深度优先搜索--以及图的基本操作
2016-11-29 17:34
405 查看
临接:如果两个顶点被同一条边连接,就称这个顶点是临接的。
路径:路径是边的序列
连通图:如果至少有一条路径可以连接起所有的顶点,那么称这个图是连通的。
邻接矩阵:邻接矩阵是一个二维数组,数组项表示两点之间是否存在遍。如果有N个顶点,邻接矩阵就是N*N的数组。
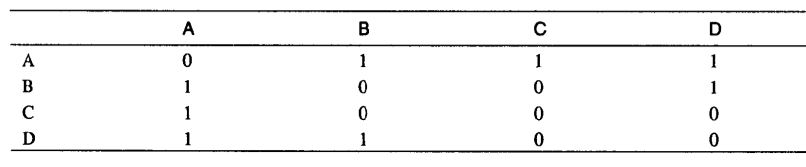
邻接表:
邻接表是一个链表数组(或者链表的链表)。每个单独的链表表示邻有哪些顶点与当前顶点邻接。

在图中添加顶点和边:
为了向图中添加顶点,必须用new生成一个新的顶点对象,然后插入到顶点数组vertexList中,在模拟真实世界的程序中,顶点可能包含许多的数据项,但是为了简便起见,假定顶点只包含单一的字符,因此顶点的创建可以使用下面的代码:
vertexList[nVerts++] = new Vertex(‘F’)
nVerts是当前的顶点数。
假定使用邻接矩阵并考虑在顶点1和顶点3之间加一条边,这些数字对应vertexList的下标,顶点存储在数组的对应位置。首次创建邻接矩阵adjMat时,初值为0,添加边的代码如下:
adiMat[1][3] = 1;
adjMat[3][1] = 1;
Graph类,它包含了创建了邻接矩阵和邻接表的方法,以向Graph对象插入顶点和边的方法。
class Graph
{
}
——————————————————————————————
搜索:有两种常用的方法可以用来搜索图:即深度优先搜索(DFS Depth-First Search)和广度优先搜索(BFS Breadth-First Search).它们最后都会到达所有连通的顶点。深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。
————————————————————————
深度优先搜索:
为了实现深度优先搜索,找一个起始点–本例为A点,需要做三件事:首先访问该顶点然后将其放入栈中,以便记住它,最后标记该点,这样就不会再访问它。
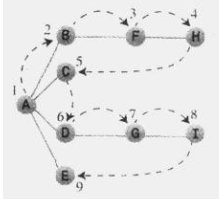
规则1:如果可能,访问一个邻接的未访问节点,标记它,并将其放入栈中。
规则2:当不能执行规则1时,如果栈不为空,就从栈中弹出一个顶点。
规则3:如果不能执行规则1和规则2,就完成了整个搜索过程。
从A开始,访问A,标记A,并将A放入栈中;下面访问B,标记B,将B放入栈中;同理,访问F,H…..
将H放入栈后,应用规则2,从栈中弹出H,这样又回到了顶点F。F叶没有与之相邻且未访问的顶点了,那么再弹出F,这时回到顶点B,此时只有顶点A在栈中。
然而A还有未访问的邻接点,所以访问的下一个节点是C,但是C又是这条路线的终点,所以从栈中弹出它,再次回到A点。接着访问D,G和I。当到达I时,把它们都弹出栈。现在回到A,然后访问E,最后再次回到A。
然而这次A也没有未访问的邻节点,所以把它也弹出栈,现在栈中已经没有顶点,应用规则3.
