EM算法
2016-12-03 21:15
113 查看
一.EM算法基本介绍
和一般的算法目标一样,我们用最大似然估计,对参数进行估计l(θ) = ∑P(yi|θ)
由于某些原因,你发现这个不好求(NP hard问题),于是引入了一个隐变量(latent variable),并把上式改写成了
【注:wiki上是这么介绍的:
The EM algorithm is used to find(locally) maximum
likelihood parameters of a statistical
model in cases where the equations
cannot be solved directly.】
l(θ) =
∑P(yi|θ) = ∑∑P(yj,zj|θ) [注:里面一个求和是对所有可能的z求和,外面的求和是对y]
然后通过神奇而伟大的Jensen不等式,问题变成了酱紫:

然后这里有一个非常巧妙的trick,既然我们不能直接最大化目标,我们就不断的最大化目标的下界,这样也能近似地最大化原始
目标,解释见下图,【图片来源http://blog.csdn.net/zouxy09/article/details/8537620】

以上,EM算法的一般步骤如下:
循环重复直到收敛
{
(E步)对于每一个i,计算 【计算期望】
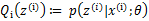
(M步)计算 【期望最大化】
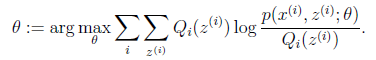
以上,EM算法的基本思想就是,在有隐变量z的情况下,由于隐变量z和输出y均未知,那么我们就先随机取定z,然后在该情况
下求出y,再利用y优化z;接着不断重复这个过程直到稳定。(?)
二.EM算法名称来由
在有隐变量的情况下,直接的公式推导是说:仍然是最大似然估计的思想,不过是将p(y|θ)表示成∑p(yi,zi|θ)的形式,然后用Jense不等式,然后不断优化原目标的下界,这个下界实际上就是隐变量的期望。所有算法称为最大期望,最大化的是隐变量的期望。

实际上,优化的下界是似然函数的期望。
另一种解释是,隐变量z和输出y均未知,那么先取定z,再使当前模型期望最大化得到当前模型,然后由模型再得到z;不断循环该过程。这个过程,wiki
是这么说的:
The EM iteration alternates between performing an expectation (E) step, which creates
a function for the expectation of the
log-likelihood evaluated
using the current estimate for the parameters, and a maximization (M) step, which computes parameters
maximizing the expected log-likelihood found on the E step.
These parameter-estimates are then used to determine the
distribution of the latent variables in the next E step.
也就是说:E步用当前估计参数计算对数似然函数的期望;M步通过最大化对数似然函数的期望来计算参数,然后这些参数用来决定下一步E中隐变量的
分布。
三.EM算法与隐变量
【wiki:Typically these models involve latentvariables in addition to unknown parameters and
known data observations. That is, either there are missing
values among the data, or the model can be formulated more simply by assuming the existence of additionalunobserved
data points.】
上面讲到,当原模型的优化目标(极大似然下)不可解时,通过隐变量改变转换目标形式,会简化原问题,得到(近似)(局部)最优解。那,怎么引入隐变量呢?
wiki上讲到,一个是数据中有missing values;一个是假设不可观察点的存在。第二种情况,后面高斯混合模型可能会进一步详细讲。
还有一种情况是,对于非监督学习,可以将输出y看成隐变量(毕竟对非监督学习y就是不可观测变量嘛),然后把x看成观测变量,然后沿用类似EM的思想,不断迭代优化x和y。【非监督学习也是EM的一大重要应用。】
四.EM算法与HMM
对隐马尔科夫(HMM)模型中的参数求解问题,所使用的Baum-Welch算法就是EM的特殊例子。对于HMM,首先我们要清楚其模型是什么:

然后我们要清楚问题是什么,这里我们只考虑学习问题,那么学习问题的目标就是:极大似然估计,似然函数是L(θ) = P(O|θ)。这里要明白的是,优化目标是在给定参数下使观测变量似然最大。然后通过因变量将似然函数表示成这样的形式
L(θ) = ∑P(O|I,θ)P(I|θ),这里的求和是对所有的隐变量I求和。到这里后面的求解可以完全代入EM算法了。另,这个算法有个名字叫Baum-Welch算法,其实就是EM算法
的特殊例子。
五.EM算法与非监督学习
em算法可以用于非监督学习。方式是将y看做隐变量,将x看做观测变量。另外,em的思想可以用于很多地方,而不是局限于非要期望最大化。基本思想是,有两个未知的互相依赖的变量,为了共同优化,我们可以固定一方,优化另一方,再不断迭代优化一方,循环这个过程知道稳定。六.EM算法与Kmeans
显然,kmeans是一个无监督的聚类算法,运用上面讲到的方法,将类别y看做隐变量,将features x看成观测变量。Kmeans的思想与EM一致,先初始化k个类别中心,根据中心点将各个点划分到k个类别,再更新每个簇的簇心,不断迭代。这也是通过选取初始值来不断优化的过程。七.EM算法与混合高斯模型
八. To be continued...
参考链接:wiki_expectation maximization
em算法

相关文章推荐
- EM算法
- EM算法
- R语言与点估计学习笔记(EM算法与Bootstrap法)
- (EM算法)The EM Algorithm
- 从最大似然到EM算法浅解
- 混合高斯模型和EM算法
- EM算法
- EM算法
- 【机器学习系列】三硬币问题——一个EM算法和Gibbs Sampling的例子
- EM算法之高斯混合模型详细推导过程
- ESL-chapter8-EM算法介绍1-混合高斯的例子
- EM算法
- EM算法资料总结
- GMM的EM算法实现
- 《统计学习方法,李航》:9、EM算法及其推广(1)
- EM算法收敛性的推导
- 《统计学习方法》:EM算法重点学习以及习题。
- 【机器学习】EM算法详细推导和讲解
- EM算法
- 统计学习方法笔记--EM算法--三硬币例子补充