Python实现抓取网页信息(一)
2016-11-26 17:13
411 查看
写在开头:初次接触Python,翻一翻网上的python文章,都说无论新手和老手都在用python网页爬虫。正好最近网课考试,这种有题库的网课,爬一下题库就在所难免,于是就用了python试一下,于是就准备写这个python网页爬虫初体验
概述
cookie基本知识
什么是cookie
cookie的工作过程
实现模拟登陆
构造头部信息
构造账户信息
登录取得cookie
网内畅游
beautifulsoup
初始化
解析
结语
简而言之cookie就是网络上身份认证的一种手段,对于网络上需要登录才能提供的服务,比如博客的个人栏目,都需要使用cookie去维护用户的的登录信息(当然现在用session的也比较多)。
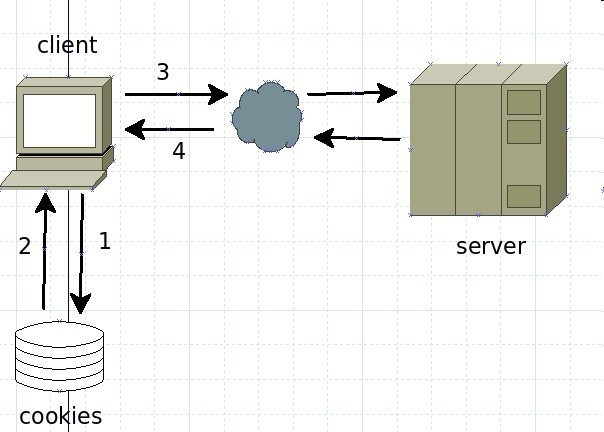
1.如果客户端根据网址查找客户端的历史文件,如果有历史的cookies,客户端会取出这个cookie发给服务器进行身份验证。
2.如果没有该cookie,服务器端将会要求客户端登录,在登录成功后在返回的包的头部字段会有set-cookie字段,client取得该cookie之后每次请求网页的时候都会携带这个cookie用于身份验证。
关于cookie字段的详细内容,在实现模拟登陆的过程中没有必要了解。
上面这个头部是我从网页上利用F12键调试工具复制下来的
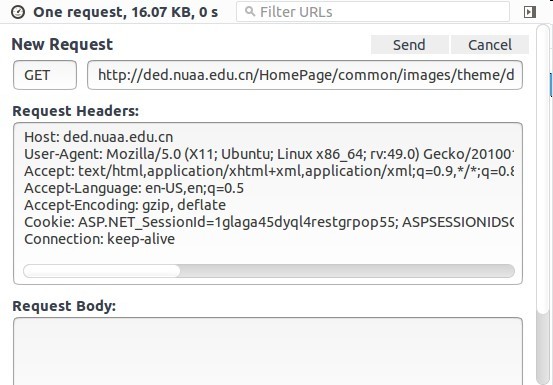
cookie那一栏就是之前登录过然后就会直接放在头部上发过去。(有的时候需要重新登录是因为cookie有失效时间)
头部信息字段的含义,如果感兴趣,读者可以自行百度,这边不做讲解。
字段的信息你可以在网页中尝试登陆过程,然后打开F12,在NetWork栏目下面查看整个登录的流程,比如
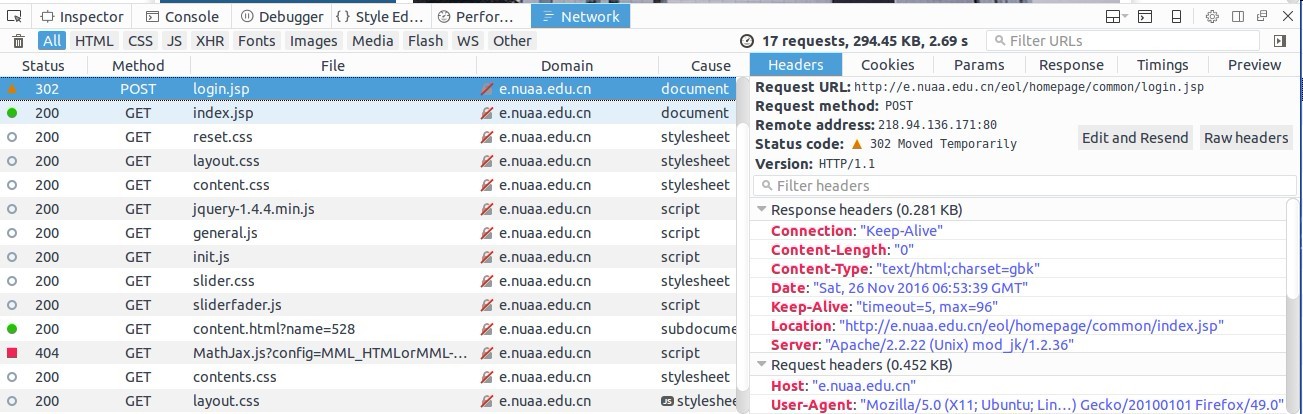
从登录的信息中可以看到实际的表单提交的网址,以及Request提交的表单的详细信息,我们需要做的就是构造出这个表单,然后post到这个登录的网址
python强大之处就是不需要我们手动管理cookie
使用python urllib2提供的cookie管理工具。
之后usrlib2这个包就会自动帮我们管理cookie信息
首先构建request信息其中postUrl是登录网址,urllib.urlencode是将数据转化成网络格式。
