read代码阅读一(linux3.10.14)
2016-10-30 11:07
204 查看
引言
一个完整的read流程涉及的模块比较多,本文章依次对read涉及的各个模块做个简单描述。一、read涉及的子系统
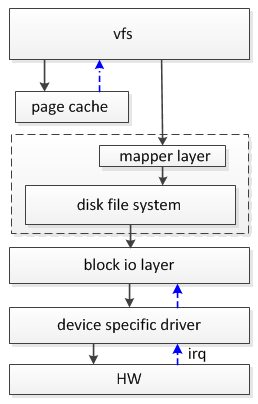
用户态调用SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t,count)进入vfs。vfs先把数据存放在内核page中,然后从page中拷贝需要的数据到用户态缓存中。
二、页缓存page cache
page cache的目的是为了提高文件系统的读写性能。设计思想是,把访问过的文件数据存保留在page中,读写文件时只需对page操作就可以了,从而避免耗时的磁盘IO操作。对于read而言,如果page cache没有需要的数据页,或者数据页为PG_dirty,那就需要启动一次磁盘IO操作把磁盘上的数据读到page中,并把page状态设为PG_uptodate,最后把page中对应的数据拷贝到用户态buf中。
对于write而言,如果page cache中没有需要的数据页,同read一样需要把磁盘中的数据读到page中,然后对page执行写操作。如果数据页为PG_dirty,这说明page中的数据一定比磁盘块数据新(nfs不一定),所以只需对page直线写操作即可,也不用考虑磁盘数据。
一个文件的所有page缓存,存放在inode->address_space空间中,address_space采用radix tree方式管理page,inode->address_space->page_tree指向树根radix_tree_root。
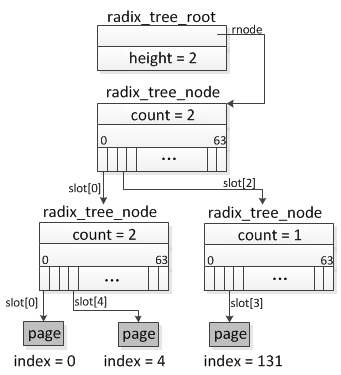
文件的偏移(file->f_pos)转换成page index,radix_tree通过index来管理radix tree中的page。page index从bit0到bit31分为几段,每段6个bit(最后一个段2bit),被用来做radix_tree_node的slot数组索引,代码中用radix_tree_node->slots[RADIX_TREE_MAP_SIZE]来表示这个数组。在上面图中,树的高度为2,所以只需要用到2个6bit的位段,高位段(bit11~bit6)用来表示第一层节点中slot数组的索引,低位段(bit5~bit0)用来表示第二层节点中slot数组索引,第二层数组slot中的元素是叶子节点,表示page。
3.10.14版本中为每个中间节点都包含子节点的一些状态标记,radix_tree_node->tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS],一共有3个:
PAGECACHE_TAG_DIRTY 表示子节点中存在脏页
PAGECACHE_TAG_WRITEBACK 表示子节点中有页正在回写到磁盘
PAGECACHE_TAG_TOWRITE 表示子节点中有页将要被回写到磁盘
三、映射层mapper layer
当数据需要从磁盘上读取时,就需要经过mapper layer将文件偏移量对应的逻辑块号转换成磁盘上的物理块号,然后才能从磁盘上读取数据。不同的磁盘文件系统,mapper layer机制不一样,以ext3为例,它采用了直接寻址与间接寻址结合的方式。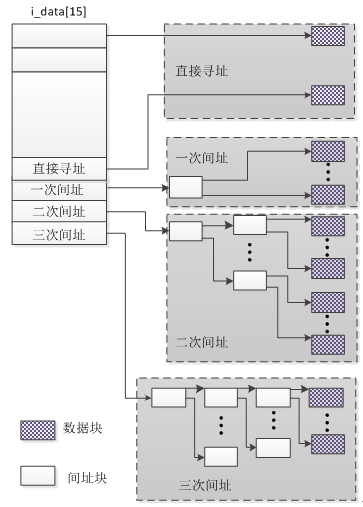
文件偏移量file->f_pos转换成page index后,乘以blocks per page,得到逻辑块号。inode->i_data[15]前12个元素存放的是数据物理块号,i_data[12]存放的是一个间址块号,这个间址块按4字节划分成,每个小块中存放的物理数据物理块号,由于用到了一个间址块,所以称为一级间址。i_data[13]是二级间址,i_data[14]是三级间址。
