方便又官方的字符串处理函数及内存函数的实现
2016-11-26 20:30
363 查看
一.介绍:
实现了字符串一些处理函数及内存函数,如strlen/strcpy/strcmp/strcat/memset/memcpy/memcmp/memmove主要借鉴了linux内核的实现方法,其中strlen函数给出了不定义第三方变量实现的方法,详细的代码在我的github里,供大家借鉴二.代码阐释
/*实现各字符串处理的函数
**2016-11-24
*/
#include<iostream>
#include<assert.h>
using namespace std;
size_t My_strlen1(const char *str);//求字符串长度
size_t My_strlen2(const char *str);
char *My_strcat(char *des, const char *src);//字符串的追加
char *My_strcpy(char *des, const char *src);//字符串拷贝
int My_strcmp(const char *str1, const char *str2);//字符串的比较
void *My_memset(void *s, int ch, size_t size);//将s指向的内存区域前n个字节以参数c传入,
//然后返回s的指针。用于将数组初始化较方便
//说明:参数c虽声明为int,但必须是unsigned char,所以范围在0到255之间
void *My_memcpy(void *dest, const void *src, size_t count);//拷贝src所指向的内存内容前n个字节到dest所指地址上。
//和strcpy不同的是,memcpy()会完整的复制n个字节,
//不会因为遇到字符串结束'\0'而结束
int My_memcmp(const void *s1, const void *s2, size_t n);//比较s1和s2前n个字符,返回差值
void *My_memmove( void *dest, const void *src, size_t count);
size_t My_strlen1(const char *str)
{
assert(str != NULL);
/*内核源码:
**sc先是指向源字符串首元素,随后sc++,知道遇到'\0',则指向了
**数组的末尾的'\0',则用此时的地址减去数组首元素的地址即是整个字符串的大小*/
const char *sc;
for(sc=str; *sc!=0; ++sc)//sc此时存储的地址和str一样,都指向str字符串
/*nothing to do*/;
return (sc-str);
}
size_t My_strlen2(const char *str)
{
/*采取递归的方式*/
assert(str != NULL);
if(*str == '\0')
return 0;
else{
return 1+My_strlen2(++str);//str++,先使用原字符,等于说将同一个地址压栈无限次,程序中断
}
}
char *My_strcat(char *des, const char *src)
{
assert((des != NULL) && (src != NULL));
char *tmp = des;
while(*tmp != '\0')
tmp++;
while(*src != '\0')
*tmp++ = *src++;
*tmp = '\0'; //字符串追加结束,给末尾加\0
return des;
}
char *My_strcpy(char *des, const char *src)
{
assert((des != NULL) && (src != NULL));
char *tmp = des;
while(*src != '\0')
*des++ = *src++;
*des = '\0';
return tmp;
}
int My_strcmp(const char *str1, const char *str2)
{
unsigned char c1,c2;
assert((str1 != NULL) && (str2 != NULL));
while(1)
{
c1 = *str1++;
c2 = *str2++;
if(c1 != c2)
return c1 > c2 ? 1 : -1;
if(c1 == '\0')
break;
}
return 0;
/*一个错误的展示,当str1长度和str2长度不一致时出错
while((*str1 != '\0') && (*str2 != '\0'))
{
if(*str1 > *str2)
return 1;
else if(*str1 == *str2)
{
str1++;
str2++;
}
else
return -1;
}
return 0;*/
}
void *My_memset(void *s, int ch, size_t size)
{
assert(((char *)s != NULL) && (size>=0));
char *tmp = (char *)s;
while(size--)
{
*tmp++ = ch;
}
//*tmp = '\0';
return s;
}
void *My_memcpy(void *dest, const void *src, size_t count)
{
assert(((char *)dest!=NULL) && ((char *)src!=NULL) && (count>=0));
char *tmp = (char *)dest;
const char *s = (const char *)src;
while(count--)
*tmp++ = *s++;
return dest;
}
int My_memcmp(const void *s1, const void *s2, size_t n)
{
char *str1 = (char *)s1;
char *str2 = (char *)s2;
assert((str1!=NULL) && (str2!=NULL) && (n >= 0));
while((*str1-*str2)==0)
