模糊c均值聚类和k-means聚类的数学原理
2016-10-31 19:03
232 查看
摘要
这篇博客是从一个网上下载的资料关于模糊c均值聚类和k-means均值聚类的数学方法衍生而来。我下载的那个文章讨论的不是很清楚,还有一些错误的地方,有些直接给了结果,但是中间的数学推导没有给出,我感觉中间的数学推导应该是最精华的地方,上网搜发现网上对于这两个算法的数学推导还是很少的甚至是没有,百度文库有一篇,但是推导的是用穷举找规律,数学的味道不是很浓厚。在这篇文章的基础上,我增加了一些数学方面的理论推导,讲的更加的详细了一些,特别是在模糊c均值聚类的递推公式的推导上,需要具有一定的数学功底。这是我一天的成果,就把这个记录下来了啊,希望对大家有帮助,同时也可以为以后自己的复习做备份。算法其实很简单,但是知其然并知其所以然却很难。k-means的算法数学推导原理:http://9269309.blog.51cto.com/9259309/1864214
FCM聚类算法介绍FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则是一种柔性的模糊划分。在介绍FCM具体算法之前我们先介绍一些模糊集合的基本知识。模糊集基本知识[21]
首先说明隶属度函数的概念。隶属度函数是表示一个对象x隶属于集合A的程度的函数,通常记做μA(x),其自变量范围是所有可能属于集合A的对象(即集合A所在空间中的所有点),取值范围是[0,1],即0<=μA(x)<=1。μA(x)=1表示x完全隶属于集合A,相当于传统集合概念上的x∈A。一个定义在空间X={x}上的隶属度函数就定义了一个模糊集合A,或者叫定义在论域X={x}上的模糊子集 。对于有限个对象x1,x2,……,xn模糊集合 可以表示为:
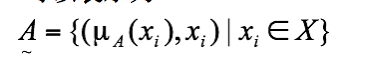
.............. (6.1)
有了模糊集合的概念,一个元素隶属于模糊集合就不是硬性的了,在聚类的问题中,可以把聚类生成的簇看成模糊集合,因此,每个样本点隶属于簇的隶属度就是[0,1]区间里面的值。K均值聚类算法(HCM)介绍
K均值聚类,即众所周知的C均值聚类,已经应用到各种领域。它的核心思想如下:算法把n个向量xj(1,2…,n)分为c个组Gi(i=1,2,…,c),并求每组的聚类中心,使得非相似性(或距离)指标的价值函数(或目标函数)达到最小。当选择欧几里德距离为组j中向量xk与相应聚类中心ci间的非相似性指标时,价值函数可定义为:
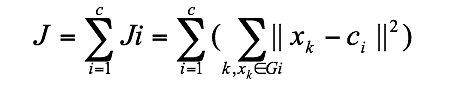
.............. (6.2)其中
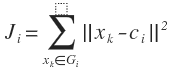
是组i内的价值函数。这样Ji的值依赖于Gi的几何特性和ci的位置。一般来说,可用一个通用距离函数d(xk,ci)代替组I中的向量xk,则相应的总价值函数可表示为:
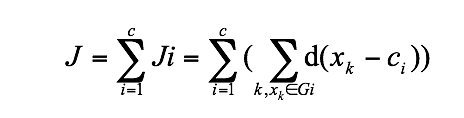
........ (6.3)为简单起见,这里用欧几里德距离作为向量的非相似性指标,且总的价值函数表示为(6.2)式。划分过的组一般用一个c×n的二维隶属矩阵U来定义。如果第j个数据点xj属于组i,则U中的元素uij为1;否则,该元素取0。一旦确定聚类中心ci,可导出如下使式(6.2)最小uij:
