python手撸线性回归及参数解释
2016-12-14 11:57
489 查看
线性回归,简单的理解,在二维空间中,找到一条直线去尽可能的拟合样本数据,给出新的样本x,可以预测其y值,y是连续值,分类是离散值,如图1所示;如果是高维空间,那就是找到一个超平面去拟合,当然也可以是曲线;为了方便理解,以二维空间的直线为例,所谓找到最好的直线,就是找参数a和b,也就是theta[0],theta[1]。
如何去衡量一条直线是否是最好,在回归问题中一般用预测值与真实值之间的距离来定义损失函数,如图2所示,使损失函数值最小的直线就是最好的直线,注意,损失函数是图中红色线段的平方和,而不是绿色线段,m代表样本的总数量,1/2是为了求导方便,可以与2次项约为1。

图 1线性回归举例
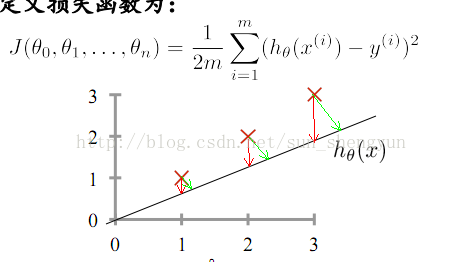
图2 损失函数
所以,线性回归的目标就是找到一组theta值,使损失函数最小,所以线性回归就变为求最小化J的问题。
最小化J常用的方法是梯度下降,梯度下降是逐步减小损失的过程,方向就是梯度(梯度/导数的方向是变化最快的方向),学习速率a是步长,可以理解为沿着梯度的方向每次变化多少,梯度下降的原理如图3所示,当走到最低点后,也就是损失最小的地方,此时梯度为0,theta将不再变化。
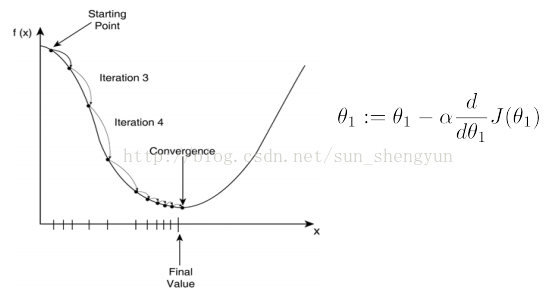
图3 梯度下降原理图
下面就用python来实现一个简单的线性回归模型

图4 读入数据并画出散点图
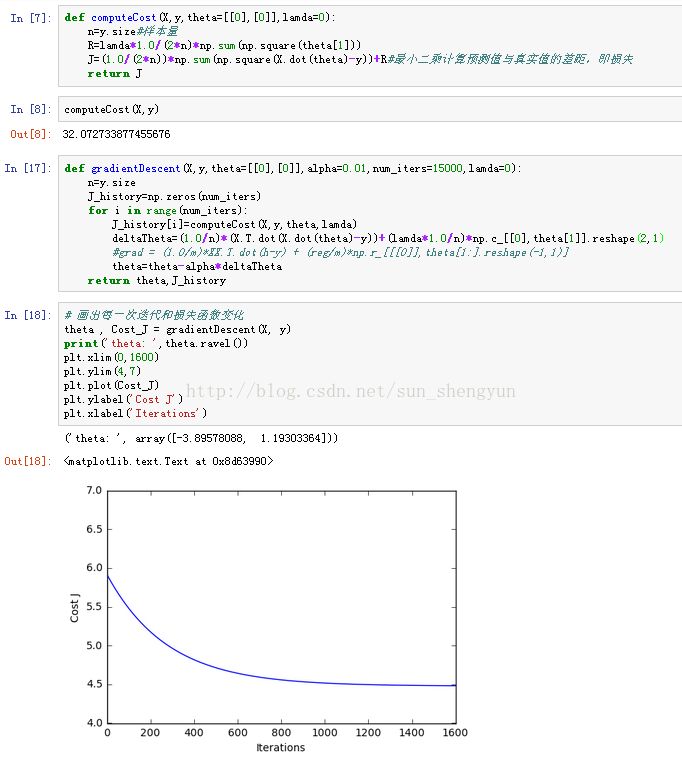
图5 定义损失函数、梯度下降函数并使用学习速率0.01画出损失变化图
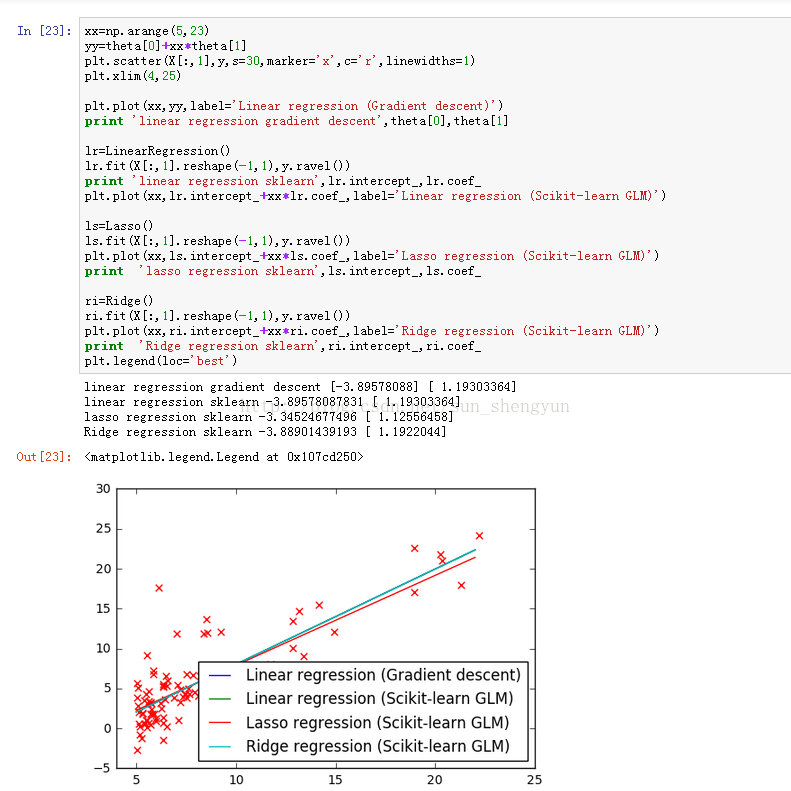
图6 画出自实现的线性回归与sklearn中的模型做比较
