基于N-gram的双向最大匹配中文分词
2016-12-05 16:16
1171 查看
• 摘要
这次实验的内容是中文分词。将一个句子的所有词用空格隔开,将一个字串转换为一个词序列。而我们用到的分词算法是基于字符串的分词方法中的正向最大匹配算法和逆向最大匹配算法。然后对两个方向匹配得出的序列结果中不同的部分运用Bi-gram计算得出较大概率的部分。最后拼接得到最佳词序列。
• 理论描述
中文分词指的是将一个汉字序列切分成一个一个单独的词。双向最大匹配算法是两个算法的集合,主要包括:正向最大匹配算法和逆向最大匹配算法.如果两个算法得到相同的分词结果,那就认为是切分成功,否则,就出现了歧义现象或者是未登录词问题。
正向最大匹配算法:从左到右将待分词文本中的最多个连续字符与词表匹配,如果匹配上,则切分出一个词。
逆向最大匹配算法:从右到左将待分词文本中的最多个连续字符与词表匹配,如果匹配上,则切分出一个词。
正向最大匹配算法和逆向最大匹配算法采用的思想是贪心策略。
N-gram模型思想:
模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积 。
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。
假设T是由词序列W1,W2,W3,…Wn组成的,那么
P(T)=P(W1W2W3…Wn)
=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
文章的思路来源于实验室的一个学长大大:
我也说说中文分词(上:基于字符串匹配)
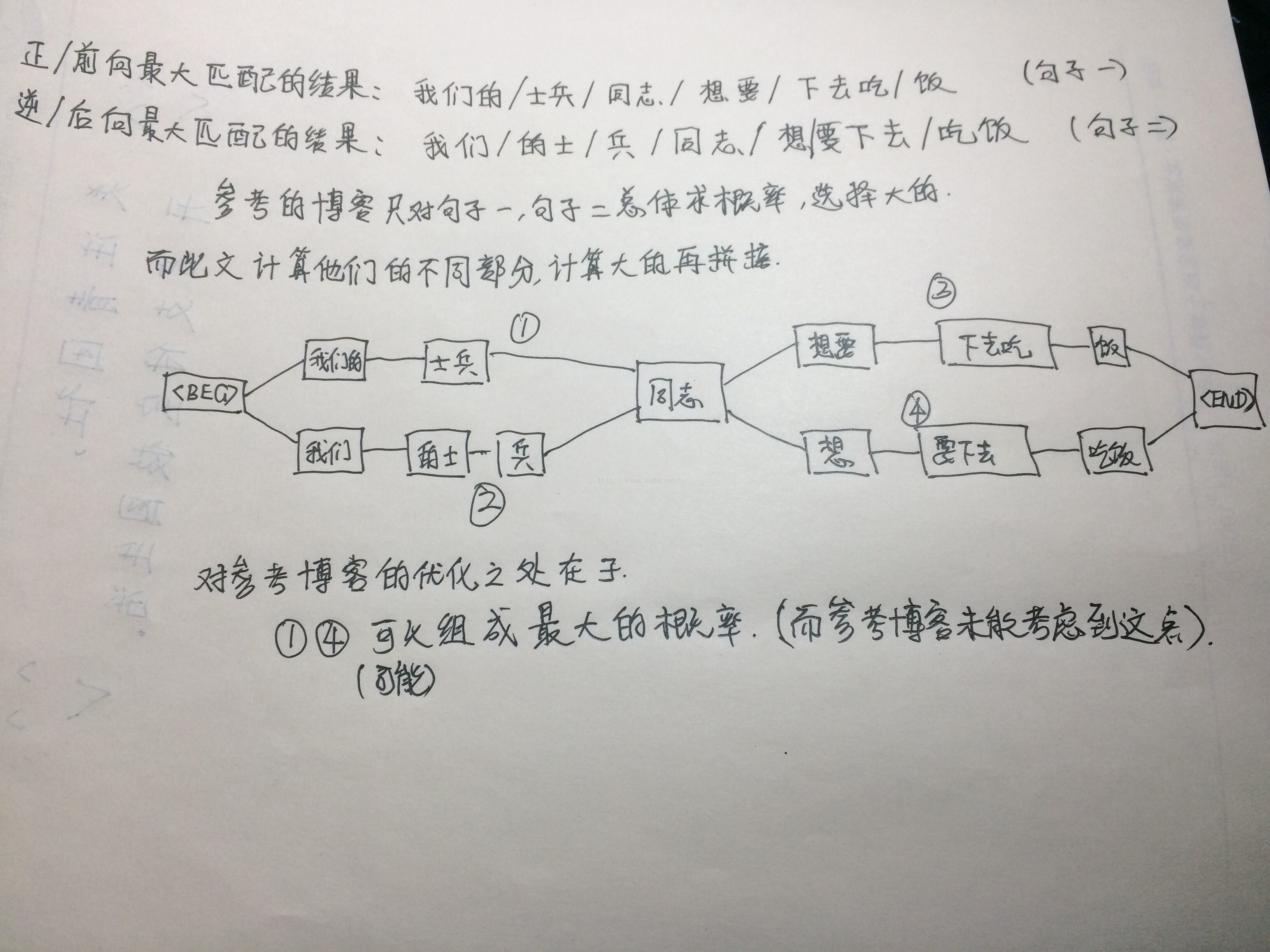
• 语料与程序运行环境
1.预料来源实验采用SIGHAN backoff2005中微软亚洲研究院的预料。共计2013011个词,有88107个不同的词。测试数据有16303个句子(用标点符号隔开)。
http://sighan.cs.uchicago.edu/bakeoff2005/
2.编程环境
程序使用Python语言编写,在Python 2.7环境下运行。代码在windows
8.1和Ubuntu 16.04均可运行。
• 程序设计
1.训练数据根据预料库得到每个词出现的个数和每个词后接词出现的个数。统计每个词是否出现,是为了根据前向最大匹配和逆向最大匹配得到得到句子的两个分词序列。而统计每个词出现的个数和每个词后接词出现的次数是为了根据bigram计算词序。代码中_WordDict和_NextCount分别统计词出现次数和词后接词出现的次数。加入了BEG和END作为句子起始和结束标志。
2.正向最大匹配算法和逆向最大匹配算法
根据上一步语料库中统计的WordDict,对训练集的每个句子分别用正向最大匹配算法和逆向最大匹配算法得到两个词序列。
设置一个span长度,作为默认的最大词长度。在config.py中设置span=12。
正向最大匹配从0位置开始,先找长度为span的词在不在WordDict中,不在的话span-1,如果找到就把位置向后平滑(匹配成功),如果一直到长度为1还没找到,那么单独一个字作为词(采用utf-8编码)。逆向最大匹配从最后一个位置向前找,代码类似。
3.N-gram算法
根据上一步正向最大匹配算法和逆向最大匹配算法得出的两个词序列,找出他们不同的部分,根据bigram算出不同部分的概率,选择较大的一种。然后把所有选择的序列拼接得到最终的句子。计算概率时做了拉普拉斯平滑。
4.评价算法
根据微软亚洲研究院提供的测试结果集和自己代码得出的结果集进行一行一行匹配。分别计算正确率P,召回率R和二者的调和平均数F。
• 实验结果
测试的句子有16303个句子,对每个句子进行匹配计算匹配词的个数,自己算的结果集中词的个数,官方给的结果集词的个数。从而算出正确率、召回率、F值,如下图。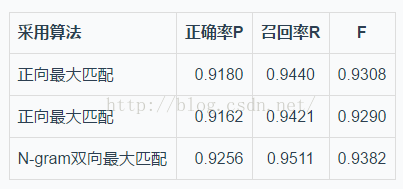
• 实验总结
1.歧义通过bigram对正向最大匹配和逆向最大匹配得到的两个词序列不同的词序列部分计算概率,选择大的拼接得到句子。这样可以消除部分的歧义。
2.未登录词
未登录词就是在词典中未出现的,但是是一个词语(新词)。如何识别新词是一个很重要的问题。我开始写的代码是将测试集中出现的单个连续的字(没有在词典中出现),如果他们出现次数超过一定程度便认定为新词。不过这样会把很多不是词语的词认定成新词,效果不太好。