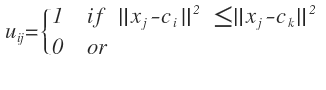
(6.4)重申一点,如果ci是xj的最近的聚类中心,那么xj属于组i。由于一个给定数据只能属于一个组,所以隶属矩阵U具有如下性质:
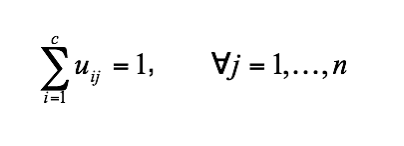
(6.5)且
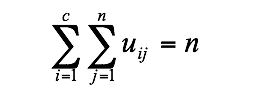
(6.6)另一方面,如果固定uij则使(6.2)式最小的最佳聚类中心就是组I中所有向量的均值: ,
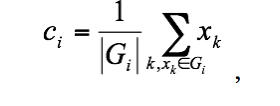
(6.7)这里|Gi|是第i个簇中元素对象的个数为便于批模式运行,这里给出数据集xi(1,2…,n)的K均值算法;该算法重复使用下列步骤,确定聚类中心ci和隶属矩阵U:步骤1:初始化聚类中心ci,i=1,…,c。典型的做法是从所有数据点中任取c个点。步骤2:用式(6.4)确定隶属矩阵U。步骤3:根据式(6.2)计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数质的改变量小于某个阀值,则算法停止。步骤4:根据式(6.5)修正聚类中心。返回步骤2。该算法本身是迭代的,且不能确保它收敛于最优解。K均值算法的性能依赖于聚类中心的初始位置。所以,为了使它可取,要么用一些前端方法求好的初始聚类中心;要么每次用不同的初始聚类中心,将该算法运行多次。此外,上述算法仅仅是一种具有代表性的方法;我们还可以先初始化一个任意的隶属矩阵,然后再执行迭代过程。K均值算法也可以在线方式运行。这时,通过时间平均,导出相应的聚类中心和相应的组。即对于给定的数据点x,该算法求最近的聚类中心ci,并用下面公式进行修正:
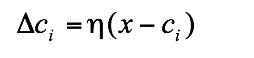
(6.8)这种在线公式本质上嵌入了许多非监督学习神经元网络的学习法则。6.2.3 模糊C均值聚类模糊C均值聚类(FCM),即众所周知的模糊ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。1973年,Bezdek提出了该算法,作为早期硬C均值聚类(HCM)方法的一种改进。FCM把n个向量xi(i=1,2,…,n)分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM与HCM的主要区别在于FCM用模糊划分,使得每个给定数据点用值在0,1间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵U允许有取值在0,1间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于1:
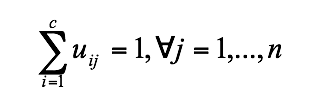
(6.9)那么,FCM的价值函数(或目标函数)就是式(6.2)的一般化形式: ,
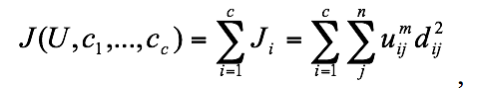
(6.10)这里uij介于0,1间;ci为模糊组I的聚类中心,dij=||ci-xj||为第I个聚类中心与第j个数据点间的欧几里德距离;且 是一个加权指数。构造如下新的目标函数,可求得使(6.10)式达到最小值的必要条件:
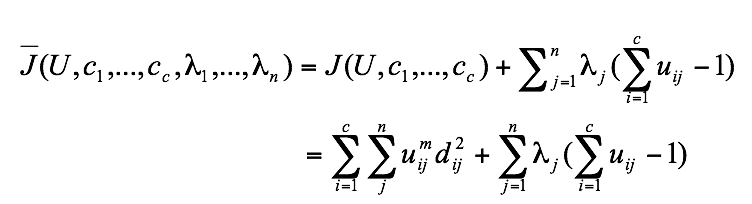
(6.11)这里λj,j=1到n,是(6.9)式的n个约束式的拉格朗日乘子。对所有输入参量求导,使式(6.10)达到最小的必要条件为:
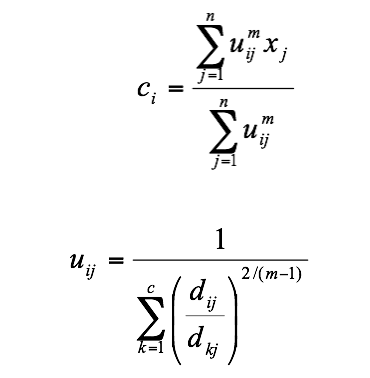
......... 6.12由上述两个必要条件,模糊C均值聚类算法是一个简单的迭代过程。在批处理方式运行时,FCM用下列步骤确定聚类中心ci和隶属矩阵U[1]:步骤1:用值在0,1间的随机数初始化隶属矩阵U,使其满足式(6.9)中的约束条件步骤2:用式(6.12)计算c个聚类中心ci,i=1,…,c。步骤3:根据式(6.10)计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数值的改变量小于某个阀值,则算法停止。步骤4:用(6.13)计算新的U矩阵。返回步骤2。上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保FCM收敛于一个最优解。算法的性能依赖于初始聚类中心。因此,我们要么用另外的快速算法确定初始聚类中心,要么每次用不同的初始聚类中心启动该算法,多次运行FCM。对于式(6.12)结果的推导的数学原理:
FCM算法的数学模型其实是一个条件极值问题:
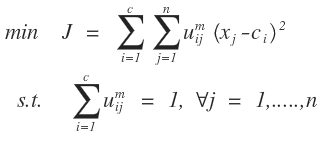
我们需要把上面的条件极值问题转化为无条件的极值问题,这个在数学分析上经常用到的一种方法就是拉格朗日乘数法把条件极值转化为无条件极值问题,需要引入n个拉格朗日因子,如下所示:
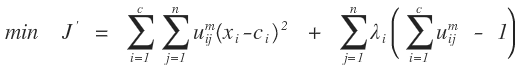
然后对各个变量进行求导,从而得到各个变量的极值点:对C中心点进行求导:
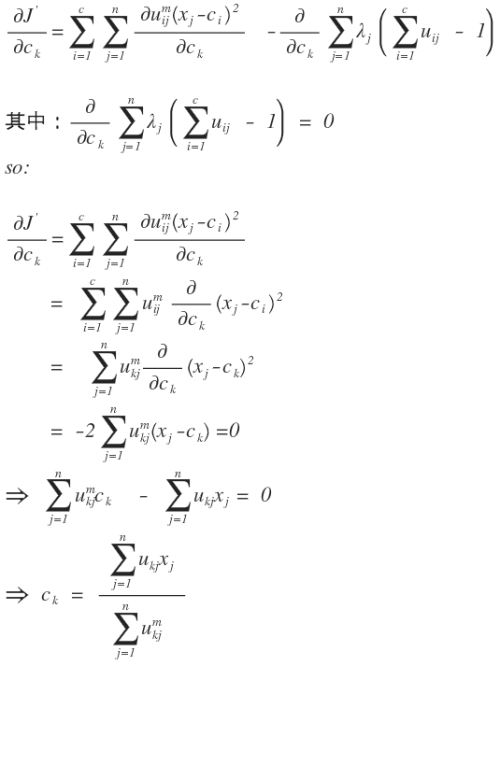
拉格朗日函数分为两部分,我们需要分别对其进行求导,先算简单的,对后一部分进行求导:
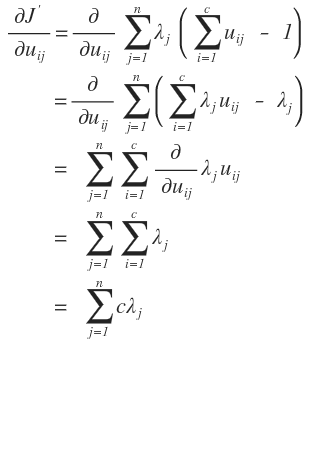
对前一部分进行求导就比较复杂和困难了:
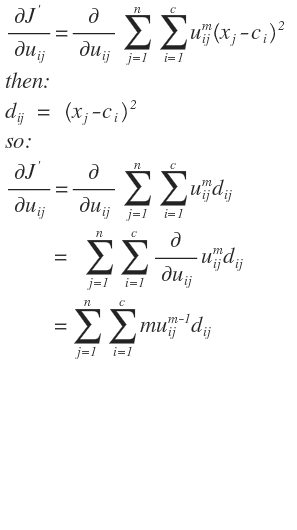
把两部分放到一起则是:
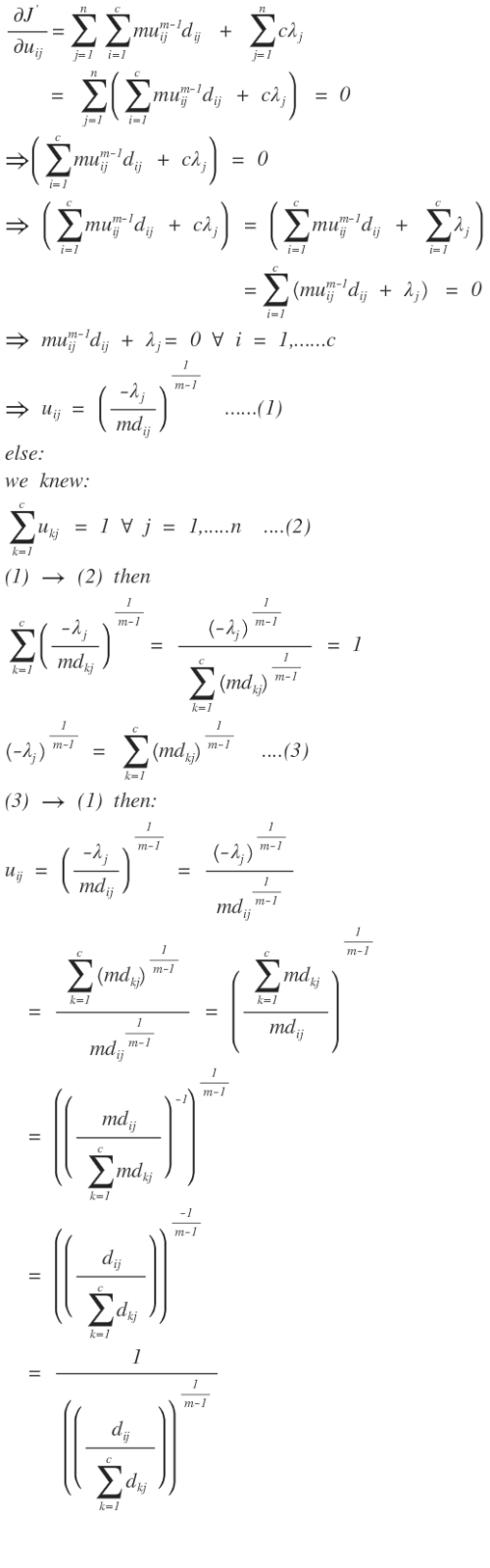
上面的一些公式用到了英文,不是我装,我的英语很差的,我用的google公式编辑器不能打汉字,没办法,凑活着看吧。上式推导中的一些点的解释:
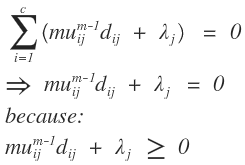
FCM算法的应用
通过上面的讨论,我们不难看出FCM算法需要两个参数一个是聚类数目C,另一个是参数m。一般来讲C要远远小于聚类样本的总个数,同时要保证C>1。对于m,它是一个控制算法的柔性的参数,如果m过大,则聚类效果会很次,而如果m过小则算法会接近HCM聚类算法。算法的输出是C个聚类中心点向量和C*N的一个模糊划分矩阵,这个矩阵表示的是每个样本点属于每个类的隶属度。根据这个划分矩阵按照模糊集合中的最大隶属原则就能够确定每个样本点归为哪个类。聚类中心表示的是每个类的平均特征,可以认为是这个类的代表点。从算法的推导过程中我们不难看出,算法对于满足正态分布的数据聚类效果会很好,另外,算法对孤立点是敏感的。
