SparkStream:5)Spark streaming+kafka整合实战
2016-11-22 20:35
316 查看
Spark streaming+kafka整合实战
kafka的部署请参考:http://blog.csdn.net/jiangpeng59/article/details/53241693
本文主要是参加Spark提供的官网文档进行实际操作,文档地址:http://spark.apache.org/docs/1.6.0/streaming-kafka-integration.html
测试环境:Spark1.6.0 + Kafka0.9.0 + zookeeper3.4.3
1.使用maven添加spark-streaming-kafka_2.10的jar包依赖
2.使用一个测试程序往kafka的服务器输送数据
3.开启kafka接受信息进程
在执行上面的代码之前,先开启一个kafka进程来接受从Produce(上面的代码)传递来的信息
4.SparkStream消费端
在官方整合文档中,也介绍目前StreamSpark从Kafka拉取数据的方式有两种,一种是基于Receiver的,一种是直接访问不依赖于Receiver的createDirectStream。官方介绍了第二种方法的几个优势,而且Spark2.0是默认使用第二种方法的。
上面的代码,对从kafka中传递过来的word(数字)进行了简单的单词统计
把上面的文件在IDEA中打包,把spark-streaming-kafka_2.10的相关jar包整合到项目输出的jar包中,虽然文件大了些,但是省了不少麻烦
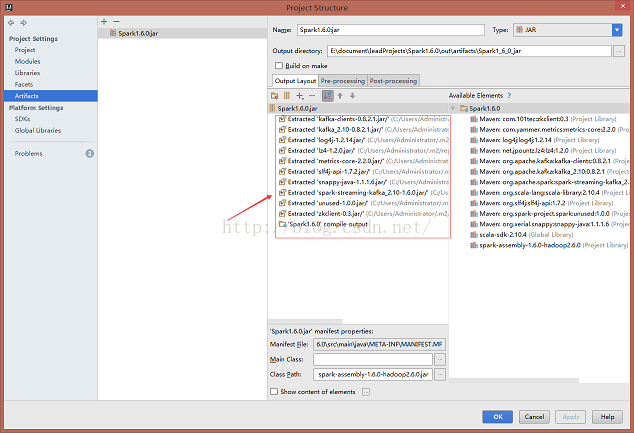
在Spark集群中提交这个jar包(先运行2、3步骤)
kafka的部署请参考:http://blog.csdn.net/jiangpeng59/article/details/53241693
本文主要是参加Spark提供的官网文档进行实际操作,文档地址:http://spark.apache.org/docs/1.6.0/streaming-kafka-integration.html
测试环境:Spark1.6.0 + Kafka0.9.0 + zookeeper3.4.3
1.使用maven添加spark-streaming-kafka_2.10的jar包依赖
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.6.0</version> </dependency> </dependencies>
2.使用一个测试程序往kafka的服务器输送数据
import java.util
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
object KafkaWordCountProducer {
def main(args: Array[String]) {
val topic = "test"
val brokers = "slave01:9092,slave02:9092,slave03:9092"
val messagesPerSec=1 //每秒发送几条信息
val wordsPerMessage =4 //一条信息包括多少个单词
// Zookeeper connection properties
val props = new util.HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
// Send some messages
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
.mkString(" ")
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
println(message)
}
Thread.sleep(1000)
}
}
}简单解释下上面的代码,每秒发生1条信息到Kafka的服务器端,其消息的内容格式如下ProducerRecord(topic=test, partition=null, key=null, value=4 6 1 1 ProducerRecord(topic=test, partition=null, key=null, value=7 1 5 0value字段就是我们所需要的东东
3.开启kafka接受信息进程
在执行上面的代码之前,先开启一个kafka进程来接受从Produce(上面的代码)传递来的信息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning执行后,其会一直监听这个是否有数据发送到名为test的topic下,有消息则会接受,并保存打印出来
[root@slave02 kafka_2.10-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning 8 5 6 0 5 4 0 8 9 0 9 0 5 1 7 0 7 4 4 3 2 7 6 8
4.SparkStream消费端
在官方整合文档中,也介绍目前StreamSpark从Kafka拉取数据的方式有两种,一种是基于Receiver的,一种是直接访问不依赖于Receiver的createDirectStream。官方介绍了第二种方法的几个优势,而且Spark2.0是默认使用第二种方法的。
import kafka.serializer.StringDecoder
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.SparkConf
/**
* Consumes messages from one or more topics in Kafka and does wordcount.
* Usage: DirectKafkaWordCount <brokers> <topics>
* <brokers> is a list of one or more Kafka brokers
* <topics> is a list of one or more kafka topics to consume from
*
* Example:
* $ bin/run-example streaming.DirectKafkaWordCount broker1-host:port,broker2-host:port \
* topic1,topic2
*/
object DirectKafkaWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println(s"""
|Usage: DirectKafkaWordCount <brokers> <topics>
| <brokers> is a list of one or more Kafka brokers
| <topics> is a list of one or more kafka topics to consume from
|
""".stripMargin)
System.exit(1)
}
val Array(brokers, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
// Get the lines, split them into words, count the words and print
val lines = messages.map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}上面的代码,对从kafka中传递过来的word(数字)进行了简单的单词统计
把上面的文件在IDEA中打包,把spark-streaming-kafka_2.10的相关jar包整合到项目输出的jar包中,虽然文件大了些,但是省了不少麻烦
在Spark集群中提交这个jar包(先运行2、3步骤)
spark-submit --master=spark://master:7077 \ --class DirectKafkaWordCount \ ./Spark1.6.0.jar \ slave01:9092,slave02:9092,slave03:9092 test可以看到如下结果
16/11/22 18:46:56 INFO scheduler.DAGScheduler: Job 301 finished: print at DirectKafkaWordCount.scala:65, took 0.015078 s ------------------------------------------- Time: 1479811616000 ms ------------------------------------------- (8,1) (9,1) (3,1) (1,1)

相关文章推荐
- Spark Streaming整合kafka实战(一)
- spark streaming 实现kafka的createDirectStream方式!!不坑
- Spark-Streaming与Kafka整合
- Kafka+Spark Streaming+Redis实时计算整合实践
- 基于Java+SparkStreaming整合kafka编程
- Spark Streaming + Kafka整合指南
- Kafka+Spark Streaming+Redis实时计算整合实践
- 【转】Spark Streaming和Kafka整合开发指南
- Kafka+Spark Streaming+Redis实时计算整合实践
- 第90讲,Spark streaming基于kafka 以Receiver方式获取数据 原理和案例实战
- 整合Kafka到Spark Streaming——代码示例和挑战
- sparkstreaming整合kafka参数设置,message偏移量写入mysql
- spark streaming 实现kafka的createDirectStream方式!!不坑
- Kafka+Spark Streaming+Redis实时计算整合实践
- Kafka+Spark Streaming+Redis实时计算整合实践
- 整合Kafka到Spark Streaming——代码示例和挑战
- spark streaming 实现kafka的createDirectStream方式!!不坑
- SparkStreaming整合kafka编程
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark streaming+kafka实战教程