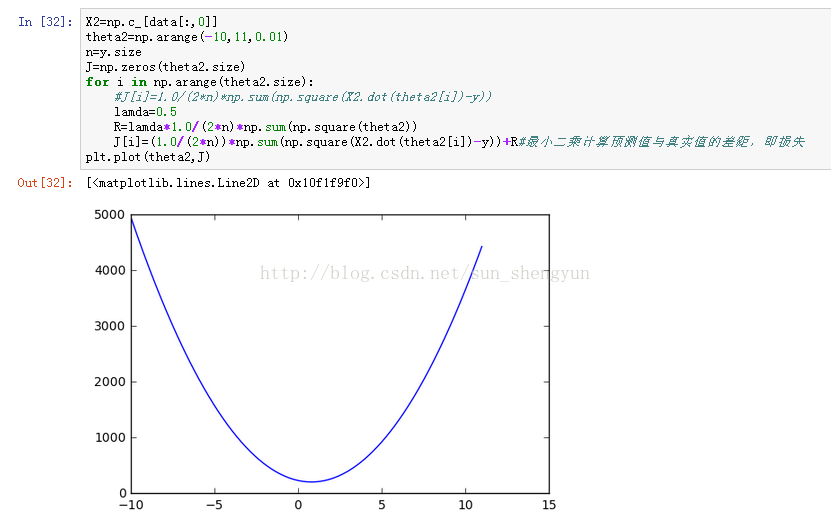
图7 损失函数与theta的变化关系
下面我们来看一下学习速率a和迭代次数对模型的影响,代码下所示
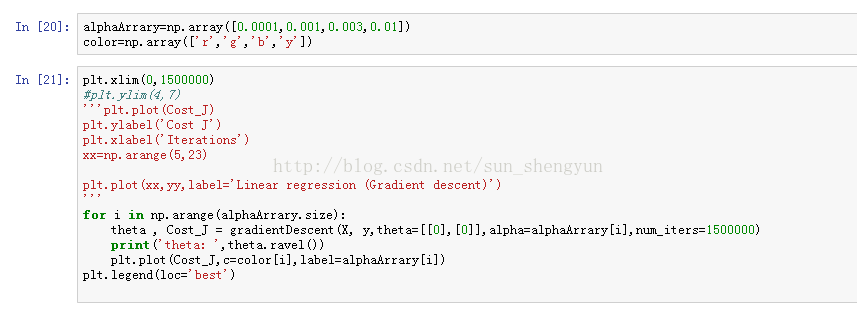
图8是迭代次数为20000,学习速率分别是0.0001,0.001,0.003,0.01时,cost随迭代次数的变化曲线,可以看出a越大,收敛越快,能够越快的取到最优解,而当a取0.0001和0.001时,所有迭代完成后,都没有达到最优;不断调大迭代次数,发现当迭代次数到500000时,a=0.0001仍没有收敛。Andrew在其机器课程中提到a的选择一般按照如下策略:从一个较小的a,比如0.001,然后每次增大3倍(0.003,0.01……)在训练集开始尝试,画出迭代次数与cost的变化曲线,取一个略小于最大值(使cost下降最快)的a应用在测试集,这样能加快训练速度。如果a的值取的太大会怎样,图14画出a取0.03时的变化曲线,可以看出损失函数不能收敛,当a太大时,会出现震荡不收敛的情况,我们可以这样来理解,如果a取100000000,在向下的时候,因为步子太大,就可能跨过最低点,甚至超过对称点,再往上走。
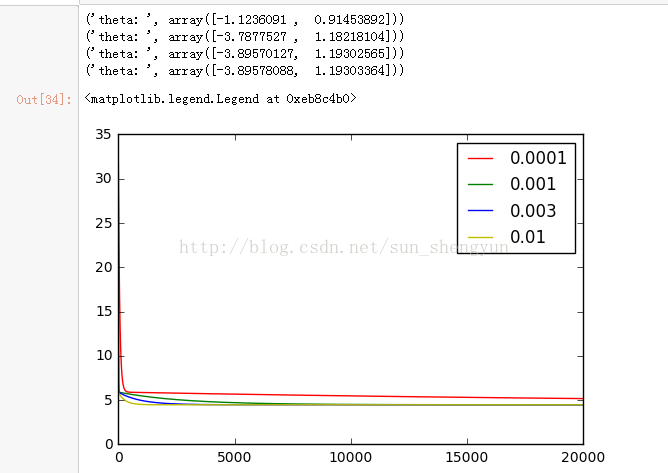
图8 迭代20000次
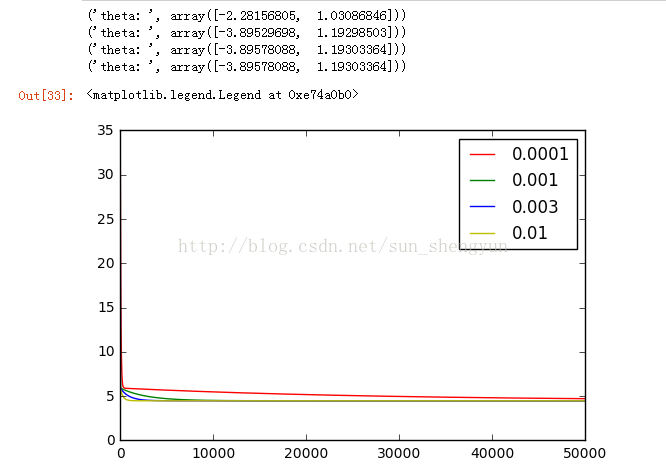
图9 迭代50000次

图10迭代100000次
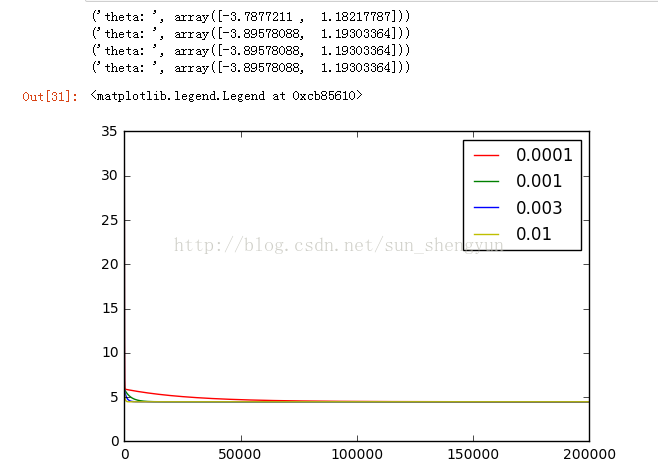
图11迭代200000次
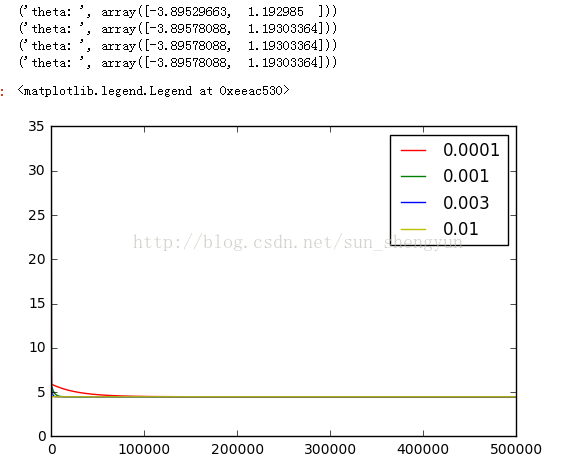
图12迭代500000次
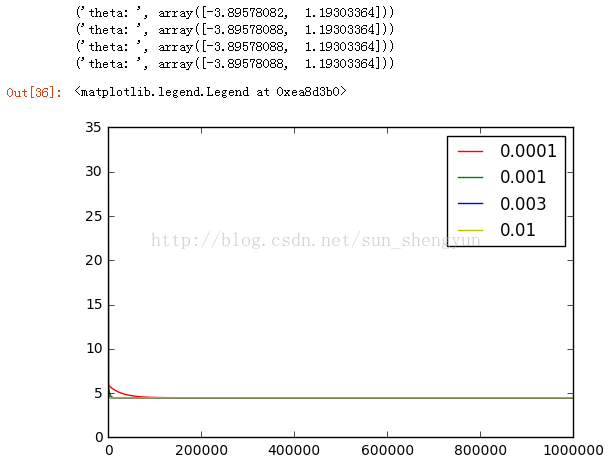
图13迭代1000000次

