扬帆起航,再踏征程(一)
2016-12-08 21:39
246 查看
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/53525075 冷血之心的博客)
数据结构与算法:
1、以最少的代码实现单链表反转,需要自己创建节点。
/*
* 翻转链表(遍历)
* 从头到尾遍历原链表,每遍历一个结点,
* 将其摘下放在新链表的最前端。
* 注意链表为空和只有一个结点的情况。时间复杂度为O(n)
*/
public static Node reverseNode(Node head){
// 如果链表为空或只有一个节点,无需反转,直接返回原链表表头
if(head == null || head.next == null)
return head;
Node reHead = null;
Node cur = head;
while(cur!=null){
Node reCur = cur; // 用reCur保存住对要处理节点的引用
cur = cur.next; // cur更新到下一个节点
reCur.next = reHead; // 更新要处理节点的next引用
reHead = reCur; // reHead指向要处理节点的前一个节点
}
return reHead;
}
// 翻转递归(递归)
// 递归的精髓在于你就默认reverseListRec已经成功帮你解决了子问题了!但别去想如何解决的
// 现在只要处理当前node和子问题之间的关系。最后就能圆满解决整个问题。
/*
head
1 -> 2 -> 3 -> 4
head
1--------------
|
4 -> 3 -> 2 // Node reHead = reverseListRec(head.next);
reHead head.next
4 -> 3 -> 2 -> 1 // head.next.next = head;
reHead
4 -> 3 -> 2 -> 1 -> null // head.next = null;
reHead
*/
public static Node reverseNodeRec(Node head){
if(head == null || head.next == null){
return head;
}
Node reHead = reverseNodeRec(head.next);
head.next.next = head; // 把head接在reHead串的最后一个后面
head.next = null; // 防止循环链表
return reHead;
}
2、给出一个二叉树,不能使用递归的方式,以二叉树的高度输出每个节点的值。在此基础上,如何在每个高度结束之后,输入一个换行符?
/***********************************************************************
4.分层遍历二叉树(按层次从上往下,从左往右): levelTraversal
**********************************************************************/
/**
* 分层遍历二叉树(按层次从上往下,从左往右)迭代
* 相当于广度优先搜索,使用队列实现。队列初始化,将根节点压入队列。当队列不为空,进行如下操作:弹出一个节点
* ,访问,若左子节点或右子节点不为空,将其压入队列
*/
public static void levelTraversal(TreeNode root){
if(root==null)
return ;
LinkedList<TreeNode> queue = new LinkedList<TreeNode>();
queue.add(root);
while(!queue.isEmpty()){
TreeNode cur = queue.remove();
System.out.print(cur.val+" ");
if(cur.left!=null)
queue.add(cur.left);
if(cur.right!=null)
queue.add(cur.right);
}
}
/**
* 分层遍历二叉树,并且实现在每个高度结束之后,输入一个换行符
* @param root
*/
public static void levelTraversal2(TreeNode root){
if(root==null)
return ;
Queue<TreeNode> queue = new LinkedList<TreeNode>();
TreeNode cur = root;
queue.add(cur);
int currentLevelNodeNums = 1;
int nextLevelNodeNums = 0;
while(!queue.isEmpty()){
TreeNode reCur = queue.remove();
System.out.print(reCur.val+" ");
currentLevelNodeNums--;
if(reCur.left!=null){
queue.add(reCur.left);
nextLevelNodeNums++;
}
if(reCur.right!=null){
queue.add(reCur.right);
nextLevelNodeNums++;
}
if(currentLevelNodeNums==0){
System.out.println();
currentLevelNodeNums = nextLevelNodeNums;
nextLevelNodeNums = 0;
}
}
}
数据库:
1、MongoDB数据库的优缺点分析?
答:MongoDB是面向文档的数据库,mysql是传统的关系型数据库。
优点:保证访问速度,访问时数据库不会被锁死;
文档结构的存储方式,数据存储在一个文档中,更利于管理,能够更便捷的获取数据;
使用JSON风格语法,相对于SQL来说,更加直观,容易理解和掌握;
性能优越,访问速度快。
缺点:不支持事务操作,空间占用大。
2、SQL语句中查询每个年龄有几个用户。
select count(*)from table group by age
3、MySQL中两种表类型MyISAM和InnoDB的区别?
MyISAM不支持事务,InnoDB是事务类型的存储引擎
MyISAM只支持表级锁,BDB支持页级锁和表级锁,默认为页级锁;而InnoDB支持行级锁和表级锁,默认为行级锁
MyISAM引擎不支持外键,InnoDB支持外键
MyISAM引擎的表在大量高并发的读写下会经常出现表损坏的情况
对于count( )查询来说MyISAM更有优势
InnoDB是为处理巨大数据量时的最大性能设计,它的CPU效率可能是任何其它基于磁盘的关系数据库引擎所不能匹敌的
MyISAM支持全文索引(FULLTEXT),InnoDB不支持
MyISAM引擎的表的查询、更新、插入的效率要比InnoDB高
最主要的区别是:MyISAM表不支持事务、不支持行级锁、不支持外键。
InnoDB表支持事务、支持行级锁、支持外键。
排序:
1、将一个数组排序输出。
答:关于排序算法,参考本博客:
“深入理解”—选择排序算法
“深入理解”—交换排序算法
“深入理解”—插入排序算法
git:
1、切换分支命令?
