一次 select for update 的悲观锁使用引发的生产事故
2016-11-11 18:11
525 查看
1.事故描述
本月 8 日上午十点多,我们的基础应用发生生产事故。具体表象为系统出现假死无响应。查看事发时间段的基础应用 error 日志,没发现明显异常。查看基础应用业务日志,银行结果处理的部分普遍很慢,大都在十分钟以上。
2.AWR 报告
向 DBA 要了一下那个时间段的 AWR 报告,发现以下三个地方有些异常:2.1.CPU 利用率过高
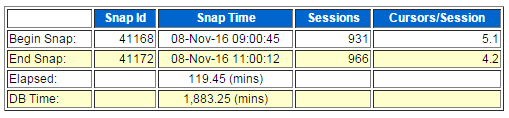
如上图所示,CPU利用率:1883.25分钟DB时间/(16核心*119.45分钟采样时间段时间) = 98.54%,CPU 利用率过高。
2.2.行锁等待严重
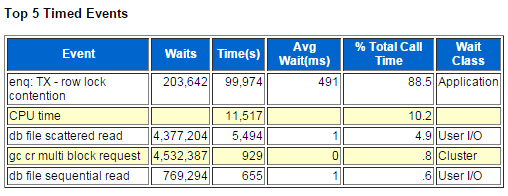
如上图"Top 5 Timed Events"所示,行锁等待占用了 80% 的 CPU 时间,基本可以确定它就是造成本次生产事故的直接元凶。
所以我们直接跳到"Wait Events"排行榜:
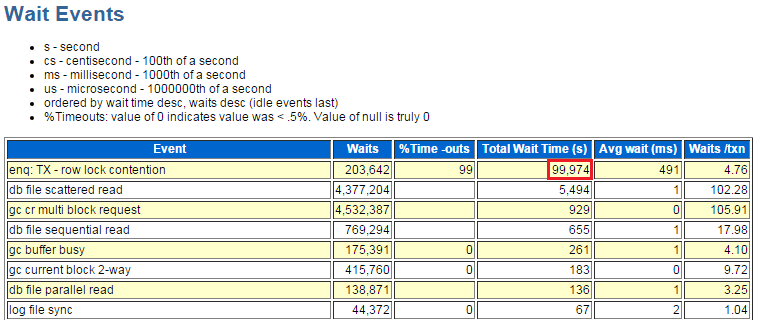
这说明了什么?在本次 AWR 报告的 09:00:45 - 11:00:12 大约 119.45 分钟的时间里,行锁等待的时间为 99974 秒,合 1666.23 分钟!
2.3.悲观锁慢查询严重
那么是什么操作造成行锁等待如此之严重呢?如此严重的行锁等待,慢查询统计列表里应该很突出地指示出来,我们直接跳到"SQL ordered by Elapsed Time"慢查询排行榜:
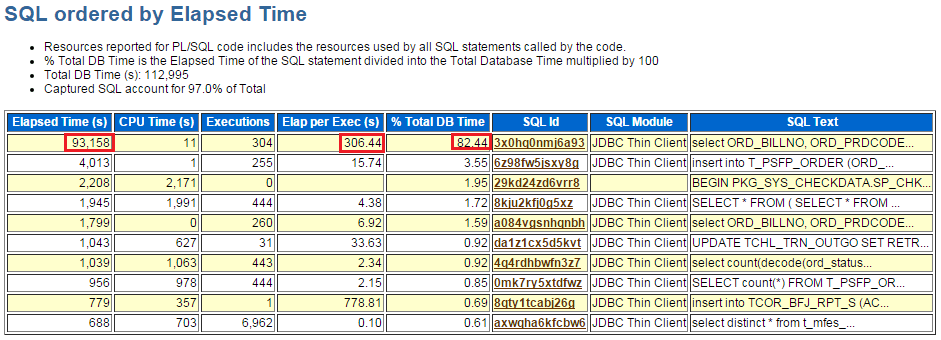
果不其然,两个小时的时间内,id 为 3x0hq0nmj6a93 的那条 sql 查询耗时 93158 秒(合 1552.63 分钟),平均每条执行时间为 306.44 秒(合 5.11 分钟),占用了 80% 以上的的 CPU。
让我们来看看这条 sql 的真面目吧:
select ORD_BILLNO, ORD_PRDCODE, ORD_CRCODE, ORD_MERBILLNO, ORD_PRETIME, ORD_DOTIME, ORD_MERTIME, ORD_MERCODEFROM, ORD_TYPEFROM, ORD_MERCODETO, ORD_TYPETO, ORD_ACCCODEFROM, ORD_ACCCODETO, ORD_AMT, ORD_STATUS, ORD_ATTACH, ORD_UPDATETIME, ORD_PRODUCT, ORD_REFUNDED, ORD_REFUSE, ORD_PREIP, ORD_ENDIP, ORD_BILLEXPTIME, ORD_DIRECTLY, ORD_SYSCODE, ORD_BRCCODE, ORD_SRCCODE, ORD_PAYEDAMT, TRD_CODE, RESV1, RESV2, RESV3, ORD_PRDCODE_OLD, TRD_CODE_OLD, ORD_USERACCTYPE from T_PSFP_ORDER_TMP where ORD_BILLNO = :1 for update