然后将请求发送出去,获得返回的response
返回的response是一个页面,该页面就是你浏览器登陆之后,自动跳出的页面。
直接调用下面这个函数就可以了。
然后就可以用read或者head函数去测试网页信息了。read返回的是html文件,而head是头部信息。
1.我在实际使用这个的时候,他的文档自动补齐的功能,把我的html补的不对,两个并列的input补成了父子标签,很蛋疼
2.网上说官方文档很全,对于一个新手来说。那种没有逻辑的广发文档就是灾难,例如,对于他的bs4.element.ResultSet这个类,到现在为止我都不清楚他到低有那些方法,我也不清楚他的包里面到地有哪些类,以及一些主要函数他的返回类型是啥,实际在用的过程中,我需要的不断的用type函数
3.我之前用过jsoup爬网页,所以比较喜欢用css选择器,对比了buautifulsoup的find和select函数,觉得还是select函数比较好用,select函数就是用的css选择器
4.下面只是粗略讲一讲,详细中文版教程
1.字符分为字节码(str)和字符码(unicode),
2.从字节码到字符码叫做解码(decode),从字符码到字节码叫做编码(encode)
3.字符码的作用是显示,字节码的作用是储存
4.字符码表示的是一个一个字符,其中编码方式有很多比如utf8,utf16,gbk,ascii等
5.字节码表示的是一个个字节,其本身并不是一定就能表示一个一个的字符,可能需要两个字节,四个字节,这就需要通过不同的编码格式去确定
6.从文本读入的默认是str,print函数会自动将字节码转化为字符码显示,解码格式就是使用python文件中规定的#coding utf8指示的。
在实际的网页分析中,网页的编码格式可能是gb2312,所以如果使用默认的utf8就会出错
注意点:1.对于从文本中读入的字节码,如果要转化为字符码,必须显示调用unicode(‘str’,’编码方式’)进行解码成unicode
2.在将字节码写入到文件中的时候,必须显示的调用unicode.encode(‘编码方式’)进行编码
3.Beautifulsoup网页分析中大部分函数的返回值都是unicode字符码(这一条不太敢确定,我猜开发这个包的人都没有注意这个问题),所以在写入结果到文件的时候,需要使用encode进行编码,默认是使用ascii编码!!