深度优先搜索的栈内容:

java代码:
深度优先搜索的关键在于能够找到与某一顶点邻接且没有访问过的顶点。;邻接矩阵是关键,找到指定顶点所在的行,从第一列开始向后寻找值为1的列;列号是临接顶点的好吗。检查这个顶点是否访问过,如果是这样,那么这就是要访问的下一个顶点。如果该行没有顶点既等于1(邻接)且又是访问的,那么与指定点相临接的顶点就全部访问过了。这个过程在getAdjUnvisitedVertex()方法中实现。
public int getAdjUnvisitedVertex(int v)
{
for (int i = 0; i < nVerts; i++)
现在开始考察Graph类中的dfs()方法,这个方法实际执行了深度优先搜索。下面会看到这段代码包含了前面提出的3条规则。它循环执行,直到栈为空,每次循环中,它做四件事:
1.用peek()方法检查栈顶的顶点。
2.试图找到这个顶点还未访问的邻接点。
3.如果没有找到,出栈。
4.如果找到这样的顶点,访问这个顶点,并把它放入栈。
public void dfs()
{
vertexList[0].wasVisited = true;
dispalyVertex(0);
theStack.push(0);
在dfs()的最后,重置了所有wasVisited标记位,这样就可以在稍后继续使用dfs()方法。栈此时已经为空,所以不需要重新设置。
——————————————————————
下面是创建图对象的代码。并在图中加入一些顶点和边,然后执行深度优先搜索。
————————————————————————————————————
图的操作完整代码:
路径:路径是边的序列
连通图:如果至少有一条路径可以连接起所有的顶点,那么称这个图是连通的。
邻接矩阵:邻接矩阵是一个二维数组,数组项表示两点之间是否存在遍。如果有N个顶点,邻接矩阵就是N*N的数组。
邻接表:
邻接表是一个链表数组(或者链表的链表)。每个单独的链表表示邻有哪些顶点与当前顶点邻接。
在图中添加顶点和边:
为了向图中添加顶点,必须用new生成一个新的顶点对象,然后插入到顶点数组vertexList中,在模拟真实世界的程序中,顶点可能包含许多的数据项,但是为了简便起见,假定顶点只包含单一的字符,因此顶点的创建可以使用下面的代码:
vertexList[nVerts++] = new Vertex(‘F’)
nVerts是当前的顶点数。
假定使用邻接矩阵并考虑在顶点1和顶点3之间加一条边,这些数字对应vertexList的下标,顶点存储在数组的对应位置。首次创建邻接矩阵adjMat时,初值为0,添加边的代码如下:
adiMat[1][3] = 1;
adjMat[3][1] = 1;
Graph类,它包含了创建了邻接矩阵和邻接表的方法,以向Graph对象插入顶点和边的方法。
class Graph
{
private final int MAX_VERTS = 20;
private Vertex vertexList[] ;
private int adjMat[][];
private int nVerts;
//.......................
public Graph()
{
vertexList = new Vertex[MAX_VERTS];
adjMat = new int[MAX_VERTS][MAX_VERTS];
nVerts = 0;
for (int i = 0; i < MAX_VERTS; i++)
for (int j = 0; j < MAX_VERTS; j++)
adjMat[i][j] = 0;
}
//.....................................
public void addVertex(char lab)
{
vertexList[nVerts++] =new Vertex(lab);
}
//........................................
public void addEdge(int start,int end)
{
adjMat[start][end] = 1;
adjMat[end][start] = 1;
}
//.............................
public void displayVertex(int v)
{
System.out.print(vertexList[v].label);
}}
——————————————————————————————
搜索:有两种常用的方法可以用来搜索图:即深度优先搜索(DFS Depth-First Search)和广度优先搜索(BFS Breadth-First Search).它们最后都会到达所有连通的顶点。深度优先搜索通过栈来实现,而广度优先搜索通过队列来实现。
————————————————————————
深度优先搜索:
为了实现深度优先搜索,找一个起始点–本例为A点,需要做三件事:首先访问该顶点然后将其放入栈中,以便记住它,最后标记该点,这样就不会再访问它。
规则1:如果可能,访问一个邻接的未访问节点,标记它,并将其放入栈中。
规则2:当不能执行规则1时,如果栈不为空,就从栈中弹出一个顶点。
规则3:如果不能执行规则1和规则2,就完成了整个搜索过程。
从A开始,访问A,标记A,并将A放入栈中;下面访问B,标记B,将B放入栈中;同理,访问F,H…..