这篇博客是从一个网上下载的资料关于模糊c均值聚类和k-means均值聚类的数学方法衍生而来。我下载的那个文章讨论的不是很清楚,还有一些错误的地方,有些直接给了结果,但是中间的数学推导没有给出,我感觉中间的数学推导应该是最精华的地方,上网搜发现网上对于这两个算法的数学推导还是很少的甚至是没有,百度文库有一篇,但是推导的是用穷举找规律,数学的味道不是很浓厚。在这篇文章的基础上,我增加了一些数学方面的理论推导,讲的更加的详细了一些,特别是在模糊c均值聚类的递推公式的推导上,需要具有一定的数学功底。这是我一天的成果,就把这个记录下来了啊,希望对大家有帮助,同时也可以为以后自己的复习做备份。算法其实很简单,但是知其然并知其所以然却很难。k-means的算法数学推导原理:http://9269309.blog.51cto.com/9259309/1864214
FCM聚类算法介绍FCM算法是一种基于划分的聚类算法,它的思想就是使得被划分到同一簇的对象之间相似度最大,而不同簇之间的相似度最小。模糊C均值算法是普通C均值算法的改进,普通C均值算法对于数据的划分是硬性的,而FCM则是一种柔性的模糊划分。在介绍FCM具体算法之前我们先介绍一些模糊集合的基本知识。模糊集基本知识[21]
首先说明隶属度函数的概念。隶属度函数是表示一个对象x隶属于集合A的程度的函数,通常记做μA(x),其自变量范围是所有可能属于集合A的对象(即集合A所在空间中的所有点),取值范围是[0,1],即0<=μA(x)<=1。μA(x)=1表示x完全隶属于集合A,相当于传统集合概念上的x∈A。一个定义在空间X={x}上的隶属度函数就定义了一个模糊集合A,或者叫定义在论域X={x}上的模糊子集 。对于有限个对象x1,x2,……,xn模糊集合 可以表示为:
.............. (6.1)
有了模糊集合的概念,一个元素隶属于模糊集合就不是硬性的了,在聚类的问题中,可以把聚类生成的簇看成模糊集合,因此,每个样本点隶属于簇的隶属度就是[0,1]区间里面的值。K均值聚类算法(HCM)介绍
K均值聚类,即众所周知的C均值聚类,已经应用到各种领域。它的核心思想如下:算法把n个向量xj(1,2…,n)分为c个组Gi(i=1,2,…,c),并求每组的聚类中心,使得非相似性(或距离)指标的价值函数(或目标函数)达到最小。当选择欧几里德距离为组j中向量xk与相应聚类中心ci间的非相似性指标时,价值函数可定义为:
.............. (6.2)其中
是组i内的价值函数。这样Ji的值依赖于Gi的几何特性和ci的位置。一般来说,可用一个通用距离函数d(xk,ci)代替组I中的向量xk,则相应的总价值函数可表示为:
........ (6.3)为简单起见,这里用欧几里德距离作为向量的非相似性指标,且总的价值函数表示为(6.2)式。划分过的组一般用一个c×n的二维隶属矩阵U来定义。如果第j个数据点xj属于组i,则U中的元素uij为1;否则,该元素取0。一旦确定聚类中心ci,可导出如下使式(6.2)最小uij:
(6.4)重申一点,如果ci是xj的最近的聚类中心,那么xj属于组i。由于一个给定数据只能属于一个组,所以隶属矩阵U具有如下性质:
(6.5)且