运用动态规划的思想,可以把到一个词结尾的所有可能算出,得到最大的,然后拼接得到最大。而采用正向和逆向最大匹配得到两个序列,从不同的部分选择大的拼接相比较前一种有部分的局限性。
• 代码结构
config.py
# -*- coding:utf-8 -*- ''' Author: Qi Mo Created: November 12, 2016 Version: 1.0 Update: ''' train_data_path = './data/msr_training.utf8' test_data_path = './data/msr_test.utf8' test_result_path = './data/msr_test_result.utf8' test_gold_path = './data/msr_test_gold.utf8' Punctuation = [u'、',u'”',u'“',u'。',u'(',u')',u':',u'《',u'》',u';',u'!',u',',u'、'] span = 12 Number = [u'0',u'1',u'2',u'3',u'4',u'5',u'6',u'7',u'8',u'9',u'%',u'.'] English = [u'a',u'b',u'c',u'd',u'e',u'f',u'g',u'h',u'i',u'j',u'k',u'l',u'm',u'n',u'o',u'p',u'q',u'r',u's',u't',u'u',u'v',u'w',u'x',u'y',u'z'\ u'A',u'B',u'C',u'D',u'E',u'F',u'G',u'H',u'I',u'J',u'K',u'L',u'M',u'N',u'O',u'P',u'Q',u'R',u'S',u'T',u'U',u'V',u'W',u'X',u'Y',u'Z']
Evaluate.py
# -*- coding:utf-8 -*-
'''
Author: Qi Mo
Created: November 24, 2016
Version: 1.0
Update:
'''
from config import test_result_path
from config import test_gold_path
class Evaluate():
def __init__(self):
pass
def evaluate(self):
test_result_file = open(test_result_path)
test_gold_file = open(test_gold_path)
result_cnt = 0.0
gold_cnt = 0.0
right_cnt = 0.0
for line1,line2 in zip(test_result_file,test_gold_file):
result_list = line1.strip().decode('utf-8').split(' ')
gold_list = line2.strip().decode('utf-8').split(' ')
for words in gold_list:
if words == '':
gold_list.remove(words)
for words in gold_list:
if words == '':
result_list.remove(words)
result_cnt +=len(result_list)
gold_cnt +=len(gold_list)
for words in result_list:
if words in gold_list:
right_cnt +=1.0
gold_list.remove(words)
p = right_cnt / result_cnt
r = right_cnt / gold_cnt
F = 2.0 * p * r / (p + r)
print 'right_cnt: \t\t',right_cnt
print 'result_cnt: \t', result_cnt
print 'gold_cnt: \t\t', gold_cnt
print 'P: \t\t',p
print 'R: \t\t',r
