对锦标赛算法与完美洗牌的分析
2016-12-09 21:44
309 查看
如果要在n个数据中挑选出第一大和第二大的数据(要求输出数据所在位置和值),使用什么方法比较的次数最少?我们可以从体育锦标赛中受到启发。
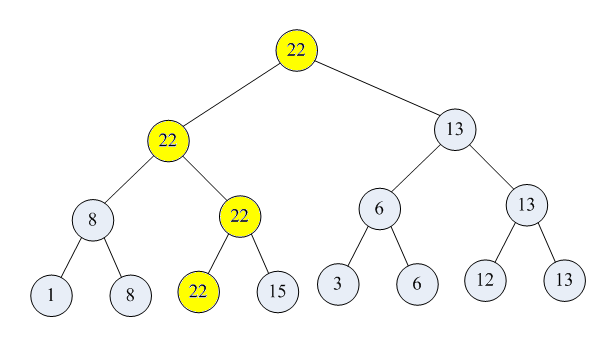
如图【1.png】所示,8个选手的锦标赛,先两两捉对比拼,淘汰一半。优胜者再两两比拼…直到决出第一名。
第一名输出后,只要对黄色标示的位置重新比赛即可。
下面的代码实现了这个算法(假设数据中没有相同值)。
代码中需要用一个数组来表示图中的树(注意,这是个满二叉树,不足需要补齐)。它不是存储数据本身,而是存储了数据的下标。
第一个数据输出后,它所在的位置被标识为-1
蓝桥杯上的一个填空题,感觉想法很好。
用一个b数组来存放这些数的下标,为空的地方就赋值为-1,然后通过左右子树不断的比较,将大数放到父亲节点,一直到根节点,先输出最大数,然后进行第二次比较,从根节点一直往下,把较大的数继续放到父亲节点,把第一次的最大数覆盖,一直到根节点,再输出第二大的数。
代码如下:
void perfect_shuffle2(int *a,int n) {
int t,i;
if (n == 1) {
t = a[1];
a[1] = a[2];
a[2] = t;
return;
}
int n2 = n * 2, n3 = n / 2;
if (n % 2 == 1) { //奇数的处理
t = a
;
for (i = n + 1; i <= n2; ++i) {
a[i - 1] = a[i];
}
a[n2] = t;
--n;
}
//到此n是偶数
for (i = n3 + 1; i <= n; ++i) {
t = a[i];
a[i] = a[i + n3];
a[i + n3] = t;
}
// [1.. n /2]
perfect_shuffle2(a, n3);
perfect_shuffle2(a + n, n3);
}
如图【1.png】所示,8个选手的锦标赛,先两两捉对比拼,淘汰一半。优胜者再两两比拼…直到决出第一名。
第一名输出后,只要对黄色标示的位置重新比赛即可。
下面的代码实现了这个算法(假设数据中没有相同值)。
代码中需要用一个数组来表示图中的树(注意,这是个满二叉树,不足需要补齐)。它不是存储数据本身,而是存储了数据的下标。
第一个数据输出后,它所在的位置被标识为-1
蓝桥杯上的一个填空题,感觉想法很好。
用一个b数组来存放这些数的下标,为空的地方就赋值为-1,然后通过左右子树不断的比较,将大数放到父亲节点,一直到根节点,先输出最大数,然后进行第二次比较,从根节点一直往下,把较大的数继续放到父亲节点,把第一次的最大数覆盖,一直到根节点,再输出第二大的数。
代码如下:
#include<iostream>
#include<cstdio>
#include<cstdlib>
using namespace std;
void pk(int* a, int* b, int n, int k, int v)
{
int k1 = k*2 + 1;
int k2 = k1 + 1;
if(k1>=n || k2>=n){
b[k] = -1;
return;
}
if(b[k1]==v)
pk(a,b,n,k1,v);
else
pk(a,b,n,k2,v);
//重新比较
if(b[k1]<0){
if(b[k2]>=0)
b[k] = b[k2];
else
b[k] = -1;
return;
}
if(b[k2]<0){
if(b[k1]>=0)
b[k] = b[k1];
else
b[k] = -1;
return;
}
if(a[b[k1]]>a[b[k2]]) //填空
b[k] = b[k1];
else
b[k] = b[k2];
}
//对a中数据,输出最大,次大元素位置和值
void f(int* a, int len)
{
int n = 1;
while(n<len) n *= 2;
int* b = (int*)malloc(sizeof(int*) * (2*n-1));
int i;