(6.6)另一方面,如果固定uij则使(6.2)式最小的最佳聚类中心就是组I中所有向量的均值: ,
(6.7)这里|Gi|是第i个簇中元素对象的个数为便于批模式运行,这里给出数据集xi(1,2…,n)的K均值算法;该算法重复使用下列步骤,确定聚类中心ci和隶属矩阵U:步骤1:初始化聚类中心ci,i=1,…,c。典型的做法是从所有数据点中任取c个点。步骤2:用式(6.4)确定隶属矩阵U。步骤3:根据式(6.2)计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数质的改变量小于某个阀值,则算法停止。步骤4:根据式(6.5)修正聚类中心。返回步骤2。该算法本身是迭代的,且不能确保它收敛于最优解。K均值算法的性能依赖于聚类中心的初始位置。所以,为了使它可取,要么用一些前端方法求好的初始聚类中心;要么每次用不同的初始聚类中心,将该算法运行多次。此外,上述算法仅仅是一种具有代表性的方法;我们还可以先初始化一个任意的隶属矩阵,然后再执行迭代过程。K均值算法也可以在线方式运行。这时,通过时间平均,导出相应的聚类中心和相应的组。即对于给定的数据点x,该算法求最近的聚类中心ci,并用下面公式进行修正:
(6.8)这种在线公式本质上嵌入了许多非监督学习神经元网络的学习法则。6.2.3 模糊C均值聚类模糊C均值聚类(FCM),即众所周知的模糊ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。1973年,Bezdek提出了该算法,作为早期硬C均值聚类(HCM)方法的一种改进。FCM把n个向量xi(i=1,2,…,n)分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM与HCM的主要区别在于FCM用模糊划分,使得每个给定数据点用值在0,1间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵U允许有取值在0,1间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于1:
(6.9)那么,FCM的价值函数(或目标函数)就是式(6.2)的一般化形式: ,
(6.10)这里uij介于0,1间;ci为模糊组I的聚类中心,dij=||ci-xj||为第I个聚类中心与第j个数据点间的欧几里德距离;且 是一个加权指数。构造如下新的目标函数,可求得使(6.10)式达到最小值的必要条件:
(6.11)这里λj,j=1到n,是(6.9)式的n个约束式的拉格朗日乘子。对所有输入参量求导,使式(6.10)达到最小的必要条件为:
......... 6.12由上述两个必要条件,模糊C均值聚类算法是一个简单的迭代过程。在批处理方式运行时,FCM用下列步骤确定聚类中心ci和隶属矩阵U[1]:步骤1:用值在0,1间的随机数初始化隶属矩阵U,使其满足式(6.9)中的约束条件步骤2:用式(6.12)计算c个聚类中心ci,i=1,…,c。步骤3:根据式(6.10)计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数值的改变量小于某个阀值,则算法停止。步骤4:用(6.13)计算新的U矩阵。返回步骤2。上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保FCM收敛于一个最优解。算法的性能依赖于初始聚类中心。因此,我们要么用另外的快速算法确定初始聚类中心,要么每次用不同的初始聚类中心启动该算法,多次运行FCM。对于式(6.12)结果的推导的数学原理:
FCM算法的数学模型其实是一个条件极值问题:
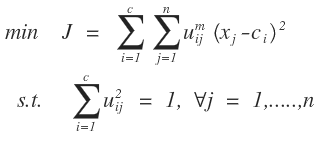
我们需要把上面的条件极值问题转化为无条件的极值问题,这个在数学分析上经常用到的一种方法就是拉格朗日乘数法把条件极值转化为无条件极值问题,需要引入n个拉格朗日因子,如下所示:
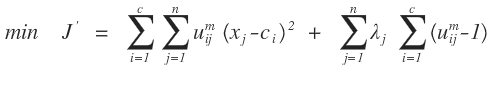
然后对各个变量进行求导,从而得到各个变量的极值点:对C中心点进行求导:

拉格朗日函数分为两部分,我们需要分别对其进行求导,先算简单的,对后一部分进行求导:
对前一部分进行求导就比较复杂和困难了:
把两部分放到一起则是:
上面的一些公式用到了英文,不是我装,我的英语很差的,我用的google公式编辑器不能打汉字,没办法,凑活着看吧。上式推导中的一些点的解释:
FCM算法的应用
通过上面的讨论,我们不难看出FCM算法需要两个参数一个是聚类数目C,另一个是参数m。一般来讲C要远远小于聚类样本的总个数,同时要保证C>1。对于m,它是一个控制算法的柔性的参数,如果m过大,则聚类效果会很次,而如果m过小则算法会接近HCM聚类算法。算法的输出是C个聚类中心点向量和C*N的一个模糊划分矩阵,这个矩阵表示的是每个样本点属于每个类的隶属度。根据这个划分矩阵按照模糊集合中的最大隶属原则就能够确定每个样本点归为哪个类。聚类中心表示的是每个类的平均特征,可以认为是这个类的代表点。从算法的推导过程中我们不难看出,算法对于满足正态分布的数据聚类效果会很好,另外,算法对孤立点是敏感的。

相关文章推荐
- 聚类(三)FUZZY C-MEANS 模糊c-均值聚类算法——本质和逻辑回归类似啊
- 机器学习算法原理总结系列---算法基础之(13)模糊C均值聚类(Fuzzy C-means Clustering)
- 机器学习算法与Python实践之(五)k均值聚类(k-means)原理补充
- 机器学习算法原理总结系列---算法基础之(11)聚类K均值(Clustering K-means)
- FCM(Fuzzy C-Means)模糊C聚类
- [转载]遗传算法改进的模糊C-均值聚类MATLAB源码
- 直觉模糊C均值聚类与图像阈值分割
- K-Means聚类原理 及与EM关联
- k均值聚类(K-means)(转载)
- 算法杂货铺——k均值聚类(K-means)
- 模糊C均值聚类(FCM)算法
- k-means(k均值聚类)算法介绍及实现(c++)
- k-means、GMM聚类、KNN原理概述
- Mahout机器学习系列之-模糊c-均值聚类和狄利克雷过程聚类
- 机器学习(二)——K-均值聚类(K-means)算法
- 机器学习笔记----Fuzzy c-means(FCM)模糊聚类详解及matlab实现
- k均值聚类(K-means)
- k均值聚类(k-means)
- 机器学习算法与Python实践之(五)k均值聚类(k-means)
- 算法杂货铺——k均值聚类(K-means)