python学习笔记(3)--爬虫基础教程1
2016-11-07 11:46
711 查看
[align=center]Python学习笔记(3)-爬虫基础教程(1)[/align] 参考网页:【1】.爬虫:http://www.cnblogs.com/fnng/p/3576154.html
【2】.正则表达式:http://www.cnblogs.com/fnng/p/3576154.html
【3】.《Python爬虫学习系列教程》学习笔记 http://www.cnblogs.com/xin-xin/p/4297852.html
功能实现:从“糗事百科”上爬段子和作者#Python版本:3.4.2#和先前版本不一样的地方 1)print 后内容要加括号
2)except urllib2.URLError as e:这句在之前的版本中‘as’是由','代替的
url = 'http://www.qiushibaike.com/' #URL(统一资源定位符)信息 user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) ' #加一个header,否则访问不成功
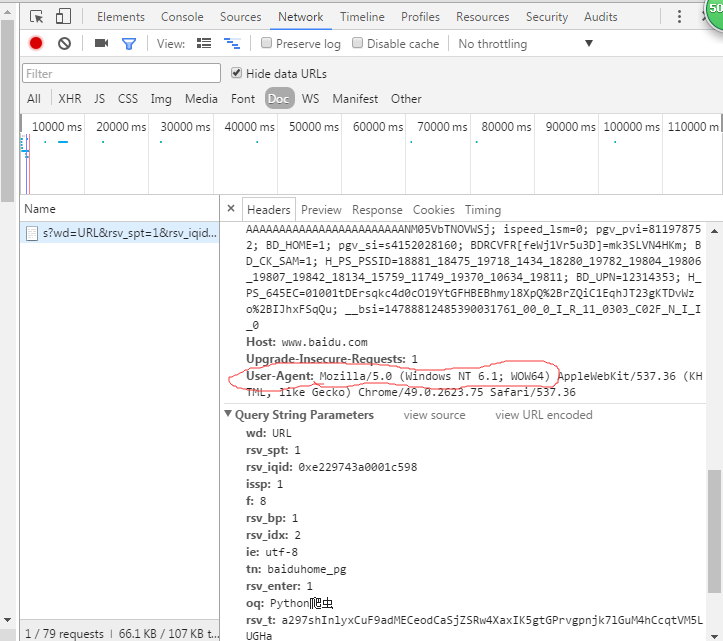
#header信息获取方式(谷歌浏览器): 自定义及控制--->更多工具--->开发者工具--->Network---->.....
#header验证部分,如果成功了就打印BEGIN
headers = { 'User-Agent' : user_agent } try: request = urllib2.Request(url,headers = headers) response = urllib2.urlopen(request) print ('BEGIN') except urllib2.URLError as e: if hasattr(e,"code"): print ('aaa') if hasattr(e,"reason"): print ('bbb')