for(i=0; i<n; i++){
if(i<len)
b[n-1+i] = i;
else
b[n-1+i] = -1;
}
//从最后一个向前处理
for(i=2*n-1-1; i>0; i-=2){
if(b[i]<0){
if(b[i-1]>=0)
b[(i-1)/2] = b[i-1];
else
b[(i-1)/2] = -1;
}
else{
if(a[b[i]]>a[b[i-1]])
b[(i-1)/2] = b[i];
else
b[(i-1)/2] = b[i-1];
}
}
//输出树根
printf("%d : %d\n", b[0], a[b[0]]);
//值等于根元素的需要重新pk
pk(a,b,2*n-1,0,b[0]);
//再次输出树根
printf("%d : %d\n", b[0], a[b[0]]);
free(b);
}
int main()
{
int a[] = {54,55,18,16,122,17,30,9,58};
f(a,9);
}a1, a2,a3,a4,b1,b2,b3,b4我们先要把前半段的后2个元素(a3,a4)与后半段的前2个元素(b1,b2)交换,得到a1,a2,b1,b2,a3,a4,b3,b4。于是,我们分别求解子问题A (a1,a2,b1,b2)和子问题B (a3,a4,b3,b4)就可以了。如果n = 5,是偶数怎么办?我们原始的数组是a1,a2,a3,a4,a5,b1,b2,b3,b4,b5,我们先把a5拎出来,后面所有元素前移,再把a5放到最后,变为a1,a2,a3,a4,b1,b2,b3,b4,b5,a5。可见这时最后两个元素b5,a5已经是我们要的结果了,所以我们只要考虑n=4就可以了。那么复杂度怎么算? 每次,我们交换中间的n个元素,需要O(n)的时间,n是奇数的话,我们还需要O(n)的时间先把后两个元素调整好,但这步影响总体时间复杂度。所以,无论如何都是O(n)的时间复杂度。于是我们有 T(n) = T(n / 2) + O(n) 这个就是跟归并排序一样的复杂度式子,最终复杂度解出来T(n) = O(nlogn)。空间的话,我们就在数组内部折腾的,所以是O(1)。(当然没有考虑递归的栈的空间)代码://时间O(nlogn) 空间O(1) 数组下标从1开始void perfect_shuffle2(int *a,int n) {
int t,i;
if (n == 1) {
t = a[1];
a[1] = a[2];
a[2] = t;
return;
}
int n2 = n * 2, n3 = n / 2;
if (n % 2 == 1) { //奇数的处理
t = a
;
for (i = n + 1; i <= n2; ++i) {
a[i - 1] = a[i];
}
a[n2] = t;
--n;
}
//到此n是偶数
for (i = n3 + 1; i <= n; ++i) {
t = a[i];
a[i] = a[i + n3];
a[i + n3] = t;
}
// [1.. n /2]
perfect_shuffle2(a, n3);
perfect_shuffle2(a + n, n3);
}

相关文章推荐
- Centos 6.5下C连接MySQL测试
- 读《小王子》
- Python脚本之间调用
- Java中的Lock
- BigDecimal的使用举例,包括阶乘的相加求法思路
- android实现MIUI的时钟效果
- 网络爬虫中的Unicode码解决[实例]
- 排序lib
- Dvwa系列之csrf
- java如何输出一个对象的引用名
- R语言实战笔记--第二章 数据类型及结构
- 个人笔记
- 第十六周 项目1--验证算法(3)--冒泡排序
- 小白学《神经网络与深度学习》笔记之四-深度学习的常用方法(2)
- img标签使用绝对路径无法显示图片
- Python IDLE快捷键一览
- httpclient的get和post
- 模仿了一个夸张的商品倒计时效果,设计的精简当然也很丑,只是为了检测自己说明问题
- 快速申请Android6.0权限教程!
- 机器学习和数据挖掘推荐书单及简介