最简单的排序方式,基本操作是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录长度加1的有序表。
简单证明:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},初始取该序列的第一个记录为有序序列。
第一步取该序列的第二个记录,插入有序序列的适当位置,使之有序;
假设第n-2步之后的原有序序列有序;
第n-1步时选取含n个记录的序列为{R1,R2,R3,...,Rn}的第n个记录,插入有序序列的适当位置,使之有序,则第n-1步之后的有序序列仍然有序。
证毕。
那么如何插入有序序列的适当位置呢?
含n个记录的序列为{R1,R2,R3,...,Rn}中选取第i个记录时,前面i-1个记录已经有序,则首先比较第i个记录与第i-1个记录的大小,如果第i个记录小于第i-1记录,则交换,再从第i-2个记录向前搜索,在搜索过程中,只要遇到大于第i个记录的记录,就将当前记录后移一个位置,直至某个记录小于或者等于第i个记录或者向前搜索到了第0个位置。
其算法如下:
qSort
算法时间复杂度分析:
,
从快速排序的过程我们可以得到下面的方程:
最坏情况:
T(n)=T(n-1)+n (n>=2,n∈N+,为什么是这个范围呢,等于1的时候直接退出,不用比较;只有一个记录比较啥)
T(1)=0,T(2)=2;
T(n)为总的问题的工作量,n为划分过程的工作量。算法的时间复杂度分析,一般关心的是关键语句的执行次数,这里的比较操作是关键语句。什么叫关键语句呢,执行次数最多的语句就叫关键语句。
为什么划分过程中的工作量为n呢,必须的啊,无论你怎么玩,每次都要将枢轴与枢轴所在序列的所有记录的关键字比较大小,直至low等于high。也就是总共进行了n次比较。
T函数中的自变量表示该问题下的序列长度。
最坏情况,也就是,你每次苦逼的比较了所有的数,但是每次都只得到一个子序列,仅比序列长度少1。
这个递推方程是不是很熟悉,无论你用递归树还是累加法都可以轻而易举得到
不好意思哈,最初发表时算错了,应该是
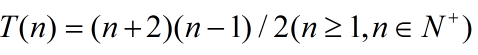
所以最坏情况的时间复杂度为O(n2)。
最好情况:
T(n)=2T(n/2)+n
每次得到两个相等的子序列。为什么呢?假设每次划分后的两个子序列分别为a和b,a+b表示这两个子序列在划分过程中的总工作量,想想大名鼎鼎的柯西不等式,你就知道当且仅当a=b时最小原式最小。
由主定理可以轻松得到最好的时间复杂度,不过,知其然知其所以然更好,我们就走走推导过程。
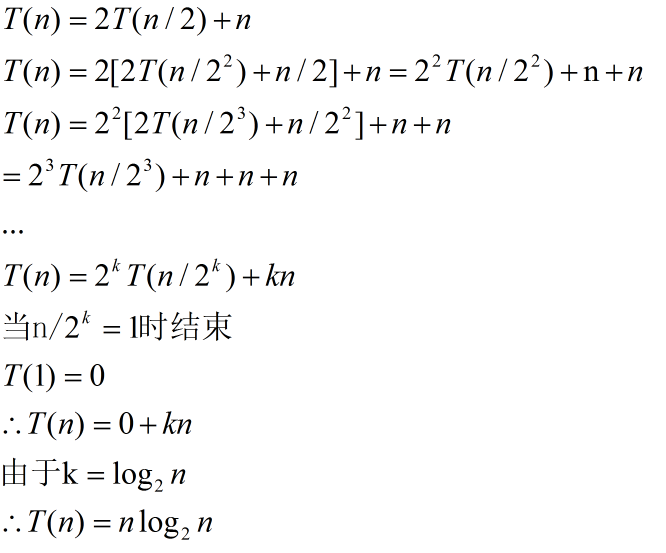
所以最好的时间复杂度为O(nlog2n)
4.测试
完整代码
测试文本:

测试结果

排序是计算机程序设计中的一个重要操作,它的功能是将一个数据记录(或记录)的任意序列,重新排列成一个按关键字有序的序列。
为了方便描述,我们先确切定义排序:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},要确定一种序列,该序列的关键字满足非递减(或非递增)关系,这种操作称之为排序。
若n个记录的序列中的任意两个记录排序前后的顺序一致则称这种排序是稳定的。
例如:原序列中Ri排在Rj之前,1<=i<=n,1<=j<=n,i!=j,排序之后依旧Ri排在Rj之前,这就是稳定排序,反之,不稳定排序。
如果排序只在RAM中进行则称之为内部排序,如果涉及到了外部存储器(比如磁盘、固态硬盘、软盘和闪存等)则称之为外部排序。
为什么会有这两种方式呢,很简单,如果处理的数据极大,一次不能全部读入内存,则需要借助外部存储器进行排序。
2.插入排序
2.1直接插入排序
最简单的排序方式,基本操作是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录长度加1的有序表。
简单证明:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},初始取该序列的第一个记录为有序序列。
第一步取该序列的第二个记录,插入有序序列的适当位置,使之有序;
假设第n-2步之后的原有序序列有序;
第n-1步时选取含n个记录的序列为{R1,R2,R3,...,Rn}的第n个记录,插入有序序列的适当位置,使之有序,则第n-1步之后的有序序列仍然有序。