content = response.read().decode('utf-8') #解码方式是utf-8
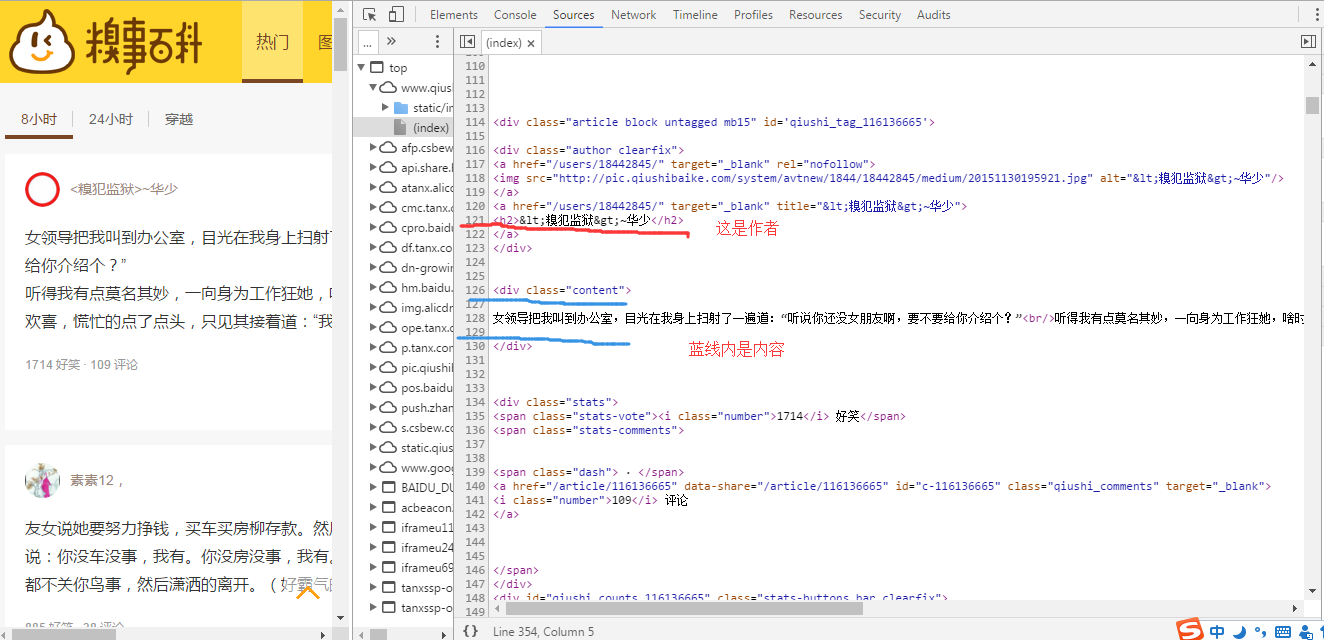
#这句正则表达式的两个(.*?)内分别是作者和内容,正则表达式参照日志开头参考网页【2】
#re.S表示多行匹配
pattern = re.compile('<h2>(.*?)</h2></a></div><div .*?"content">(.*?)<!--(.*?)--></div>',re.S)
#将所有爬到的东西存在items中 items = re.findall(pattern,content)
【2】.正则表达式:http://www.cnblogs.com/fnng/p/3576154.html
【3】.《Python爬虫学习系列教程》学习笔记 http://www.cnblogs.com/xin-xin/p/4297852.html
功能实现:从“糗事百科”上爬段子和作者#Python版本:3.4.2#和先前版本不一样的地方 1)print 后内容要加括号
2)except urllib2.URLError as e:这句在之前的版本中‘as’是由','代替的
Step 1 :
import re import urllib.request as urllib2 #在Python 3.X后urllib2变成了urllib.request,为了方便使用,就定义一个urllib2来代替Step 2:获取页面信息:
url = 'http://www.qiushibaike.com/' #URL(统一资源定位符)信息 user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) ' #加一个header,否则访问不成功
#header信息获取方式(谷歌浏览器): 自定义及控制--->更多工具--->开发者工具--->Network---->.....