{
str1++;
str2++;
}
return (*str1-*str2);
}
/*为验证memcpy和memmove的区别
**void *memmove( void *dest, const void *src, size_t count );
**当 src 和 dest 所指内存区有重叠时,memmove 相对 memcpy 能提供保证
**下面给出具体的例子证明
**当出现(1)(dest尾部和src头部重合)对应的情况时,就需要先从src的头部开始复制;
**也就是memmove源码中的if分支,这部分源码和memcpy的实现是一致的;
**当出现(2)(dest头部和src尾部重合)对应的情况时,就需要先从src的尾部开始复制,
**防止出现了覆盖现象。这就是memmove比memcpy多的一个考虑点,
**所以说,在实际使用时,使用memmove是比memcpy更安全的。
*/
void *My_memmove( void *dest, const void *src, size_t count)
{
assert((dest != NULL) && (src != NULL));
char *s1 = (char *)dest;
char *s2 = (char *)src;
if(s1 < s2)
{/*dest尾部和src头部重合时,就先从src的头部开始复制;*/
while(count--)
*s1++ = *s2++;
}
else if(s1 > s2)
{/*dest头部和src尾部重合时,就先从src的尾部开始复制*/
char *s3 = s1+count;
char *s4 = s2+count;
while(count--)
*s3-- = *s4--;
}
return dest;
}
int main(int argc, char const *argv)
{
int select = 0;
char s1[] = "liubaobao"; //数组,在栈区
char *s2 = "helloz!rereewewew!"; //字符串常量,在文字常量区
char *s6 = "helloz!";
char s3[] = "liubaobao";
char s4[] = "testtesttest";
char s5[] = "testtesttest";
char s9[] = "testtesttest";
char s7[20];
char s8[20];
int a[10] = {0};
while(1)
{
cout<<"*************************************"<<endl;
cout<<"* 1.strlen 2.strcat 3.strcpy *"<<endl;
cout<<"* 4.strcmp 5.memset 6.memcpy *"<<endl;
cout<<"* 7.memcmp 8.memmove 0.quit_os *"<<endl;
cout<<"*************************************"<<endl;
cout<<"+-----------------------------------+"<<endl;
cout<<"你的选择是:";
scanf("%d", &select);
switch(select)
{
case 1:
cout<<strlen(s1)<<endl;
cout<<"+-------+"<<endl;
cout<<My_strlen1(s1)<<endl;//内核的实现形式
cout<<My_strlen2(s1)<<endl;//不申请第三方变量的实现形式:递归
break;
case 2:
cout<<strcat(s1, s2)<<endl;
cout<<"+-------+"<<endl;
cout<<My_strcat(s3, s2)<<endl;
break;
case 3:
cout<<strcpy(s4, s2)<<endl;
cout<<"+-------+"<<endl;
cout<<My_strcpy(s5, s2)<<endl;
break;
case 4:
cout<<strcmp(s6, s2)<<endl;
cout<<"+-------+"<<endl;
cout<<My_strcmp(s6, s2)<<endl;
break;
case 5:
memset(a, 0, sizeof(int)*10);
for(int i=0; i<10;++i)
cout<<a[i]<<"\t";
cout<<"+-------+"<<endl;
My_memset(a, 0, sizeof(int)*10);
for(int j=0; j<10;++j)
cout<<a[j]<<"\t";
break;
case 6:
memcpy(s4, s3, strlen(s3));
cout<<s4<<endl;
cout<<"+-------+"<<endl;
My_memcpy(s5, s1, My_strlen1(s1));
cout<<s5<<endl;
break;
case 7:
cout<<memcmp(s2, s6, sizeof(s6))<<endl;
cout<<"+-------+"<<endl;
cout<<My_memcmp(s2, s6, sizeof(s6))<<endl;
break;
case 8:
memcpy(&s4[4], s4, sizeof(s4)/sizeof(char));
cout<<"memcpy的结果\t"<<s4<<endl;
memmove(&s5[4], s5, sizeof(s5)/sizeof(char));
cout<<"memmove的结果\t"<<s5<<endl;
cout<<"+-------+"<<endl;
My_memmove(&s9[4], s9, sizeof(s9)/sizeof(char));
cout<<s9<<endl;
break;
case 0:
return 0;
default:
cout<<"参数有误!"<<endl;
break;
}
}
return 0;
}/*str_fun.cpp*/三.后记:
一些实现过程中的分析:1.用递归的方式实现strlen代码那么整洁,为什么内核不这样实现?
