HIVE与mysql的关系 hive常用命令整理 hive与hdfs整合过程
2016-12-04 00:17
543 查看
一、HIVE与mysql的关系
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive可以看成是从SQL到Map-Reduce的
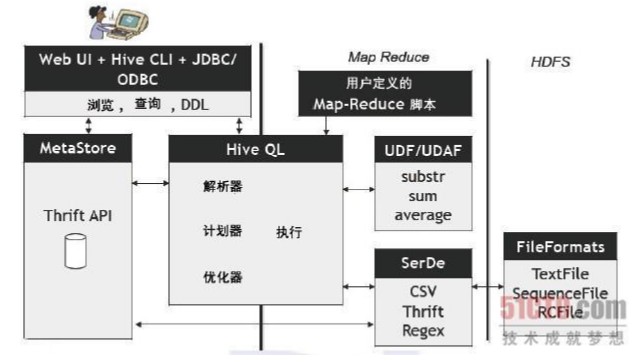
映射器
hive的组件和体系架构:
hive web接口启动:./hive --service hwi
浏览器访问:http://localhost:9999/hwi/
默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会话,则需要一个独立的元数据库,我们使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
Hive安装
内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
本地独立模式:在本地安装Mysql,把元数据放到Mysql内
远程模式:元数据放置在远程的Mysql数据库。
Hive的数据放在哪儿?
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的元数据保存在mysql中(deby)。
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
转:https://my.oschina.net/winHerson/blog/190131
二、hive常用命令
1. 开启行转列功能之后:
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; // 开启行转列功能, 前提必须开启打印列名功能
set hive.cli.print.row.to.vertical.num=1; // 设置每行显示的列数
2.使用过程中出错采用:
hive -hiveconf hive.root.logger=DEBUG,console //重启调试。
3. hive的三种启动方式区别:
1,hive 命令行模式,直接输入/hive/bin/hive的执行程序,或者输入 hive –service cli
用于linux平台命令行查询,查询语句基本跟mysql查询语句类似
2,hive web界面的启动方式,hive –service hwi
用于通过浏览器来访问hive,感觉没多大用途
3,hive 远程服务 (端口号10000) 启动方式,nohup hive –service hiveserver &
用java等程序实现通过jdbc等驱动的访问hive就用这种起动方式了,这个是程序员最需要的方式了
启动hive service :$HIVE_HOME/bin/hive --service hiveserver 10001 >/dev/null 2>/dev/null &
4. hive插入的2中方式:
基本的插入语法:
INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement
insert overwrite table test_insert select * from test_table;
对多个表进行插入操作:
FROM fromstatte
INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1
INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2
5.添加metastore启动脚本bin/hive-metastore.sh
#!/bin/sh
nohup ./hive --service metastore >> metastore.log 2>&1 &
echo $! > hive-metastore.pid
添加hive server启动脚本bin/hive-server.sh
nohup ./hive --service hiveserver >> hiveserver.log 2>&1 &
echo $! > hive-server.pid
启动metastore和hive server
./hive-metastore.sh
./hive-server.sh
转:http://blog.csdn.net/wulantian/article/details/38112359
三、hive的具体练习:(以下4个目标)
1. 第一普通的hdfs文件能导入到hive中,以供我们查询。
2. 第二hbase中的表,能导入hive中,以供我们查询。
3. 第三mysql中的表,能导入hive中,以供我们查询。
4. hive中的各种查询分析结果,能导入到mysql当中,以后页面展示。
本文是第一个目标:
第一普通的hdfs文件能导入到hive中,以供我们查询。同时,查询的结果能保存到一下3个地方:
1.将select的结果放到一个的的表格中(首先要用create table创建新的表格)
2.将select的结果放到本地文件系统中
3.将select的结果放到hdfs文件系统中
下面具体目标分别测试:
1. 普通的hdfs文件导入到hive中。
创建一个root目录下一个普通文件:
[root@db96 ~]# cat hello.txt
# This is a text txt
# by coco
# 2014-07-18
在hive中导入该文件:
hive> create table pokes(foo int,bar string);
OK
Time taken: 0.068 seconds
hive> load data local inpath '/root/hello.txt' overwrite into table pokes;
Copying data from file:/root/hello.txt
Copying file: file:/root/hello.txt
Loading data to table default.pokes
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/user/hive/warehouse/pokes
Table default.pokes stats: [numFiles=1, numRows=0, totalSize=59, rawDataSize=0]
OK
Time taken: 0.683 seconds
hive> select * from pokes;
OK
NULL NULL
NULL NULL
NULL NULL
NULL NULL
NULL NULL
Time taken: 0.237 seconds, Fetched: 5 row(s)
hive>
hive> load data local inpath '/root/hello.txt' overwrite into table test;
Copying data from file:/root/hello.txt
Copying file: file:/root/hello.txt
Loading data to table default.test
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/test