四、磁盘文件系统disk filesystem
以ext3文件系统为例,磁盘的划分如下:
文件数据包括两部分,元数据以及普通数据,磁盘文件系统要做的事情就是存储管理这些数据。每个磁盘文件系统有各自的特点,以后针对具体的磁盘文件系统细说。
五、块设备io层block io layer
块设备io层用来对提交的io请求根据sector号排序、合并,使磁头以一个合理的次序访问这些物理扇区,减少磁头移动距离,从而到达较优的性能。比如第一个io请求sector号为5,第7二个io请求扇区号为20,第三个请求扇区号为7,如果不排序,那么磁头以5→20→7这样的次序移动,而排序后只需要以5→7→20这样移动。合并后的bio生成request,request存放在request queue中(又称为dispatch list),每个磁盘有一个这样的request queue,这个队列中的request会被转换成底层驱动的command下发到驱动中。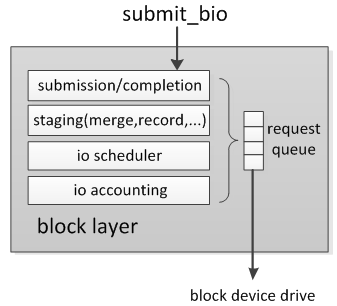
块设备层的数据结构是bio,用来描述磁盘上的数据位置、内存数据位置(对于read、write而言,需要关心的就是磁盘数据位置、内存存放位置)。
现在的磁盘支持scatter-gather模式,在读操作中控制器从相邻磁盘扇区中获得数据,然后将他们存放在不同的内存区中。bio->bi_sector描述了磁盘上的起始扇区号。bio->bi_io_vec是一个数组,每一个元素称为段,描述的是内存数据位置,对应一个内存区,如果是scatter-gather模式,那就可能有多个段。
submit_bio流程:
submit_bio-->generic_make_request--> q->make_request_fn(q,bio)
每个block初始化时会设置make_request_fn,对于scsi磁盘:
scsi_alloc_queue-->__scsi_alloc_queue--> blk_init_queue--> blk_init_queue_node --> blk_init_allocated_queue--> blk_queue_make_request(q, blk_queue_bio)
所以q->make_request_fn即blk_queue_bio
bio的合并:
因为磁盘的机械特性,移动磁头的时间比较长,所以需要根据bio读写的磁盘扇区号对bio进行排序合并,合并的原则一般是bio的扇区号与已有的request是否连续。当bio合并到request中后,这个request有与相邻的request存在扇区号连续的可能,所以需要对request再尝试合并一次。先尝试合并到pluglist中,合并失败的话再尝试合并到调度器中。
引入plug list是因为这个list是每个进程自己的,合并bio时,不需要获取q lock,避免锁争用。
bio无法合并到plug list,需要通过elv_merge将bio合并到调度器某个request中,bio合并成功的话还需要再通过elv_merged_request继续对request合并。bio合并完成后,这个request肯定是在调度器中了,系统后继肯定会从调度器中取出这个io放到磁盘的queue中,并将queue中的request逐个下发到驱动层。
request的申请:
如果bio不能完成上面的合并,就会通过get_request申请一个新的request结构,然后通过init_request_from_bio初始化把bio加入到这个新的request。
如果打开了plug list,那么把这个request暂时放在plug list中。
如果打开了plug list,那么把这个request暂时放在plug list中。 如果没有打开plug list,通过add_acct_request把新request加入到调度器中。接着执行__blk_run_queue-->__blk_run_queue_uncond-->q->request_fn这个函数是scsi_request_fn