证毕。
那么如何插入有序序列的适当位置呢?
含n个记录的序列为{R1,R2,R3,...,Rn}中选取第i个记录时,前面i-1个记录已经有序,则首先比较第i个记录与第i-1个记录的大小,如果第i个记录小于第i-1记录,则交换,再从第i-2个记录向前搜索,在搜索过程中,只要遇到大于第i个记录的记录,就将当前记录后移一个位置,直至某个记录小于或者等于第i个记录或者向前搜索到了第0个位置。
其算法如下:
int partition(seqList *l, int low, int high)
{
l->r[0] = l->r[low];
/*
在某趟快速排序中,首先任意选取一个记录,通常是第一个记录,作为枢轴pivot
*/
recordType tmp;
while (low < high)
/*
如果low==high,说明某趟快速排序已经搜索完所有记录并找到了枢轴的恰当位置
使得枢轴左边的记录的关键字都小于等于枢轴右边记录的关键字都大于等于枢轴
*/
{
while ((low < high)&&(l->r[0].key > l->r[low].key))++low;
while ((low < high)&&(l->r[0].key < l->r[high].key))--high;
if (low <high)
{
tmp = l->r[low];
l->r[low] = l->r[high];
l->r[high] = tmp;
}
low = low + 1;
high = high - 1;
}
return low;
}
void qSort(seqList *l, int low, int high)
{
/*
将某个序列递归的分为多个子序列,直至子问题的规模不超过零
*/
if (low < high)
{
int pivotPos = partition(l, low, high);/*将序列l->[low...high]一分为二*/
qSort(l, pivotPos + 1, high);/*对高子表递归排序*/
qSort(l, low, pivotPos - 1);/*对低子表递归排序*/
}
}qSort
算法时间复杂度分析:
,
从快速排序的过程我们可以得到下面的方程:
最坏情况:
T(n)=T(n-1)+n (n>=2,n∈N+,为什么是这个范围呢,等于1的时候直接退出,不用比较;只有一个记录比较啥)
T(1)=0,T(2)=2;
T(n)为总的问题的工作量,n为划分过程的工作量。算法的时间复杂度分析,一般关心的是关键语句的执行次数,这里的比较操作是关键语句。什么叫关键语句呢,执行次数最多的语句就叫关键语句。
为什么划分过程中的工作量为n呢,必须的啊,无论你怎么玩,每次都要将枢轴与枢轴所在序列的所有记录的关键字比较大小,直至low等于high。也就是总共进行了n次比较。
T函数中的自变量表示该问题下的序列长度。
最坏情况,也就是,你每次苦逼的比较了所有的数,但是每次都只得到一个子序列,仅比序列长度少1。
这个递推方程是不是很熟悉,无论你用递归树还是累加法都可以轻而易举得到
不好意思哈,最初发表时算错了,应该是
所以最坏情况的时间复杂度为O(n2)。
最好情况:
T(n)=2T(n/2)+n
每次得到两个相等的子序列。为什么呢?假设每次划分后的两个子序列分别为a和b,a+b表示这两个子序列在划分过程中的总工作量,想想大名鼎鼎的柯西不等式,你就知道当且仅当a=b时最小原式最小。
由主定理可以轻松得到最好的时间复杂度,不过,知其然知其所以然更好,我们就走走推导过程。
所以最好的时间复杂度为O(nlog2n)
4.测试
完整代码
#include<stdio.h>
#include<stdlib.h>
#include<conio.h>
#define MaxSize 100
typedef struct _recordType
{
int key;
int name;
}recordType;
typedef struct _seqList
{
recordType r[MaxSize + 1];
int length;
}seqList;
void insertSort(seqList *l)
{
for (int i = 2; i <= l->length; i++)
/*
