MAC系统中搭建Spark大数据平台(包括Scala)
2016-11-01 21:12
411 查看
MAC系统中搭建Spark大数据平台(包括Scala)
总体介绍:大家Spark大数据平台,包括三部分内容:JDK,Scala,Spark
这三者是依次依赖的关系,Spark依赖于Scala环境(Spark是使用Scala语言开发),Scala语言必须运行与JVM上,所以,Scala依赖于Java环境。
1、JDK安装
确保你本地以及安装了 JDK 1.5 以上版本,并且设置了 JAVA_HOME 环境变量及 JDK 的bin目录。
大家可以自行搜索相关安装,最后需要验证一下是否安装成功:
1.1 java安装是否成功:
localhost:~ didi$ java -version java version "1.8.0_102" Java(TM) SE Runtime Environment (build 1.8.0_102-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.102-b14, mixed mode)
1.2 java编译器安装是否成功:
localhost:~ didi$ javac -version javac 1.8.0_102
如果大家Java环境没有安装成功,可以参考:java环境安装和配置
2、Scala环境配置
Spark运行的基础是Scala。Scala安装非常简单,两步1、下载scala压缩包;2、配置Scala的bin目录的环境变量
2.1 下载Scala压缩包
Scala官网下载地址:下载地址
2.2 解压缩
将Scala压缩包scala-2.11.8.tgz解压缩到/usr/local/Cellar文件夹下面,生成scala-2.11.8文件夹
2.3 配置环境变量
使用sudo su进入管理员权限,配置/etc/profile文件,添加如下内容:
export PATH="$PATH:/usr/local/Cellar/scala-2.11.8/bin"
2.4 测试安装是否成功:
localhost:~ didi$ scala Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_102). Type in expressions for evaluation. Or try :help. scala>
OK!Scala安装成功。
3、Spark环境安装和配置
3.1 下载Spark压缩包spark-2.0.1-bin-hadoop2.7.tgz
官网下载地址:点击这里,我选择下载的版本如下:
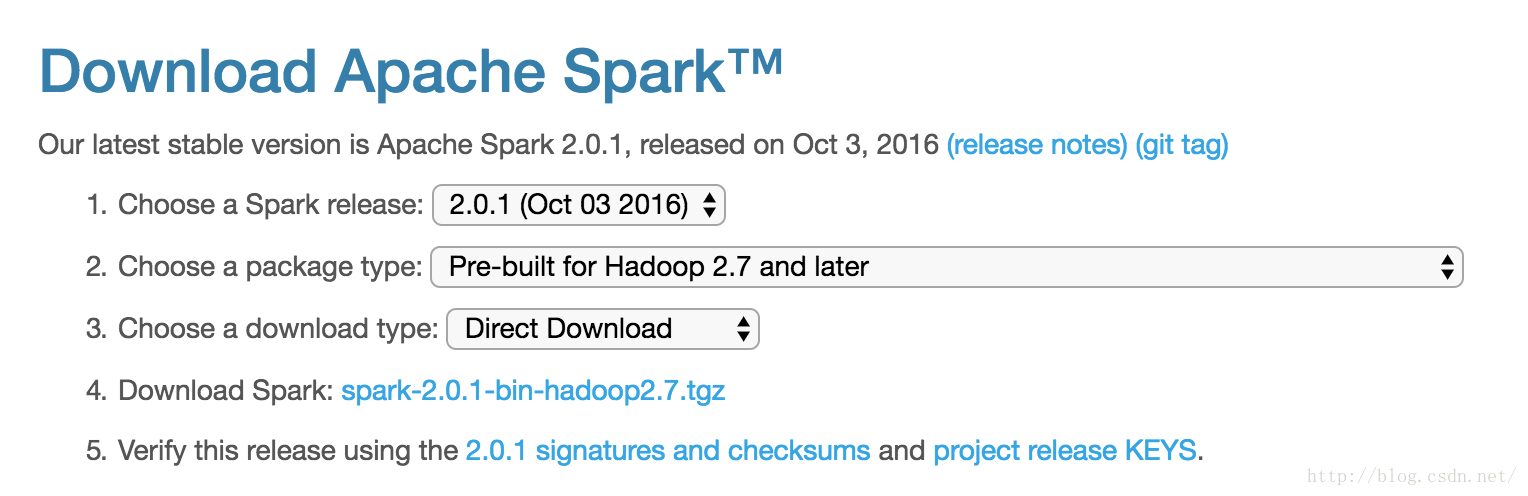
3.2 解压缩压缩文件到指定文件夹/usr/local/Cellar,生成spark-2.0.1-bin-hadoop2.7文件夹
tar -zxvf spark-1.2.0-bin-hadoop1.tgz
3.3 配置环境变量
使用sudo su进入管理员权限,配置/etc/profile文件,添加如下内容:
export PATH="$PATH:/usr/local/Cellar/spark-2.0.1-bin-hadoop2.7/bin"3.4 修改Spark的配置文件conf目录
cp spark-env.sh.template spark-env.sh
修改spark-env.sh中的内容,加入如下配置:
</pre><pre code_snippet_id="1961561" snippet_file_name="blog_20161101_7_9283581" name="code" class="html">export SCALA_HOME=/usr/local/Cellar/scala-2.11.8/bin export SPARK_MASTER_IP=localhost export SPARK_WORKER_MEMORY=4g3.5 运行Spark
./start-all.sh
3.6 使用spark shell进行测试
localhost:bin didi$ spark-shell Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). 16/11/01 21:09:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 16/11/01 21:09:47 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 10.97.182.157 instead (on interface en0) 16/11/01 21:09:47 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 16/11/01 21:09:48 WARN SparkContext: Use an existing SparkContext, some configuration may not take effect. Spark context Web UI available at http://10.97.182.157:4040 Spark context available as 'sc' (master = local[*], app id = local-1478005788625). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.0.1 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_102) Type in expressions to have them evaluated. Type :help for more information. scala>
OK!Spark环境搭建成功!
总结,在安装环境的时候,我们需要首先弄清楚各个环境和依赖之间的关系,这样安装和配置环境的时候,会更加的自信和有条理。
祝大家学习和工作顺利。共同研究大数据。

相关文章推荐
- 利用Eclipse构建Spark集成开发环境(包括scala环境的搭建)
- 利用Eclipse构建Spark集成开发环境(包括scala环境的搭建)
- mac平台scala开发环境搭建
- Spark项目之电商用户行为分析大数据平台之(三)大数据集群的搭建
- Spark1.6.1平台搭建(hadoop-2.7.2 scala-2.11.8)
- spark大数据平台导出特定IP日志 scala脚本
- 大数据平台搭建之scala
- 【Cocos2D-X学习笔记】Mac系统下Android平台环境搭建
- python数据分析笔记(1):搭建python的数据分析环境(Mac系统下)
- mac平台scala开发环境搭建
- 大数据平台搭建-spark集群安装
- Spark项目之电商用户行为分析大数据平台之(十)IDEA项目搭建及工具类介绍
- hadoop大数据平台手动搭建(六)-spark
- Ambari——大数据平台的搭建利器之进阶篇[配置spark]
- Python 学习之中的一个:在Mac OS X下基于Sublime Text搭建开发平台包括numpy,scipy
- 利用Intellij IDEA构建Spark开发环境(包括scala环境的搭建)
- WEB信息管理系统、数据展现分析系统 快速搭建平台
- Spark项目之电商用户行为分析大数据平台之(二)CentOS7集群搭建
- Mac系统下搭建Ruby on Rails开发环境
- 影院平台搭建 - (11)记录reiser文件系统故障一次