Failed with exception Unable to alter table.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
hive> show tables;
OK
hivetest
pokes
test
test3
Time taken: 1.045 seconds, Fetched: 4 row(s)
hive> select * from test;
OK
# This is a text txt NULL
# by coco NULL
# 2014-07-18 NULL
NULL
hello world!! NULL
Time taken: 1.089 seconds, Fetched: 5 row(s)
从上面看导入成功,但是查询的都是null,那是因为没有加分隔.test表默认的有terminated by '\t'
lines terminated by '\n' 分隔符,所以尽管有报错,数据也是插入的。
正确的导入语法为:
create table aaa(time string,myname string,yourname string) row format delimited
fields terminated by '\t' lines terminated by '\n' stored as textfile
hive> create table aaa(time string,myname string,yourname string) row format delimited
> fields terminated by '\t' lines terminated by '\n' stored as textfile;
OK
Time taken: 1.011 seconds
hive> load data local inpath '/root/aaaa.txt' overwrite
> into table aaa;
Copying data from file:/root/aaaa.txt
Copying file: file:/root/aaaa.txt
Loading data to table default.aaa
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/aaa
[Warning] could not update stats.
OK
Time taken: 2.686 seconds
hive> select * from aaa;
OK
20140723,yting,xmei NULL NULL
Time taken: 0.054 seconds, Fetched: 1 row(s)
2. 查询结果导出来。
从hive中把表中的数据导出来,保存成文本类型。
先检索索要的结果:
hive> select time from aaa;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0002, Tracking URL = http://db96:8088/proxy/application_1405999790746_0002/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:28:51,690 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:29:02,457 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.33 sec
MapReduce Total cumulative CPU time: 1 seconds 330 msec
Ended Job = job_1405999790746_0002
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.33 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 330 msec
OK
20140723,yting,xmei
Time taken: 26.281 seconds, Fetched: 1 row(s)
将查询结果输出至本地目录
hive> insert overwrite local directory '/tmp' select a.time from aaa a;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0004, Tracking URL = http://db96:8088/proxy/application_1405999790746_0004/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:34:28,474 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:34:35,128 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.27 sec
MapReduce Total cumulative CPU time: 1 seconds 270 msec
Ended Job = job_1405999790746_0004
Copying data to local directory /tmp
Copying data to local directory /tmp
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.27 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 270 msec
OK
Time taken: 21.943 seconds
可以看到/tmp下确实有一个文件,000000_0,该文件的内容为,我们查询看到的内容。
root@db96 tmp]# ll
总用量 4
-rw-r--r-- 1 root root 20 7月 23 16:34 000000_0
[root@db96 tmp]# vim 000000_0
20140723,yting,xmei
~
很多时候,我们在hive中执行select语句,希望将最终的结果保存到本地文件或者保存到hdfs系统中
或者保存到一个新的表中,hive提供了方便的关键词,来实现上面所述的功能。
1.将select的结果放到一个的的表格中(首先要用create table创建新的表格)
insert overwrite table test select uid,name from test2;
2.将select的结果放到本地文件系统中
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a;
3.将select的结果放到hdfs文件系统中
INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';
以上,我们实现了把普通本地的文本文件导入到hive中,并能实现相关的查询,并把查询结果导出到3个不同的地方。
具体示例:
hive> select a.time from aaa a;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0005, Tracking URL = http://db96:8088/proxy/application_1405999790746_0005/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:47:42,295 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:47:49,567 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.19 sec
MapReduce Total cumulative CPU time: 1 seconds 190 msec
Ended Job = job_1405999790746_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.19 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 190 msec
OK
a.time
20140723,yting,xmei
Time taken: 21.155 seconds, Fetched: 1 row(s)
hive> create table jieguo(content string);
OK
Time taken: 2.424 seconds
hive> insert overwrite table jieguo
> select a.time from aaa a;
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0006, Tracking URL = http://db96:8088/proxy/application_1405999790746_0006/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0006
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:49:50,689 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:49:57,329 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.3 sec
MapReduce Total cumulative CPU time: 1 seconds 300 msec
Ended Job = job_1405999790746_0006
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://db96:9000/hive/scratchdir/hive_2014-07-23_16-49-36_884_4745480606977792448-1/-ext-10000
Loading data to table default.jieguo
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/jieguo
Failed with exception Unable to alter table.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.3 sec HDFS Read: 221 HDFS Write: 90 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 300 msec
hive> show tables;
OK
tab_name
aaa
hello
hivetest
jieguo
pokes
test
test3
Time taken: 1.03 seconds, Fetched: 7 row(s)
hive> select * from jieguo;
OK
jieguo.content
20140723,yting,xmei
Time taken: 1.043 seconds, Fetched: 1 row(s)
转:http://blog.csdn.net/wulantian/article/details/38111701
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive可以看成是从SQL到Map-Reduce的
映射器
hive的组件和体系架构:
hive web接口启动:./hive --service hwi
浏览器访问:http://localhost:9999/hwi/
默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。为了支持多用户多会话,则需要一个独立的元数据库,我们使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
Hive安装
内嵌模式:元数据保持在内嵌的Derby模式,只允许一个会话连接
本地独立模式:在本地安装Mysql,把元数据放到Mysql内
远程模式:元数据放置在远程的Mysql数据库。
Hive的数据放在哪儿?
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的元数据保存在mysql中(deby)。
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
| 表名 | 说明 | 关联键 |
| TBLS | 所有hive表的基本信息(表名,创建时间,所属者等) | TBL_ID,SD_ID |
| TABLE_PARAM | 表级属性,(如是否外部表,表注释,最后修改时间等) | TBL_ID |
| COLUMNS | Hive表字段信息(字段注释,字段名,字段类型,字段序号) | SD_ID |
| SDS | 所有hive表、表分区所对应的hdfs数据目录和数据格式 | SD_ID,SERDE_ID |
| SERDE_PARAM | 序列化反序列化信息,如行分隔符、列分隔符、NULL的表示字符等 | SERDE_ID |
| PARTITIONS | Hive表分区信息(所属表,分区值) | PART_ID,SD_ID,TBL_ID |
| PARTITION_KEYS | Hive分区表分区键(即分区字段) | TBL_ID |
| PARTITION_KEY_VALS | Hive表分区名(键值) | PART_ID |
二、hive常用命令
1. 开启行转列功能之后:
set hive.cli.print.header=true; // 打印列名
set hive.cli.print.row.to.vertical=true; // 开启行转列功能, 前提必须开启打印列名功能
set hive.cli.print.row.to.vertical.num=1; // 设置每行显示的列数
2.使用过程中出错采用:
hive -hiveconf hive.root.logger=DEBUG,console //重启调试。
3. hive的三种启动方式区别:
1,hive 命令行模式,直接输入/hive/bin/hive的执行程序,或者输入 hive –service cli
用于linux平台命令行查询,查询语句基本跟mysql查询语句类似