print 'F: \t\t',F
if __name__ == '__main__':
E = Evaluate()
E.evaluate()PrePostNgram.py
代码结构
# -*- coding:utf-8 -*-
'''
Author: Qi Mo
Created: November 24, 2016
Version: 1.0
Update:
'''
# import uniout
import math
from config import train_data_path
from config import test_data_path
from config import test_result_path
from config import span
from config import Punctuation
from config import Number
from config import English
from Evaluate import Evaluate
class PrePostNgram():
def __init__(self):
self._WordDict = {}
self._NextCount = {}
self._NextSize = 0
self._WordSize = 0
def Training(self):
"""
读取训练集文件
得到每个词出现的个数 self._WordDict
得到每个词后接词出现的个数 self._NextCount
:return:
"""
print 'start training...'
self._NextCount[u'<BEG>'] = {}
traing_file = open(train_data_path)
traing_cnt = 0
for line in traing_file:
line = line.strip().decode('utf-8')
line = line.split(' ')
line_list = []
# 得到每个词出现的个数
for pos,words in enumerate(line):
if words != u'' and words not in Punctuation:
line_list.append(words)
traing_cnt += len(line_list)
for pos,words in enumerate(line_list):
if not self._WordDict.has_key(words):
self._WordDict[words] = 1
else:
self._WordDict[words] += 1
# 得到每个词后接词出现的个数
words1, words2 = u'',u''
if pos ==0:
words1, words2 = u'<BEG>',words
elif pos == len(line_list)-1:
words1, words2 = words,u'<END>'
else:
words1, words2 =words,line_list[pos+1]
if not self._NextCount.has_key(words1):
self._NextCount[words1] = {}
if not self._NextCount[words1].has_key(words2):
self._NextCount[words1][words2] = 1
else:
self._NextCount[words1][words2] += 1
traing_file.close()
self._NextSize = traing_cnt
print 'total training words length is: ',traing_cnt
print 'training done...'
self._WordSize = len(self._WordDict)
print "len _WordDict: ",len(self._WordDict)
print "len _NextCount: ",len(self._NextCount)
def SeparWords(self,mode):
print 'start SeparWords...'