#header验证部分,如果成功了就打印BEGIN
headers = { 'User-Agent' : user_agent } try: request = urllib2.Request(url,headers = headers) response = urllib2.urlopen(request) print ('BEGIN') except urllib2.URLError as e: if hasattr(e,"code"): print ('aaa') if hasattr(e,"reason"): print ('bbb')
Step 3. 用正则表达式筛选要爬下来的东西
content = response.read().decode('utf-8') #解码方式是utf-8#这句正则表达式的两个(.*?)内分别是作者和内容,正则表达式参照日志开头参考网页【2】
#re.S表示多行匹配
pattern = re.compile('<h2>(.*?)</h2></a></div><div .*?"content">(.*?)<!--(.*?)--></div>',re.S)
#将所有爬到的东西存在items中 items = re.findall(pattern,content)
4. 查看items中的东西
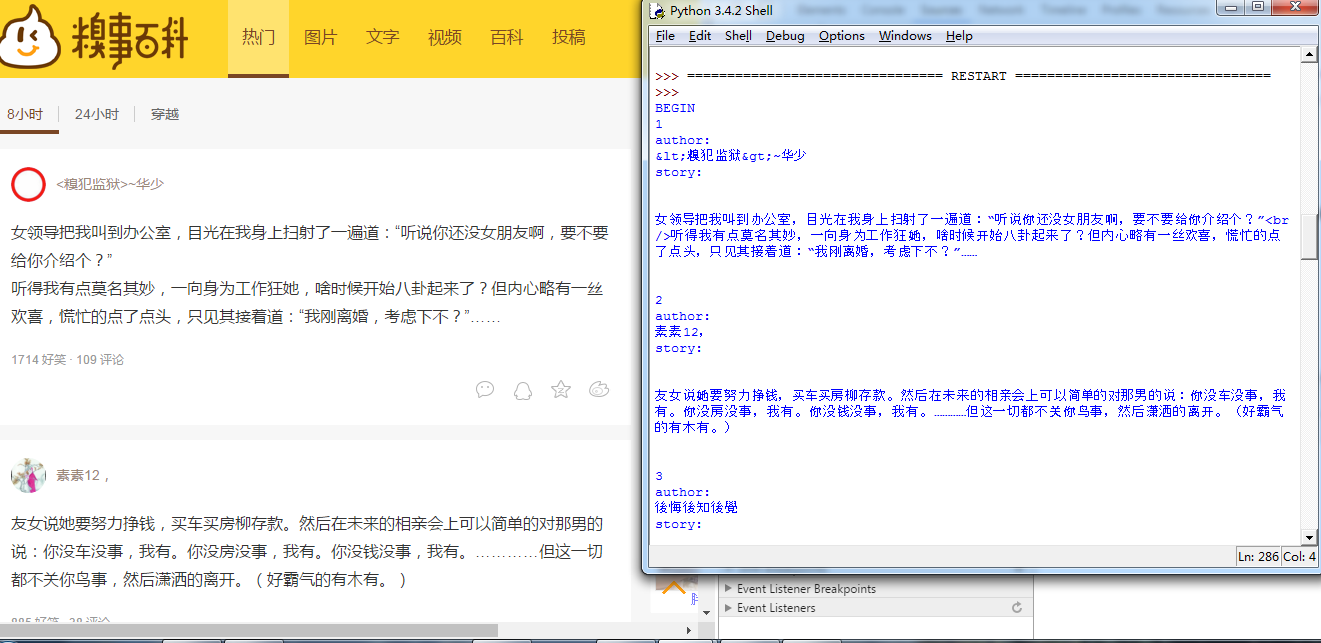
x=1 for item in items: print(x) print("author:") print (item[0]) #item[0]中是作者 print("story:") print(item[1]) #item[1]中是段子 x=x+1#结果截图

相关文章推荐
- python基础教程_学习笔记4:元组
- python基础教程_学习笔记9:抽象
- python基础教程_学习笔记14:标准库:一些最爱——re
- python基础教程_学习笔记13:标准库:一些最爱——sys
- python基础教程_学习笔记26:好玩的编程
- python基础教程_学习笔记5:字符串
- python基础教程_学习笔记17:标准库:一些最爱——time
- python基础教程_学习笔记24:网络编程、Python和万维网
- python基础教程_学习笔记19:标准库:一些最爱——集合、堆和双端队列
- python基础教程_学习笔记21:文件和素材
- Python基础教程学习笔记----第四章 字典
- Python基础教程学习笔记----第三章 字符串
- python基础教程_学习笔记11:魔法方法、属性和迭代器
- python基础教程_学习笔记22:数据库支持
- python基础教程_学习笔记2:序列-2
- python基础教程_学习笔记8:序列_练习与总结_1
- python基础教程_学习笔记10:异常
- python基础教程_学习笔记6:字典
- python基础教程_学习笔记23:图形用户界面
- python基础教程_学习笔记18:标准库:一些最爱——shelve