4.建议所有的编码都使用utf-8
在定义一个字符串的时候,最好使用u’str’,会使用页面编码方式,讲你的字符定义成unicode,因为在实际的字符串比较的过程中,肯定是字符进行比较,你肯定不希望字节之间比较吧。
整个项目已上传到coding,示例的网页是南航网络课程。
概述
cookie基本知识
什么是cookie
cookie的工作过程
实现模拟登陆
构造头部信息
构造账户信息
登录取得cookie
网内畅游
beautifulsoup
初始化
解析
结语
概述
某航教务网络课程,首页需要登录,使用的cookie验证。使用的beautifulsoup4分析数据的包,正则以及网络包默认就有,所以应该要自己安装的就是beautifulsoup4包cookie基本知识
1.什么是cookie
Cookie 是在 HTTP 协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie 是由 Web 服务器保存在用户浏览器(客户端)上的小文本文件,它可以包含有关用户的信息。无论何时用户链接到服务器,Web 站点都可以访问 Cookie 信息——百度文库简而言之cookie就是网络上身份认证的一种手段,对于网络上需要登录才能提供的服务,比如博客的个人栏目,都需要使用cookie去维护用户的的登录信息(当然现在用session的也比较多)。
2.cookie的工作过程
1.如果客户端根据网址查找客户端的历史文件,如果有历史的cookies,客户端会取出这个cookie发给服务器进行身份验证。
2.如果没有该cookie,服务器端将会要求客户端登录,在登录成功后在返回的包的头部字段会有set-cookie字段,client取得该cookie之后每次请求网页的时候都会携带这个cookie用于身份验证。
关于cookie字段的详细内容,在实现模拟登陆的过程中没有必要了解。
3.实现模拟登陆
注意模拟登录的网址不是你看到的网址,而是登录表单实际提交的地址,直接网页网页源码,这个很好找的1.构造头部信息
headers = { 'Host':'hostname',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:49.0) Gecko/20100101 Firefox/49.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate',
'Referer': 'website',
'Connection': 'keep-alive'
}上面这个头部是我从网页上利用F12键调试工具复制下来的
cookie那一栏就是之前登录过然后就会直接放在头部上发过去。(有的时候需要重新登录是因为cookie有失效时间)
头部信息字段的含义,如果感兴趣,读者可以自行百度,这边不做讲解。
2.构造账户信息
登录的过程的就是模拟表单提交到服务器,表单提交的内容需要根据你实际的网址规定的字段字段的信息你可以在网页中尝试登陆过程,然后打开F12,在NetWork栏目下面查看整个登录的流程,比如
从登录的信息中可以看到实际的表单提交的网址,以及Request提交的表单的详细信息,我们需要做的就是构造出这个表单,然后post到这个登录的网址
postData = {
'IPT_LOGINUSERNAME':'×××',
'IPT_LOGINPASSWORD':'×××'
}3.登录取得cookie
登陆成功后,服务器会返回一个cookie信息,我们就会利用这传回的cookie信息进行网络访问python强大之处就是不需要我们手动管理cookie
使用python urllib2提供的cookie管理工具。
cj = cookielib.LWPCookieJar() cookie_support = urllib2.HTTPCookieProcessor(cj) opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler) urllib2.install_opener(opener)
之后usrlib2这个包就会自动帮我们管理cookie信息
首先构建request信息其中postUrl是登录网址,urllib.urlencode是将数据转化成网络格式。
然后将请求发送出去,获得返回的response
request = urllib2.Request(postUrl, urllib.urlencode(postData) , headers) response = urllib2.urlopen(request)
返回的response是一个页面,该页面就是你浏览器登陆之后,自动跳出的页面。
4.网内畅游
可能reponse并不是我们实际需要网址,但是我们的cookie以及自动记录了,之后的每一次访问都会自动带上cookie信息直接调用下面这个函数就可以了。