初始选择第1个元素为有序序列,第一步选取该序列的第2个元素
*/
{
if (l->r[i].key < l->r[i - 1].key) /*
首先比较第i个元素与第i-1个元素的大小,如果第i个元素小于第i-1元素,则交换
*/
{
l->r[0] = l->r[i];
l->r[i] = l->r[i - 1];
int j = 0;
for (j = i - 2; l->r[0].key < l->r[j].key; --j)
/*
再从第i-2个元素向前搜索,在搜索过程中,只要遇到大于第i个元素的元素,就将当前元素后移一个位置,直至某个元素小于或者等于第i个元素或者向前搜索到了第0个位置
*/
{
l->r[j + 1] = l->r[j];
}
l->r[j + 1] = l->r[0];
}
}
}
void bInsertSort(seqList *l)
{
int low = 0;
int high = 0;
int m = 0;
for (int i = 2; i <=l->length; i++)
/*
初始选择第1个元素为有序序列,第一步选取该序列的第2个元素
*/
{
l->r[0] = l->r[i];
low = 1;
high = i - 1;
while (low <= high)
/*
折半查找
*/
{
m = (low + high) / 2;
if (l->r[0].key < l->r[m].key)high = m - 1;
else
low = m + 1;
}
for (int j = i - 1; j >= high + 1; --j)
{
l->r[j + 1] = l->r[j];
}
/*
找到对应插入位置,将对应插入位置到第i-1个位置的元素后移
*/
l->r[high + 1] = l->r[0];
}
}
void bubbleSort(seqList *l)
{
recordType tmp;
bool swap = false;
for (int i = 0; i < l->length-1; i++)/*
总共进行n-1步
*/
{
swap = false;
for (int j = 1; j <l->length - i; ++j)
/*
每一步从第1个元素开始到第n-i-1元素结束,每个元素与最近的后面位置比较
关键字大小,若为逆序则交换
*/
{
if (l->r[j].key > l->r[j + 1].key)
{
swap = true;
tmp = l->r[j + 1];
l->r[j + 1] = l->r[j];
l->r[j] = tmp;
}
}
if (swap == false)break;
/*
如果在比较关键字大小时没有记录移动,则说明前面的记录已经按关键字有序
*/
}
}
int partition(seqList *l, int low, int high) { l->r[0] = l->r[low]; /* 在某趟快速排序中,首先任意选取一个记录,通常是第一个记录,作为枢轴pivot */ recordType tmp; while (low < high) /* 如果low==high,说明某趟快速排序已经搜索完所有记录并找到了枢轴的恰当位置 使得枢轴左边的记录的关键字都小于等于枢轴右边记录的关键字都大于等于枢轴 */ { while ((low < high)&&(l->r[0].key > l->r[low].key))++low; while ((low < high)&&(l->r[0].key < l->r[high].key))--high; if (low <high) { tmp = l->r[low]; l->r[low] = l->r[high]; l->r[high] = tmp; } low = low + 1; high = high - 1; } return low; } void qSort(seqList *l, int low, int high) { /* 将某个序列递归的分为多个子序列,直至子问题的规模不超过零 */ if (low < high) { int pivotPos = partition(l, low, high);/*将序列l->[low...high]一分为二*/ qSort(l, pivotPos + 1, high);/*对高子表递归排序*/ qSort(l, low, pivotPos - 1);/*对低子表递归排序*/ } }