touch README.md
git init
git add README.md
git commit -m "first commit"
git remote add origin https://github.com/BrentHuang/MyRepo.git git push -u origin master
在本地新建一个分支: git branch Branch1
切换到你的新分支: git checkout Branch1
将新分支发布在github上: git push origin Branch1
在本地删除一个分支: git branch -d Branch1
在github远程端删除一个分支: git push origin :Branch1 (分支名前的冒号代表删除)
直接使用git pull和git push的设置
Git branch --set-upstream-to=origin/master master
git branch --set-upstream-to=origin/ThirdParty ThirdParty
git config --global push.default matching
Spring:
1、说说Spring的核心思想。解释IOC和AOP
答:Spring框架的核心就是IOC(控制反转)和AOP(面向切面编程)
IOC:将对象间的依赖关系交给Spring容器,使用配置文件来创建所依赖的对象。
AOP:使用配置文件创建所依赖的对象后,如果你要调用该对象的方法,并且想要在方法前/后 做一些处理,如:日志记录,性能统
计,安全控制,事务处理,异常处理等。则可以利用AOP实现。
即面向切面编程将功能代码从业务逻辑代码中划分出来,通过对这些行为的分离,我们希望可以将它们独立到非指导业务逻辑
的方法中,进而改变这些行为的时候不影响业务逻辑的代码。
Hibernate:
1、Hibernate有几级缓冲?分别是什么?有什么区别?
答:分为一级缓存(事务缓存)和二级缓存(应用缓存)。一级缓存是session对象的缓存,二级缓存是一个可插拔的缓存插件,由SessionFactory控制。
区别:
默认方式不同:一级缓存是内置的,不可卸载(默认是打开的);二级缓存是可插拔的(默认关闭)
作用范围不同:一级缓存是事务范围的缓存;二级缓存是进程范围或群集范围的缓存
适合存放的数据不同:二级缓存中适合存放很少被修改的数据、不是很重要的数据,允许偶尔出现并发问题的数据。
Struts2:
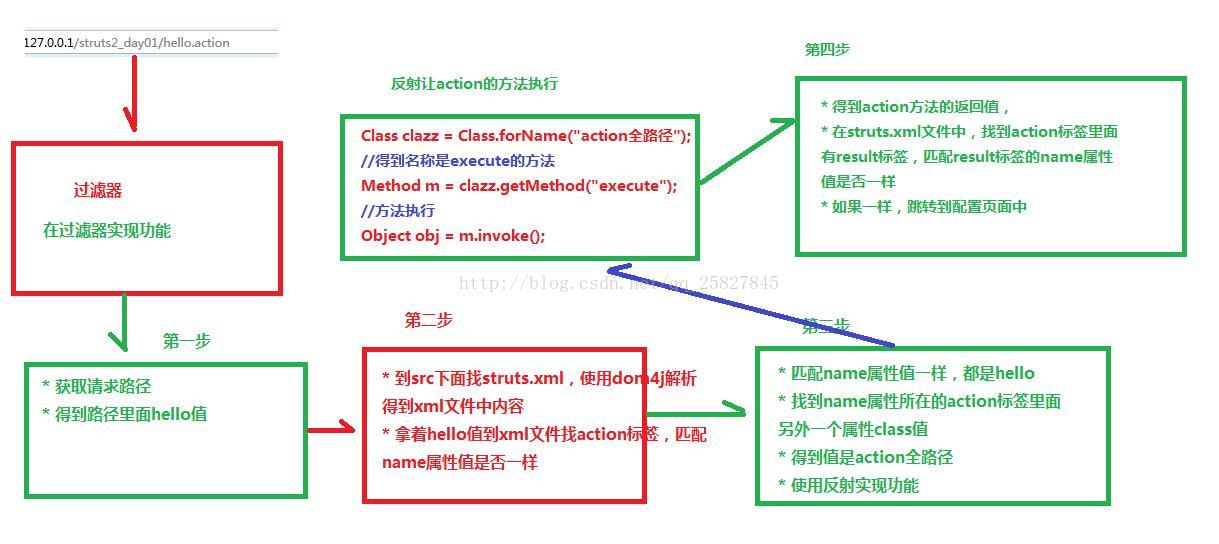
1、说说Struts2中接收请求后都发生了什么?
项目:
哪个项目做得最好?
答:你猜
如果对你有帮助,记得点赞哦~欢迎大家关注我的博客,可以加群366533258交流讨论哈~

相关文章推荐
- 扬帆起航,再踏征程(一)
- 扬帆起航,再踏征程(二)
- 扬帆起航,再踏征程(二)
- 扬帆起航,再踏征程(三)
- 扬帆起航,再踏征程(三)
- 扬帆起航,再踏征程(四)
- 扬帆起航,再踏征程(四)
- 北京十亿资金截留,“大龙芯”扬帆起航
- 我的CTO之征程起航啦
- 扬帆——起航
- Android零基础入门第15节:掌握Android Studio项目结构,扬帆起航
- 我的CTO之征程起航啦
- 有个程序猿要去当CEO了:(二)扬帆起航
- 大盘扬帆起航了?
- 刚来的兄弟,一起扬帆起航吧
- ACM征程再次起航!
- 三年了,重新扬帆起航
- Chris_C的技术世界扬帆起航
- MXNet官方文档教程(1):扬帆起航(Get Started)
- webpack入坑之旅(四)扬帆起航