将H放入栈后,应用规则2,从栈中弹出H,这样又回到了顶点F。F叶没有与之相邻且未访问的顶点了,那么再弹出F,这时回到顶点B,此时只有顶点A在栈中。
然而A还有未访问的邻接点,所以访问的下一个节点是C,但是C又是这条路线的终点,所以从栈中弹出它,再次回到A点。接着访问D,G和I。当到达I时,把它们都弹出栈。现在回到A,然后访问E,最后再次回到A。
然而这次A也没有未访问的邻节点,所以把它也弹出栈,现在栈中已经没有顶点,应用规则3.
深度优先搜索的栈内容:
java代码:
深度优先搜索的关键在于能够找到与某一顶点邻接且没有访问过的顶点。;邻接矩阵是关键,找到指定顶点所在的行,从第一列开始向后寻找值为1的列;列号是临接顶点的好吗。检查这个顶点是否访问过,如果是这样,那么这就是要访问的下一个顶点。如果该行没有顶点既等于1(邻接)且又是访问的,那么与指定点相临接的顶点就全部访问过了。这个过程在getAdjUnvisitedVertex()方法中实现。
public int getAdjUnvisitedVertex(int v)
{
for (int i = 0; i < nVerts; i++)
if(adjMat[v][i] ==1 && vertexList[i].wasVisited == false) return i; return -1; }
现在开始考察Graph类中的dfs()方法,这个方法实际执行了深度优先搜索。下面会看到这段代码包含了前面提出的3条规则。它循环执行,直到栈为空,每次循环中,它做四件事:
1.用peek()方法检查栈顶的顶点。
2.试图找到这个顶点还未访问的邻接点。
3.如果没有找到,出栈。
4.如果找到这样的顶点,访问这个顶点,并把它放入栈。
public void dfs()
{
vertexList[0].wasVisited = true;
dispalyVertex(0);
theStack.push(0);
while(!theStack.isEmpty())
{
int v = getAdjUnvisitedVertex(theStack.peek());
if(v == -1)
theStack.pop();
else
{
vertexList[v].wasVisited = true;
displayVertex(v);
theStack.push(v);
}
}
for (int i = 0; i < nVerts; i++)
vertexList[i].wasVisited = false;
}在dfs()的最后,重置了所有wasVisited标记位,这样就可以在稍后继续使用dfs()方法。栈此时已经为空,所以不需要重新设置。
——————————————————————
下面是创建图对象的代码。并在图中加入一些顶点和边,然后执行深度优先搜索。
Graph theGraph = new Graph();
theGraph.addVertex('A');
theGraph.addVertex('B');
theGraph.addVertex('C');
theGraph.addVertex('D');
theGraph.addVertex('E');
theGraph.addEdge(0,1);
theGraph.addEdge(1,2);
theGraph.addEdge(0,3);
theGraph.addEdge(3,4);
System.out.print("Visits:");
theGraph.dfs();
System.out.println();————————————————————————————————————
图的操作完整代码:
class StackX
{
private final int SIZE = 20;
private int[] st;
private int top;
//...........................
public StackX()
{
st = new int[SIZE];
top = -1;
}
//............................
public void push(int j)
{
st[++top] = j;
}
//.................
public int pop()
{
return st[top--];
}
//........................
public int peek()
{
return st[top];
}
//.......................
public boolean isEmpty()
{
return (top == -1);
}
}
//....................................
class Vertex
{
public char label ;
public boolean wasVisited ;
//..........................
public Vertex(char lab)
{
label = lab;
wasVisited = false;
}
}
//............................................