test_file = open(test_data_path)
test_result_file = open(test_result_path,'w')
SenListCnt = 0
tmp_words = u''
SpecialDict = {}
for line in test_file:
# 编码方式改为utf-8
line = line.strip().decode('utf-8')
SenList = []
# 记录是否有英文或者数字的flag
flag = 0
for sentense in line:
if sentense in Number or sentense in English:
flag = 1
tmp_words += sentense
elif sentense in Punctuation:
if tmp_words != u'':
SenList.append(tmp_words)
SenListCnt += 1
SenList.append(sentense)
if flag==1:
SpecialDict[tmp_words] =1
flag = 0
tmp_words = u''
else:
if flag ==1:
SenList.append(tmp_words)
SenListCnt += 1
SpecialDict[tmp_words] = 1
flag = 0
tmp_words = sentense
else:
tmp_words += sentense
if tmp_words != u'':
SenList.append(tmp_words)
SenListCnt += 1
if flag == 1:
SpecialDict[tmp_words] = 1
tmp_words = u''
for sentense in SenList:
if sentense not in Punctuation and sentense not in SpecialDict:
if mode == 'Pre':
ParseList = self.PreMax(sentense)
elif mode == 'Post':
ParseList = self.PosMax(sentense)
else:
ParseList1 = self.PreMax(sentense)
ParseList2 = self.PosMax(sentense)
ParseList1.insert(0,u'<BEG>')
ParseList1.append(u'<END>')
ParseList2.insert(0, u'<BEG>')
ParseList2.append(u'<END>')
# 根据前向最大匹配和后向最大匹配得到得到句子的两个词序列(添加BEG和END作为句子的开始和结束)
# 记录最终选择后拼接得到的句子
ParseList = []
# CalList1和CalList2分别记录两个句子词序列不同的部分
CalList1 = []
CalList2 = []
# pos1和pos2记录两个句子的当前字的位置,cur1和cur2记录两个句子的第几个词
pos1=pos2=0
cur1=cur2=0
while(1):
if cur1 == len(ParseList1) and cur2 == len(ParseList2):
break
# 如果当前位置一样
if pos1 == pos2:
# 当前位置一样,并且词也一样
if len(ParseList1[cur1]) == len(ParseList2[cur2]):
pos1+=len(ParseList1[cur1])
pos2+=len(ParseList2[cur2])
# 说明此时得到两个不同的词序列,根据bigram选择概率大的
# 注意算不同的时候要考虑加上前面一个词和后面一个词,拼接的时候再去掉即可
if len(CalList1)>0:
CalList1.insert(0, ParseList[-1])
CalList2.insert(0, ParseList[-1])
if cur1<len(ParseList1)-1:
CalList1.append(ParseList1[cur1])
CalList2.append(ParseList2[cur2])
p1 = self.CalSegProbability(CalList1)
p2 = self.CalSegProbability(CalList2)
if p1 > p2:
CalList = CalList1
else:
CalList = CalList2
CalList.remove(CalList[0])
if cur1<len(ParseList1)-1:
CalList.remove(ParseList1[cur1])
for words in CalList:
ParseList.append(words)
CalList1 = []
CalList2 = []
ParseList.append(ParseList1[cur1])
cur1 += 1
cur2 += 1
# pos1相同,len(ParseList1[cur1])不同,向后滑动,不同的添加到list中
elif len(ParseList1[cur1]) > len(ParseList2[cur2]):
CalList2.append(ParseList2[cur2])
pos2 += len(ParseList2[cur2])
cur2 += 1
else:
CalList1.append(ParseList1[cur1])
pos1 += len(ParseList1[cur1])
cur1 += 1
else:
# pos1不同,而结束的位置相同,两个同时向后滑动
if pos1 +len(ParseList1[cur1]) == pos2 + len(ParseList2[cur2]):
CalList1.append(ParseList1[cur1])
CalList2.append(ParseList2[cur2])
pos1 += len(ParseList1[cur1])
pos2 += len(ParseList2[cur2])
cur1 += 1
cur2 += 1
elif pos1 + len(ParseList1[cur1]) > pos2+len(ParseList2[cur2]):
CalList2.append(ParseList2[cur2])
pos2 += len(ParseList2[cur2])
cur2 += 1
else:
CalList1.append(ParseList1[cur1])
pos1 += len(ParseList1[cur1])
cur1 += 1
ParseList.remove(u'<BEG>')
ParseList.remove(u'<END>')
for pos,words in enumerate(ParseList):
tmp_words += u' '+words
else:
tmp_words += u' '+sentense
test_result_file.write(tmp_words.encode('utf-8')+'\n')
tmp_words = u''
test_file.close()
test_result_file.close()
print 'SenList length: ', SenListCnt
print 'SeparWords done...'
