简单的Python抓取招聘网站信息(1)
2016-11-15 19:23
501 查看
作为一名大四狗刚刚经历完找工作的浪潮,发现每天需要去各类招聘网站进行看招聘信息非常麻烦,想到用Python爬虫抓取招聘网站的招聘信息。同届的同学大多找完了工作,文章就给将来需要的同学看吧~因为不着急,这个系列更新比较慢,大约1个月更新一次。
进入正题,常用的几个招聘网站有应届生、智联招聘、前程无忧等,后两个网站需要登录,因此将在后续博客中说到,本文的目标是抓取应届生网站上首页的某地区的招聘公司及详细信息的链接地址,保存为txt文件。效果如下:

1.首先导入需要的库,这里用到Python的requests和beautifulsoup两个库。写爬虫文件常用的库还有urllib。
import requests
from bs4 import BeautifulSoup
import os
2.对目标网页进行抓取和解析。
加入浏览器的header信息是为了假装是浏览器在访问网页,关于浏览器的头部信息如何查看,请自行搜索~
使用requests.get()就可以将目标网页抓取下来
最后一行为将网页用lxml进行解析。当然也可以使用其他解析器进行解析,不过推荐使用lxml
此时如果输入print(soup),则会打印出该网页的源代码。
3.然后进行网页的分析。我们的目标是要抓取网页上的招聘公司信息以及详细信息的链接。这里,我们还要抓取第一条招聘信息的发布时间作为存储时的文件名。
我们进入应届生重庆地区招聘网页点击打开链接,按下ctrl+shift+c,调出调试模式

点击第一条招聘信息,右侧代码区变蓝
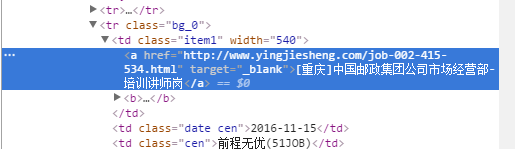
依次点击接下来几条信息,观察右侧代码区

可以发现,招聘公司和岗位的信息都在<td class="item1"><a>xxxx</a></td>中。而详细信息的链接在<a>标签中的href属性中。另外的,发布时间位于<td class = "date cen">xxxx</td>中。这样,我们将所需要的所有信息的位置定位下来。
4.下面进行目标信息的提取。
我们使用beautifulsoup库的方法进行信息的提取。先上代码吧
先说find_all方法,find_all(name,class_='string')表示找到所有名为name的,class为string的tag,其返回值为一个列表。如在news = soup.find_all()下面加上print(news),则会输出如下结果:
find方法与find_all方法类似,不过find直接返回搜索的结果,而非列表。
因我们观察到招聘企业与岗位的信息在<a></a>中,因此对news进行遍历,每个new中只含有一个a标签。使用find('a').text得到标签中的文本。
而最末行link['href']表示提取href属性的值,即标签中的超链接。
我们使用print(title)和print(link)看看打印结果:

信息和链接都已经成功提取到了。
5.信息保存
接下来的事情就非常简单了,我们只需要将信息写入本地磁盘即可。
首先创建文件夹
然后将信息写入txt文件中,此段代码写在上上段代码的for下面
大功告成~
可以看出,本文中抓取的信息都很简单粗暴,也未对信息进行筛选等,在下来几章中,将会有对指定日期的招聘信息抓取、招聘详细
8c2a
信息的抓取的内容~
进入正题,常用的几个招聘网站有应届生、智联招聘、前程无忧等,后两个网站需要登录,因此将在后续博客中说到,本文的目标是抓取应届生网站上首页的某地区的招聘公司及详细信息的链接地址,保存为txt文件。效果如下:
1.首先导入需要的库,这里用到Python的requests和beautifulsoup两个库。写爬虫文件常用的库还有urllib。
import requests
from bs4 import BeautifulSoup
import os
2.对目标网页进行抓取和解析。
加入浏览器的header信息是为了假装是浏览器在访问网页,关于浏览器的头部信息如何查看,请自行搜索~
使用requests.get()就可以将目标网页抓取下来
最后一行为将网页用lxml进行解析。当然也可以使用其他解析器进行解析,不过推荐使用lxml
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.87 Safari/537.36'}
url = 'http://www.yingjiesheng.com/chongqingjob/'
content = requests.get(url, headers=headers)
content.encoding = 'gbk'
soup = BeautifulSoup(content.text,"lxml")此时如果输入print(soup),则会打印出该网页的源代码。
3.然后进行网页的分析。我们的目标是要抓取网页上的招聘公司信息以及详细信息的链接。这里,我们还要抓取第一条招聘信息的发布时间作为存储时的文件名。
我们进入应届生重庆地区招聘网页点击打开链接,按下ctrl+shift+c,调出调试模式
点击第一条招聘信息,右侧代码区变蓝
依次点击接下来几条信息,观察右侧代码区
可以发现,招聘公司和岗位的信息都在<td class="item1"><a>xxxx</a></td>中。而详细信息的链接在<a>标签中的href属性中。另外的,发布时间位于<td class = "date cen">xxxx</td>中。这样,我们将所需要的所有信息的位置定位下来。
4.下面进行目标信息的提取。
我们使用beautifulsoup库的方法进行信息的提取。先上代码吧
date = soup.find('td', class_='date cen')
date = date.text
news = soup.find_all('td',class_='item1')
for new in news:
title = new.find('a').text
link = new.find('a')
link = link['href']先说find_all方法,find_all(name,class_='string')表示找到所有名为name的,class为string的tag,其返回值为一个列表。如在news = soup.find_all()下面加上print(news),则会输出如下结果:
[<td class="item1" width="540"><a href="http://www.yingjiesheng.com/job-002-415-534.html" target="_blank">[重庆]中国邮政集团公司市场经营部-培训讲师岗</a> <b>(<a href="/zhuanye/jiaoyuxue/" target="_blank" title="教育学类">教育</a> <a href="/zhuanye/gongshangguanli/" target="_blank" title="工商管理类(市场,营销,财务,会计,审计,人力资源,物业管理">工商</a> <a href="/zhuanye/jinrong/" target="_blank" title="金融学类(金融,投资,保险等)">金融</a> )</b> </td>, <td class="item1" width="540"><a href="http://www.yingjiesheng.com/job-002-415-929.html" target="_blank">[重庆]中国邮政集团公司运营管理部-档案与影像管理岗</a> <b>(<a href="/zhuanye/dangan/" target="_blank" title="图书档案学类">图档</a> <a href="/zhuanye/jinrong/" target="_blank" title="金融学类(金融,投资,保险等)">金融</a> )</b> </td>, <td class="item1" width="540"><a href="http://www.yingjiesheng.com/job-002-416-157.html" target="_blank">[重庆]重庆邮电大学移通学院2017校园招聘</a> <b>(<a href="/zhuanye/dianzixinx/" target="_blank" title="电子信息类(通信,微电子,光电等)">电子</a> <a href="/zhuanye/gongshangguanli/" target="_blank" title="工商管理类(市场,营销,财务,会计,审计,人力资源,物业管理">工商</a> <a href="/zhuanye/xinlixue/" target="_blank" title="心理学类">心理</a> <a href="/zhuanye/tongji/" target="_blank" title="统计学类">统计</a> <a href="/zhuanye/dizhi/" target="_blank" title="地质类">地质</a> <a href="/zhuanye/dizhi/" target="_blank" title="地质学类">地质</a> <a href="/zhuanye/tianwen/" target="_blank" title="天文学类">天文</a> <a href="/zhuanye/chinese/" target="_blank" title="中国语言文学类(汉语言等)">汉语</a> <a href="/zhuanye/zhiwu/" target="_blank" title="植物生产类(农学,园艺,植物保护等)">植</a> <a href="/zhuanye/waiguoyuyan/" target="_blank" title="外国语言文学类(英语,俄语,德语,日语,法语等)">外语</a> <a href="/zhuanye/jisuanji/" target="_blank" title="计算机类(软件,网络,信息安全等)">计算机</a> <a href="/zhuanye/zhexue/" target="_blank" title="哲学">哲</a> <a href="/zhuanye/zidonghua/" target="_blank" title="自动化类">自动</a> <a href="/zhuanye/xijuyingshi/" target="_blank" title="戏剧与影视学类">影视</a> <a href="/zhuanye/sheji/" target="_blank" title="设计学类">设计</a> <a href="/zhuanye/Marxism/" target="_blank" title="马克思主义理论类(思想政治等)">马列</a> <a href="/zhuanye/jiaoyuxue/" target="_blank" title="教育学类">教育</a> <a href="/zhuanye/zhengzhixue/" target="_blank" title="政治学">政</a> <a href="/zhuanye/lishixue/" target="_blank" title="历史学(历史,考古,博物馆)">历史</a> )</b> </td>, <td class="item1" width="540"><a href="http://www.yingjiesheng.com/job-002-416-285.html" target="_blank">[东莞|重庆]北京师范大学东莞石竹附属学校2017招聘</a> <b></b>]
find方法与find_all方法类似,不过find直接返回搜索的结果,而非列表。
因我们观察到招聘企业与岗位的信息在<a></a>中,因此对news进行遍历,每个new中只含有一个a标签。使用find('a').text得到标签中的文本。
而最末行link['href']表示提取href属性的值,即标签中的超链接。
我们使用print(title)和print(link)看看打印结果:
信息和链接都已经成功提取到了。
5.信息保存
接下来的事情就非常简单了,我们只需要将信息写入本地磁盘即可。
首先创建文件夹
path = os.getcwd() new_path = os.path.join(path,'招聘信息') if not os.path.isdir(new_path): os.mkdir(new_path)
然后将信息写入txt文件中,此段代码写在上上段代码的for下面
with open('招聘信息' + '/' + date + '招聘信息.txt','a',encoding='utf-8') as f:
f.write(title)
f.write('\n')
f.write(' 链接为: ')
f.write(link)
f.write('\n')
f.write('\n')
f.write('----------------------------------------------')
f.write('\n')大功告成~
可以看出,本文中抓取的信息都很简单粗暴,也未对信息进行筛选等,在下来几章中,将会有对指定日期的招聘信息抓取、招聘详细
8c2a
信息的抓取的内容~

相关文章推荐
- python抓取招聘信息简单代码
- Python爬虫框架Scrapy实战之批量抓取招聘信息
- 【Python】抓取拉勾网全国Python的招聘信息
- python3.x爬虫实战:阿里巴巴网站定向信息抓取
- Python爬虫——4.4爬虫案例——requests和xpath爬取招聘网站信息
- Python3 简单抓取网站url
- Python使用scrapy抓取网站sitemap信息的方法
- Python3抓取页面信息,网络编程,简单发送QQ邮件
- python抓取简单页面信息
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- python urllib BeautifulSoup抓取去哪儿网站景点部分信息
- 使用python抓取网站信息
- python抓取南阳理工学院ACM网站排名信息
- <四>、python爬虫抓取购物网站商品信息--图片价格名称
- Python实现抓取百度搜索结果页的网站标题信息
- Python机器学习2-股票信息简单抓取
- 【python日常一】使用python抓取拉勾网职位信息并做简单统计分析
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- Python之简单抓取豆瓣读书信息