这是一条 select for update 数据库悲观锁查询语句,因为指定订单号,所以会锁定 T_PSFP_ORDER_TMP 表的某一条语句,印证了 2.2 中的结论。
3.代码分析
调用上述 sql 的代码:Order tempOrder = orderTempDao.selectOrderByPrimaryKeyForUpdate(verifyResult.getBillNo());
该业务代码先拿到该临时交易的锁,然后继续处理后续相当繁琐业务逻辑,中间还有大量的其它数据库操作,因为是声明式事务处理,所以在整个业务逻辑执行结束之后才会 commit,这段时间内如果还有其它 session 想拿这个行锁,就必须等到这一系列业务逻辑执行完毕。
正常情况下,这个逻辑是没问题的,但是在高并发的时候,这些业务逻辑受到 CPU 及网络等资源的限制可能会被拖慢,业务逻辑处理慢倒没什么,可怕的是数据库被拖慢,反过来又影响这些业务逻辑,形成一个滚雪球的效应,直至系统故障。
4.解决方案
技术中心不允许使用 select for update 悲观锁,尤其是在大量业务逻辑的情况下,至于原有业务逻辑可以使用其他处理方案进行替代。如必需使用 select for update,须与架构部讨论后才可使用。最后,关于Oracle AWR 报告的生成和分析请参考博客《Oracle AWR 报告的生成和分析》。

相关文章推荐
- 一次 select for update 的悲观锁使用引发的生产事故
- 又一例 select for update 的悲观锁使用所引发的血案
- mysql SELECT FOR UPDATE语句使用示例
- MySQL SELECT FOR UPDATE语句使用示例
- Mysql查询语句使用select.. for update导致的数据库死锁分析
- Oracle编辑数据时提示:这些查询结果不可更新,请使用ROWI或者SELECT……FOR UPDATE获得可更新结果。
- 这些查询结果不可更新,请包括ROWID或使用SELECT ...FOR UPDATE 获得可更新结果!
- select for update引发死锁分析
- mysql SELECT FOR UPDATE语句使用示例
- select...for update使用方法
- Mysql查询语句使用select.. for update导致的数据库死锁分析
- select * for update wait 3 行级锁使用以及测试方法;
- Select …forupdate语句是我们经常使用手工加锁语句。
- PL/SQL编辑数据"这些查询结果不可更新,请包括ROWID或使用SELECT...FOR UPDATE获得可更新结果"处理
- Oracle编辑数据时提示:这些查询结果不可更新,请使用ROWI或者SELECT……FOR UPDATE获得可更新结果
- MySQL 使用SELECT ... FOR UPDATE 做事务写入前的确认
- MySQL 使用SELECT ... FOR UPDATE 做事务写入前的确认(转)
- mysql SELECT FOR UPDATE语句使用示例
- PL/SQL编辑数据"这些查询结果不可更新,请包括ROWID或使用SELECT...FOR UPDATE获得可更新结果"处理
- 【转】PL/SQL编辑数据"这些查询结果不可更新,请包括ROWID或使用SELECT...FOR UPDATE获得可更新结果"处理