图14 a=0.03
如何去衡量一条直线是否是最好,在回归问题中一般用预测值与真实值之间的距离来定义损失函数,如图2所示,使损失函数值最小的直线就是最好的直线,注意,损失函数是图中红色线段的平方和,而不是绿色线段,m代表样本的总数量,1/2是为了求导方便,可以与2次项约为1。
图 1线性回归举例
图2 损失函数
所以,线性回归的目标就是找到一组theta值,使损失函数最小,所以线性回归就变为求最小化J的问题。
最小化J常用的方法是梯度下降,梯度下降是逐步减小损失的过程,方向就是梯度(梯度/导数的方向是变化最快的方向),学习速率a是步长,可以理解为沿着梯度的方向每次变化多少,梯度下降的原理如图3所示,当走到最低点后,也就是损失最小的地方,此时梯度为0,theta将不再变化。
图3 梯度下降原理图
下面就用python来实现一个简单的线性回归模型
图4 读入数据并画出散点图
图5 定义损失函数、梯度下降函数并使用学习速率0.01画出损失变化图
图6 画出自实现的线性回归与sklearn中的模型做比较
图7 损失函数与theta的变化关系
下面我们来看一下学习速率a和迭代次数对模型的影响,代码下所示
图8是迭代次数为20000,学习速率分别是0.0001,0.001,0.003,0.01时,cost随迭代次数的变化曲线,可以看出a越大,收敛越快,能够越快的取到最优解,而当a取0.0001和0.001时,所有迭代完成后,都没有达到最优;不断调大迭代次数,发现当迭代次数到500000时,a=0.0001仍没有收敛。Andrew在其机器课程中提到a的选择一般按照如下策略:从一个较小的a,比如0.001,然后每次增大3倍(0.003,0.01……)在训练集开始尝试,画出迭代次数与cost的变化曲线,取一个略小于最大值(使cost下降最快)的a应用在测试集,这样能加快训练速度。如果a的值取的太大会怎样,图14画出a取0.03时的变化曲线,可以看出损失函数不能收敛,当a太大时,会出现震荡不收敛的情况,我们可以这样来理解,如果a取100000000,在向下的时候,因为步子太大,就可能跨过最低点,甚至超过对称点,再往上走。
图8 迭代20000次
图9 迭代50000次
图10迭代100000次
图11迭代200000次
图12迭代500000次
图13迭代1000000次
图14 a=0.03

相关文章推荐
- 关于Python的属性、参数、方法的解释、区别
- XGBoost-Python完全调参指南-参数解释篇
- XGBoost-Python完全调参指南-参数解释篇
- Python:SQLMAP参数中文解释
- XGBoost-Python完全调参指南-参数解释篇
- XGBoost-Python完全调参指南-参数解释篇
- python decimal.quantize()参数rounding的各参数解释与行为
- Python中类的定义和参数解释
- Python:SQLMAP参数中文解释
- XGBoost-Python完全调参指南-参数解释篇
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
- XGBoost-Python完全调参指南-参数解释篇
- XGBoost-Python完全调参指南-参数解释篇
- XGBoost-Python完全调参指南-参数解释篇
- XGBoost-Python完全调参指南-参数解释篇
- python机器学习 scikit learn svm 中关于svc函数的参数解释
- XGBoost-Python完全调参指南-参数解释篇
- Python scikit-learn 模块svc方法的参数解释
- python中的 range() 函数参数解释应用
- XGBoost-Python完全调参指南-参数解释篇