def CalSegProbability(self,ParseList):
p = 0
# 由于概率很小,对连乘做了取对数处理转化为加法
for pos,words in enumerate(ParseList):
if pos<len(ParseList)-1:
# 乘以后面词的条件概率
word1, word2 = words, ParseList[pos+1]
if not self._NextCount.has_key(word1):
# 加1平滑
p += math.log(1.0 / self._NextSize)
else:
# 加1平滑
fenzi,fenmu = 1.0,self._NextSize
for key in self._NextCount[word1]:
if key == word2:
fenzi += self._NextCount[word1][word2]
fenmu += self._NextCount[word1][key]
p += math.log((fenzi / fenmu))
# 乘以第一个词的概率
if (pos == 0 and words!=u'<BEG>') or (pos==1 and ParseList[0]==u'<BEG>'):
if self._WordDict.has_key(words):
p += math.log(float(self._WordDict[words]) + 1 / self._WordSize + self._NextSize)
else:
# 加1平滑
p += math.log(1 / self._WordSize + self._NextSize)
return p
def PreMax(self,sentence):
"""
把每个句子正向最大匹配
"""
cur,tail = 0,span
ParseList = []
while(cur<tail and cur<=len(sentence)):
if len(sentence) < tail:
tail = len(sentence)
if tail == cur+1:
ParseList.append(sentence[cur:tail])
cur+=1
tail = cur + span
elif self._WordDict.has_key(sentence[cur:tail]):
ParseList.append(sentence[cur:tail])
cur=tail
tail=cur+span
else:
tail-=1
return ParseList
def PosMax(self,sentence):
"""
把每个句子后向最大匹配
:param sentence:
:return:
"""
cur = len(sentence)-span
tail = len(sentence)
if cur<0:
cur=0
ParseList = []
while(cur<tail and tail>0):
if tail == cur+1:
ParseList.append(sentence[cur:tail])
tail-=1
cur = tail - span
if cur<0:
cur=0
elif self._WordDict.has_key(sentence[cur:tail]):
ParseList.append(sentence[cur:tail])
tail=cur
cur = tail-span
if cur<0:
cur=0
else:
cur+=1
ParseList.reverse()
return ParseList
if __name__ == '__main__':
E = Evaluate()
p = PrePostNgram()
p.Training()
p.SeparWords('Pre')
print '*****'
print 'Pre Max'
E.evaluate()
print '*****'
p.SeparWords('Post')
print '*****'
print 'Post Max'
E.evaluate()
print '*****'
p.SeparWords('prepostBigram')
print '*****'
print 'PrePostSegBigram Max'
E.evaluate()
print '*****'

相关文章推荐
- 基于N-gram的双向最大匹配中文分词
- 中文分词常用算法之基于词典的双向最大匹配
- C#写中文基于词表的最大逆向匹配分词算法
- 中文分词基础原则及正向最大匹配法、逆向最大匹配法、双向最大匹配法的分析
- 中文分词引擎 java 实现 — 正向最大、逆向最大、双向最大匹配法
- 中文分词实现——双向最大匹配
- 中文分词基础原则及正向最大匹配法、逆向最大匹配法、双向最大匹配法的分析
- 基于最大长度词语匹配的简单的汉语分词方法
- 正向最大匹配中文分词算法
- 一个简单最大正向匹配(Maximum Matching)MM中文分词算法的实现
- 基于.Net Framework 3.5的Lucene.Net 中文词组匹配分词器
- NLP: 中文分词算法--正向最大匹配 Forward Maximum Matching
- 一个简单最大正向匹配(Maximum Matching)MM中文分词算法的实现
- 中文分词算法之最大逆向匹配法
- 基于Tire树和最大概率法的中文分词功能的Java实现
- 用正向和逆向最大匹配算法进行中文分词
- 基于Tire树和最大概率法的中文分词功能的Java实现
- NLP中文信息处理---正向最大匹配法分词
- 反向最大匹配中文分词版本一
- 用PHP实现简单的反向最大匹配中文分词(代码)