2,hive web界面的启动方式,hive –service hwi
用于通过浏览器来访问hive,感觉没多大用途
3,hive 远程服务 (端口号10000) 启动方式,nohup hive –service hiveserver &
用java等程序实现通过jdbc等驱动的访问hive就用这种起动方式了,这个是程序员最需要的方式了
启动hive service :$HIVE_HOME/bin/hive --service hiveserver 10001 >/dev/null 2>/dev/null &
4. hive插入的2中方式:
基本的插入语法:
INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement
insert overwrite table test_insert select * from test_table;
对多个表进行插入操作:
FROM fromstatte
INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1
INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2
5.添加metastore启动脚本bin/hive-metastore.sh
#!/bin/sh
nohup ./hive --service metastore >> metastore.log 2>&1 &
echo $! > hive-metastore.pid
添加hive server启动脚本bin/hive-server.sh
nohup ./hive --service hiveserver >> hiveserver.log 2>&1 &
echo $! > hive-server.pid
启动metastore和hive server
./hive-metastore.sh
./hive-server.sh
转:http://blog.csdn.net/wulantian/article/details/38112359
三、hive的具体练习:(以下4个目标)
1. 第一普通的hdfs文件能导入到hive中,以供我们查询。
2. 第二hbase中的表,能导入hive中,以供我们查询。
3. 第三mysql中的表,能导入hive中,以供我们查询。
4. hive中的各种查询分析结果,能导入到mysql当中,以后页面展示。
本文是第一个目标:
第一普通的hdfs文件能导入到hive中,以供我们查询。同时,查询的结果能保存到一下3个地方:
1.将select的结果放到一个的的表格中(首先要用create table创建新的表格)
2.将select的结果放到本地文件系统中
3.将select的结果放到hdfs文件系统中
下面具体目标分别测试:
1. 普通的hdfs文件导入到hive中。
创建一个root目录下一个普通文件:
[root@db96 ~]# cat hello.txt
# This is a text txt
# by coco
# 2014-07-18
在hive中导入该文件:
hive> create table pokes(foo int,bar string);
OK
Time taken: 0.068 seconds
hive> load data local inpath '/root/hello.txt' overwrite into table pokes;
Copying data from file:/root/hello.txt
Copying file: file:/root/hello.txt
Loading data to table default.pokes
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/user/hive/warehouse/pokes
Table default.pokes stats: [numFiles=1, numRows=0, totalSize=59, rawDataSize=0]
OK
Time taken: 0.683 seconds
hive> select * from pokes;
OK
NULL NULL
NULL NULL
NULL NULL
NULL NULL
NULL NULL
Time taken: 0.237 seconds, Fetched: 5 row(s)
hive>
hive> load data local inpath '/root/hello.txt' overwrite into table test;
Copying data from file:/root/hello.txt
Copying file: file:/root/hello.txt
Loading data to table default.test
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/test
Failed with exception Unable to alter table.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
hive> show tables;
OK
hivetest
pokes
test
test3
Time taken: 1.045 seconds, Fetched: 4 row(s)
hive> select * from test;
OK
# This is a text txt NULL
# by coco NULL
# 2014-07-18 NULL
NULL
hello world!! NULL
Time taken: 1.089 seconds, Fetched: 5 row(s)
从上面看导入成功,但是查询的都是null,那是因为没有加分隔.test表默认的有terminated by '\t'
lines terminated by '\n' 分隔符,所以尽管有报错,数据也是插入的。
正确的导入语法为:
create table aaa(time string,myname string,yourname string) row format delimited
fields terminated by '\t' lines terminated by '\n' stored as textfile
hive> create table aaa(time string,myname string,yourname string) row format delimited
> fields terminated by '\t' lines terminated by '\n' stored as textfile;
OK
Time taken: 1.011 seconds
hive> load data local inpath '/root/aaaa.txt' overwrite
> into table aaa;
Copying data from file:/root/aaaa.txt
Copying file: file:/root/aaaa.txt
Loading data to table default.aaa
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/aaa
[Warning] could not update stats.