class Graph
{
private final int MAX_VERTS = 20;
private Vertex vertexList[] ;
private int adjMat[][];
private int nVerts;
private StackX theStack;
//.......................................
public Graph()
{
vertexList = new Vertex[MAX_VERTS];
adjMat = new int[MAX_VERTS][MAX_VERTS];
nVerts = 0;
for (int i = 0; i < MAX_VERTS; i++)
for (int j = 0; j < MAX_VERTS; j++)
adjMat[i][j] = 0;
theStack = new StackX();
}
//........................
public void addVertex(char lab)
{
vertexList[nVerts++] = new Vertex(lab);
}
//..............................
public void addEdge(int start,int end)
{
adjMat[start][end] = 1;
adjMat[end][start] = 1;
}
//.............................
public void displayVertex(int v)
{
System.out.print(vertexList[v].label);
}
//..............................
public void dfs()
{ //begin at vertex 0
vertexList[0].wasVisited = true; //mark it
displayVertex(0); //display it
theStack.push(0); // push it
while(!theStack.isEmpty()) //栈不为空时
{
int v = getAdjUnvisitedVertex(theStack.peek());
if(v == -1)
theStack.pop();
else
{
vertexList[v].wasVisited = true;
displayVertex(v);
theStack.push(v);
}
}
for (int i = 0; i < nVerts; i++)
vertexList[i].wasVisited = false;
}
//..........................
public int getAdjUnvisitedVertex(int v)
{
for (int i = 0; i < nVerts; i++)
if(adjMat[v][i] ==1 && vertexList[i].wasVisited == false)
return i;
return -1;
}
}
//////////////////////////////////////////////////////
class DFSApp
{
public static void main(String[] args)
{
Graph theGraph = new Graph();
theGraph.addVertex('A');
theGraph.addVertex('B');
theGraph.addVertex('C');
theGraph.addVertex('D');
theGraph.addVertex('E');
theGraph.addEdge(0,1);
theGraph.addEdge(1,2);
theGraph.addEdge(0,3);
theGraph.addEdge(3,4);
System.out.print("Visits:");
theGraph.dfs();
System.out.println();
}
}

相关文章推荐
- 【Python排序搜索基本算法】之深度优先搜索、广度优先搜索、拓扑排序、强联通&Kosaraju算法
- 图基本算法 图搜索基于邻接表的(广度优先、深度优先)
- 【Python排序搜索基本算法】之深度优先搜索、广度优先搜索、拓扑排序、强联通&Kosaraju算法
- 图的基本算法——广度优先搜索和深度优先搜索
- 算法——基本的图算法:广度优先搜索、深度优先搜索
- [算法] 基本图算法:深度优先搜索、广度优先搜索
- 树的存储结构和图的存储结构以及图的深度优先DFS搜索和BFS广度优先搜索
- 图的基本操作:图的创造(基于邻接矩阵)、深度搜索(DFS)、广度搜索(DFS)
- 二叉树基本操作的递归实现(二叉树建立,先序,中序,后序,深度的递归遍历。广度优先,高度优先的非递归遍历)
- 【图的实现】“广度优先搜索遍历”以及“深度优先搜索遍历”必会
- 输入一个1~9之间的数字 ,对 1到该数之间所有的数进行全排序(深度优先搜索的基本模型)
- 二叉树的基本操作精集(创建、遍历、求深度结点以及叶子结点个数)
- (算法入门)基本图论-深度优先搜索之JAVA实现
- 图基本算法 图搜索(广度优先、深度优先)
- 图的基本操作:图的创造(基于邻接表)、深度搜索(DFS)、广度搜索(DFS)
- 图邻接链表基本操作--广度优先、深度优先、拓扑排序
- 深度学习torch之三(神经网络的前向传播和反向传播以及损失函数的基本操作)
- 深度优先搜索遍历与广度优先搜索遍历
- 图深度优先搜索DFS
- Java中的移位操作以及基本数据类型转换成字节数组【收集】