原因有两点:
(1)递归的效率低下,参见“递归为什么那么慢?递归的改进算法”。函数的调用要消耗资源,函数调用的时候,每次调用时要做地址保存,参数传递等,这是通过一个递归工作栈实现的。具体是每次调用函数本身要保存的内容包括:局部变量、形参、调用函数地址、返回值。那么,如果递归调用N次,就要分配N*局部变量、N*形参、N*调用函数地址、N*返回值。这势必是影响效率的。
(2)递归稍有不慎,会造成栈溢出,笔者在编写代码的时候遇到了这样的问题,本代码的第42行,读者有兴趣可以讲++str换成str++,程序运行起来会发现崩溃掉了,在某些编译器里会报”overflow”的错误,这就是栈溢出。具体分析此问题:
假设读者已经掌握了前置++和后置++的区别。此代码第42行,如果改成str++,程序是这样运行的:
程序先使用str这个地址所指向的字符,本程序也就是字符串”liubaobao”的第一个字符’l’,然后还没等到给str+1,就又调用了My_strlen函数,如此循环,str一直指向’l’,无法终止,程序陷入了死循环中,栈被冲破,也就是栈溢出了。
2.strcmp函数实现时应该注意的?
int My_strcmp(const char *str1, const char *str2)
{ /*一个错误的展示,当str1长度和str2长度不一致时出错
while((*str1 != '\0') && (*str2 != '\0'))
{
if(*str1 > *str2)
return 1;
else if(*str1 == *str2)
{
str1++;
str2++;
}
else
return -1;
}
return 0;
}比如str1为”hello”,str2位“helloz”,上述实现,当任何一个字符串比较到’\0’,函数运行结束,就造成了两字符串最终比较的结果为相等,显而易见这是错的。我们要做的就是让一个字符串到达’\0’时还未分辨出谁大谁小时,还能往下比较。那么应该这样实现:
int My_strcmp(const char *str1, const char *str2)
{
unsigned char c1,c2;
assert((str1 != NULL) && (str2 != NULL));
while(1)
{
c1 = *str1++;
c2 = *str2++;
if(c1 != c2)
return c1 > c2 ? 1 : -1;
if(c1 == '\0')
break;
}
return 0;
}3.memcpy和memmove有什么区别?
MSDN里有这么一段耐人寻味的话:The memcpy function copies count bytes of src to dest. If the source and destination overlap, this function does not ensure that the original source bytes in the overlapping region are copied before being overwritten. Use memmove to handle overlapping regions.
在高级的编译器(比如说笔者所用的VS2012),memcpy和memmove函数实现的结果是一样的,两者的代码实现甚至是类似的。这是一个历史遗留问题。
(1)在linux内核的3.5以前版本中(笔者查阅了linux-2.6.28和linux-3.5的内核版本),保留了memcpy和memmove的不一致性
/*memcpy*/
void *memcpy(void *dest, const void *src, size_t count)
{
char *tmp = dest;