OK
Time taken: 2.686 seconds
hive> select * from aaa;
OK
20140723,yting,xmei NULL NULL
Time taken: 0.054 seconds, Fetched: 1 row(s)
2. 查询结果导出来。
从hive中把表中的数据导出来,保存成文本类型。
先检索索要的结果:
hive> select time from aaa;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0002, Tracking URL = http://db96:8088/proxy/application_1405999790746_0002/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:28:51,690 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:29:02,457 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.33 sec
MapReduce Total cumulative CPU time: 1 seconds 330 msec
Ended Job = job_1405999790746_0002
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.33 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 330 msec
OK
20140723,yting,xmei
Time taken: 26.281 seconds, Fetched: 1 row(s)
将查询结果输出至本地目录
hive> insert overwrite local directory '/tmp' select a.time from aaa a;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0004, Tracking URL = http://db96:8088/proxy/application_1405999790746_0004/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:34:28,474 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:34:35,128 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.27 sec
MapReduce Total cumulative CPU time: 1 seconds 270 msec
Ended Job = job_1405999790746_0004
Copying data to local directory /tmp
Copying data to local directory /tmp
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.27 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 270 msec
OK
Time taken: 21.943 seconds
可以看到/tmp下确实有一个文件,000000_0,该文件的内容为,我们查询看到的内容。
root@db96 tmp]# ll
总用量 4
-rw-r--r-- 1 root root 20 7月 23 16:34 000000_0
[root@db96 tmp]# vim 000000_0
20140723,yting,xmei
~
很多时候,我们在hive中执行select语句,希望将最终的结果保存到本地文件或者保存到hdfs系统中
或者保存到一个新的表中,hive提供了方便的关键词,来实现上面所述的功能。
1.将select的结果放到一个的的表格中(首先要用create table创建新的表格)
insert overwrite table test select uid,name from test2;
2.将select的结果放到本地文件系统中
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a;
3.将select的结果放到hdfs文件系统中
INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';
以上,我们实现了把普通本地的文本文件导入到hive中,并能实现相关的查询,并把查询结果导出到3个不同的地方。
具体示例:
hive> select a.time from aaa a;
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0005, Tracking URL = http://db96:8088/proxy/application_1405999790746_0005/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:47:42,295 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:47:49,567 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.19 sec
MapReduce Total cumulative CPU time: 1 seconds 190 msec
Ended Job = job_1405999790746_0005
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.19 sec HDFS Read: 221 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 190 msec
OK
a.time
20140723,yting,xmei
Time taken: 21.155 seconds, Fetched: 1 row(s)
hive> create table jieguo(content string);
OK
Time taken: 2.424 seconds
hive> insert overwrite table jieguo
> select a.time from aaa a;
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1405999790746_0006, Tracking URL = http://db96:8088/proxy/application_1405999790746_0006/
Kill Command = /usr/local/hadoop//bin/hadoop job -kill job_1405999790746_0006
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2014-07-23 16:49:50,689 Stage-1 map = 0%, reduce = 0%
2014-07-23 16:49:57,329 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.3 sec
MapReduce Total cumulative CPU time: 1 seconds 300 msec
Ended Job = job_1405999790746_0006
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://db96:9000/hive/scratchdir/hive_2014-07-23_16-49-36_884_4745480606977792448-1/-ext-10000
Loading data to table default.jieguo
rmr: DEPRECATED: Please use 'rm -r' instead.
Deleted hdfs://db96:9000/hive/warehousedir/jieguo
Failed with exception Unable to alter table.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 1.3 sec HDFS Read: 221 HDFS Write: 90 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 300 msec
hive> show tables;
OK
tab_name
aaa
hello
hivetest
jieguo
pokes
test
test3
Time taken: 1.03 seconds, Fetched: 7 row(s)
hive> select * from jieguo;
OK
jieguo.content
20140723,yting,xmei
Time taken: 1.043 seconds, Fetched: 1 row(s)
转:http://blog.csdn.net/wulantian/article/details/38111701

相关文章推荐
- HDFS、Hive、HBase常用命令整理
- mysql 常用命令用法总结脚本之家整理版
- Mysql安装过程--使用源码安装 & 常用命令
- linux、hdfs、hive、hbase常用命令
- mysql 常用命令用法总结积木学院整理版
- mysql常用命令整理
- mysql 常用命令整理
- MySQL 常用命令整理
- linux、hdfs、hive、hbase常用命令
- Mysql常用命令 详细整理版
- ubuntu中Mysql常用命令整理
- 一些常用的MySQL命令收集整理
- mysql 常用命令整理 - 持续更新
- mysql常用命令(不断整理中)
- MySQL下数据表混乱的字符编码处理以及一些处理字符编码时的常用命令整理
- 收集整理一些常用的MySQL命令
- 自整理MYSQL常用命令+短精简说明
- mysql常用监控脚本命令整理
- hive与hdfs整合过程
- mysql存储过程的创建,删除,调用及其他常用命令