int sum(seqList *l,int n)
{
if (n > 0)
return sum(l, n - 1) + l->r
.key;
else
return 0;
}
int main(void)
{
freopen("in.txt", "r", stdin);
seqList *l = (seqList*)malloc(sizeof(seqList));
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
insertSort(l);
printf("Straight Insertion Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
fseek(stdin, 0, 0);
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
bInsertSort(l);
printf("Binary Insertion Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
fseek(stdin, 0, 0);
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
bubbleSort(l);
printf("Bubble Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
fseek(stdin, 0, 0);
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
qSort(l, 1, l->length);
printf("Quick Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
printf("%d\n", sum(l, l->length));
getch();
}
测试文本:
测试结果

相关文章推荐
- 我们应该去努力推动每一件有利于这个社会的一些事情
- 周末加班是家常便饭,这社会不只是程序员命苦,还有比我们更苦命的娃子,抽这个蛋疼的时间上传JBPM资料
- 输入一行数字,如果我们把这行数字中的‘5’都看成空格,那么就得到一行用空格分割的若干非负整数(可能有些整数以‘0’开头,这些头部的‘0’应该被忽略掉,除非这个整数就是由若干个‘0’组成的,这时这个整数
- 我们终于走进了这个社会[转载]
- 经济学成为显学是我们这个社会的悲哀
- 再缜密的设计,我们也很难保证完全没有bug,之所以仍未发现,只是激活这个bug的条件还没到来
- 听《武志红的心理课之潜意识就是命运》有感 命运,这个东西信者有,不信者无。我很赞同武老师的观点,一个热的外在命运和我们的内在想象,是镜像关系。这不禁让我想起了小时候的一个故事:一群青蛙比赛爬山,很多人
- 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
- ⊱静心抄经,是对抗这个浮躁社会的最好武器
- 我们都生活在这个社会
- 在这个浮躁年代里,他们留给我们的,是再次相信爱情的勇气。若你也还相信爱情,请默默转发祝福。
- 穆穆读的一些书籍推荐,读书的理由?读书的好处?为什么要读书?读什么书?让我们一起来读书,总之我们需要学习新的东西来适应这个社会的飞速变化。
- 拿到一份陌生数据我们应该怎么办
- 马小峰:区块链是一种“社会技术”,这个行业我们不能等待
- 这个就是现实呀,整个社会的浮躁,很少有人能沉下心来去学习去踏实的做事情。大学里面也不是净土,一样的受到影响。
- 翻转子串 假定我们都知道非常高效的算法来检查一个单词是否为其他字符串的子串。请将这个算法编写成一个函数,给定两个字符串s1和s2,请编写代码检查s2是否为s1旋转而成,要求只能调用一次检查子串的函数。
- 这个浮躁不安的社会
- 我们应该尊重梦想,但“诺贝尔哥”只是瞎想
- struts2的实体类映射成数据库表格时,实体类的某个属性类型设为date,但是映射结果在数据库中是datetime类型的,这个时候我们应该采用的解决办法
- 是社会太浮躁、还是我们太浮躁