const char *s = src;
while (count--)
*tmp++ = *s++;
return dest;
}
/*memmove*/
void *memmove(void *dest, const void *src, size_t size)
{
uint8_t *d = dest;
const uint8_t *s = src;
size_t i;
if (d < s) {
for (i = 0; i < size; ++i)
d[i] = s[i];
} else if (d > s) {
i = size;
while (i-- > 0)
d[i] = s[i];
}
return dest;
}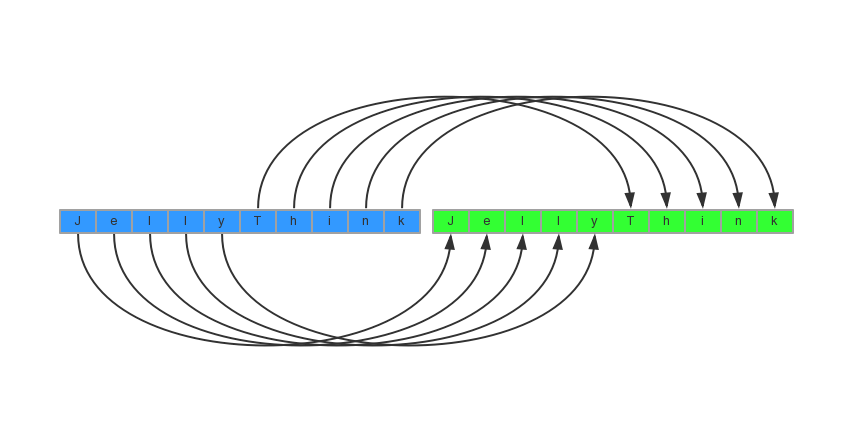
如上图,这样调用memcpy不会存在问题
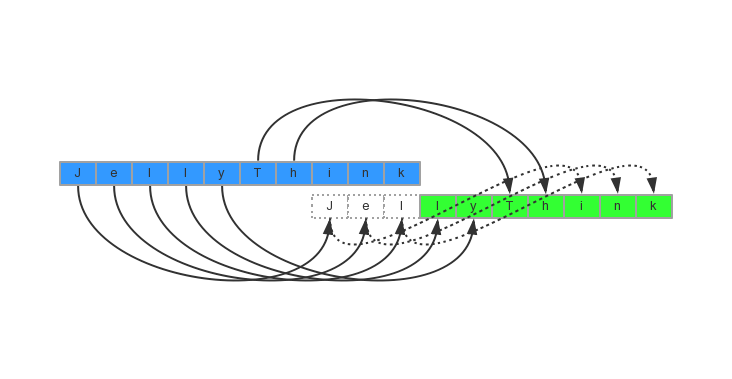
又如上图,当两个字符串的内存块存在重叠怎么办呢?这时调用memcpy函数并不能得到我们所要的结果。为了使拷贝更加精准,手册推荐我们使用memmove函数。
下图给出了我们应该考虑的情况:
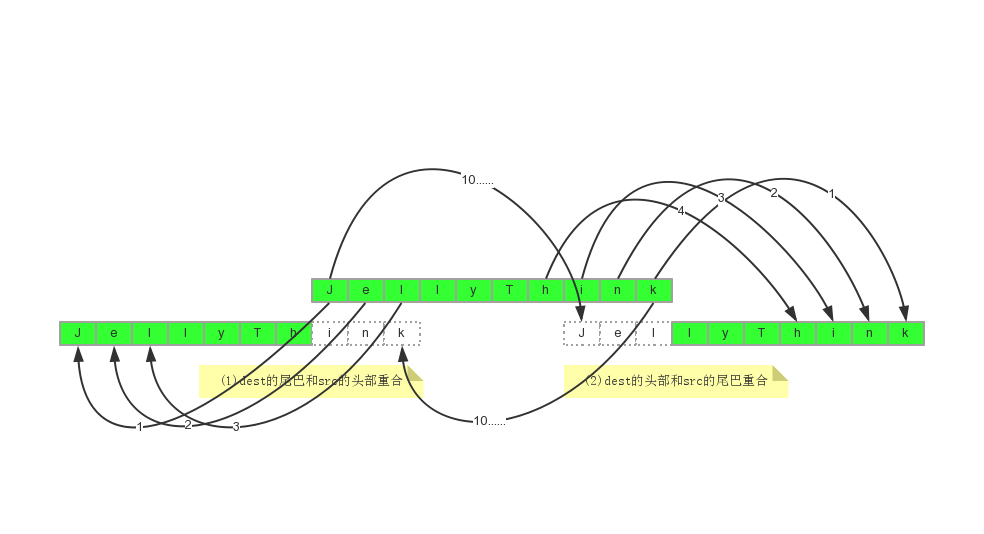
**当出现(1)(dest尾部和src头部重合)对应的情况时,就需要先从src的头部开始复制;
**也就是memmove源码中的if分支,这部分源码和memcpy的实现是一致的;
**当出现(2)(dest头部和src尾部重合)对应的情况时,就需要先从src的尾部开始复制,
**防止出现了覆盖现象。这就是memmove比memcpy多的一个考虑点。
详细的介绍读者可以品味C++中”memcpy和memmove的区别总结”
(2)真实的memmove?
为了使得memcpy和memmove能够区分开来,笔者认为真实与memmove这个名字相符合的函数,不仅仅应当实现了字符串的拷贝,还应将被拷贝的原来的的字符串删除,笔者认为可以将其赋值为’\0’。
四.总结:
字符串处理函数针对的是字符串,而内存函数是从内存的角度出发的,这就导致,内存函数在处理的时候效率比字符串处理函数的效率高,而且可以对任意类型进行操作,,,但同时也要考虑到内存重叠的情况!

相关文章推荐
- C库函数字符串处理函数的C实现(常见)
- 巧用boost库实现字符串映射消息处理函数
- 自己实现基本的C标准库字符串处理函数——基本问题(转载)
- C 某些库函数中字符串处理函数的具体实现
- linux 下面字符串处理函数实现 抄来看一下 抄自[http://blog.csdn.net/BeWithLei/article/details/1719242]
- C字符串处理函数的实现(Linux)
- C字符串处理函数的实现(Linux)
- 字符串处理函数strlen、strcpy、strcat、strcmp和convert的C语言实现
- 自定义实现字符串处理函数 strlen strcmp strcpy strncpy strcat strncat strchr strstr
- 自定义函数实现字符串处理函数strcat、 strcpy、strcmp、strlen和strlwr
- 常见字符串处理函数的C实现
- 自己实现的一些字符串处理的函数
- C字符串处理函数的实现
- 字符串处理函数的实现
- 一些字符串及内存操作的函数的实现
- 巧用boost库实现字符串映射消息处理函数
- C字符串处理函数汇总实现(面试大多会用到)
- 巧用boost库实现字符串映射消息处理函数
- C字符串处理函数的实现
- 自定义实现字符串处理函数 strlen strcmp strcpy strncpy strcat strncat strchr strstr