response2 = urllib2.urlopen('url')
print reponse2.head()
print reponse2.read()然后就可以用read或者head函数去测试网页信息了。read返回的是html文件,而head是头部信息。
beautifulsoup
首先吐槽一下这个beautifulsoup,1.我在实际使用这个的时候,他的文档自动补齐的功能,把我的html补的不对,两个并列的input补成了父子标签,很蛋疼
2.网上说官方文档很全,对于一个新手来说。那种没有逻辑的广发文档就是灾难,例如,对于他的bs4.element.ResultSet这个类,到现在为止我都不清楚他到低有那些方法,我也不清楚他的包里面到地有哪些类,以及一些主要函数他的返回类型是啥,实际在用的过程中,我需要的不断的用type函数
3.我之前用过jsoup爬网页,所以比较喜欢用css选择器,对比了buautifulsoup的find和select函数,觉得还是select函数比较好用,select函数就是用的css选择器
4.下面只是粗略讲一讲,详细中文版教程
1.初始化
#先将网页编码改为utf-8
html=unicode(response.read(), "gb2312").encode("utf8")
#初始化BeautifulSoup对象,其中html.parse是解析器,还有那个lxml解析器,网上说很好用,但是我的这个不能用,也没有较真的去找原因
soup = BeautifulSoup(html,'html.parser')2.解析
下面的解析也就是配合soup所提供的函数,加上正则表达式处理字符串的一些简单方法,进行了解析,提取需要的信息即可。结语
python解析数据,永远逃不过的内容就是有关于字符编码的问题。搜一搜,网上说的是五花八门,下面简单的说一下自己的理解。来源于JOIN_ABC的博客1.字符分为字节码(str)和字符码(unicode),
2.从字节码到字符码叫做解码(decode),从字符码到字节码叫做编码(encode)
3.字符码的作用是显示,字节码的作用是储存
4.字符码表示的是一个一个字符,其中编码方式有很多比如utf8,utf16,gbk,ascii等
5.字节码表示的是一个个字节,其本身并不是一定就能表示一个一个的字符,可能需要两个字节,四个字节,这就需要通过不同的编码格式去确定
6.从文本读入的默认是str,print函数会自动将字节码转化为字符码显示,解码格式就是使用python文件中规定的#coding utf8指示的。
在实际的网页分析中,网页的编码格式可能是gb2312,所以如果使用默认的utf8就会出错
注意点:1.对于从文本中读入的字节码,如果要转化为字符码,必须显示调用unicode(‘str’,’编码方式’)进行解码成unicode
2.在将字节码写入到文件中的时候,必须显示的调用unicode.encode(‘编码方式’)进行编码
3.Beautifulsoup网页分析中大部分函数的返回值都是unicode字符码(这一条不太敢确定,我猜开发这个包的人都没有注意这个问题),所以在写入结果到文件的时候,需要使用encode进行编码,默认是使用ascii编码!!
4.建议所有的编码都使用utf-8
在定义一个字符串的时候,最好使用u’str’,会使用页面编码方式,讲你的字符定义成unicode,因为在实际的字符串比较的过程中,肯定是字符进行比较,你肯定不希望字节之间比较吧。
整个项目已上传到coding,示例的网页是南航网络课程。

相关文章推荐
- python——爬虫实现网页信息抓取
- Python爬虫实现网页信息抓取功能示例【URL与正则模块】
- [转载] C#实现通过程序自动抓取远程Web网页信息
- 使用Python抓取网页信息
- python多线程抓取网页信息
- C#实现通过程序自动抓取远程Web网页信息
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
- 网页信息抓取实现
- 使用python抓取有道词典的网页并返回结果信息
- 如何用Python,C#等语言去实现抓取静态网页+抓取动态网页+模拟登陆网站
- python多线程抓取网页信息
- python 抓取网页网址信息
- C#实现通过程序自动抓取远程Web网页信息
- [Python]网页信息抓取
- python实现抓取网页上的内容并发送到邮箱
- 使用python抓取网页(以人人网新鲜事和团购网信息为例)
- C#实现通过程序自动抓取远程Web网页信息
- 通过HtmlAgilityPack实现网页信息抓取
- Python 利用urllib2 lxml 抓取网页信息
- (转)用python实现抓取网页、模拟登陆