9a1b
六、块设备驱动层
scsi_request_fn循环处理gendisk的rq,将rq封装成cmd传给low-level driver。当gendisk没有rq需要处理,或者low-level driver不能再接受更多的rq时,退出循环。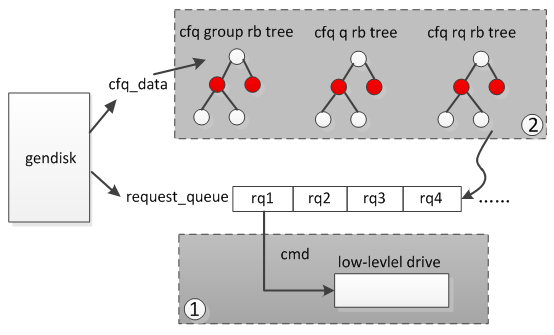
scsi_request_fn首先从request_queue(也就是dispatchlist)头部至尾依次取出一个rq封装成cmd,然后传给low-level drive处理。在取每个rq前,会判断low-level drive是否busy(不能再处理更多的请求了),如果busy那么scsi_request_fn退出循环。这个过程见图中1如果request_queue为空,并且low-leveldirve可以继续处理请求,那么会找到当前request_queue对应的cfq_data,这个结构中维护了一些rbtree,从而可以找到下一次待处理的rq,并把这个rq添加到request_queue尾部,见图中2,然后继续执行中1的流程。
七、io完成后硬件发送中断通知设备驱动程序
这里针对single queue linux block layer描述(从linux3.13版本开始合入了multi-queue)。read操作由于等待磁盘io数据,所以当前进程阻塞睡眠在某个cpu等待队列上。当io完成后,硬件发送中断通知系统中的某个cpu(现在的系统,中断都是发送给某个cpu,而不是所有的cpu),但接收到中断的cpu可能不是read进程睡眠的cpu,如果用接收到硬件中断的cpu去唤醒其他cpu上的进程,开销比较大。在中断中,会触发软中断,由软中断去做io完成后的处理工作比如唤醒进程,所以只要在提交io请求的cpu上触发软中断,就可以唤醒本cpu上睡眠的进程。代码blk-softirq.c中通过req->cpu跟踪req之前是由哪个cpu提交的,触发软中断时会判断当前cpu与req->是否相同,如果相同就在本cpu上触发软中断,否则在req->cpu上触发软中断。软中断会调用回调函数bio->bi_end_io,即mpage_end_io,这个回调函数会释放page锁唤醒read进程,详细过程其他文章再说。
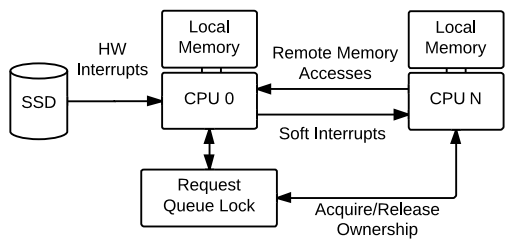
从上面这个图中顺便说一下single queue的缺点:
所有cpu共享一个request queue,对request_queue->queue_lock的竞争比较多。
大多数情况下,完成一次io需要两次中断,一个是硬件中断,一个是IPI核间中断用于触发其他cpu上的软中断。
如果提交io请求的cpu不是接收到硬件中断的cpu,还存在远端内存访问的问题。
以上几点,在大负载的情况下,会影响系统性能。

相关文章推荐
- linux下代码阅读 -- 配置vim+ctags+taglist+cscope[转]
- Linux中ipv6代码阅读(2)
- linux下通用代码阅读编辑:vim + Ctags +taglist+...
- Linux 内核代码阅读 pid.c
- Linux 下的代码阅读二
- linux下代码阅读环境的快速建立--lxr+glimpse
- 【Linux开发技术之工具使用】配置VIM下编程和代码阅读环境 - gnuhpc - 博客园
- 【Linux开发技术之工具使用】配置VIM下编程和代码阅读环境
- Linux下代码阅读 -- 配置vim+ctags+taglist+cscope[转]
- (转)【Linux开发技术之工具使用】配置VIM下编程和代码阅读环境
- Linux中ipv6代码阅读(1)
- linux下的代码阅读工具傻瓜配置教程
- Linux System Programming阅读笔记之---read(....)
- linux下代码阅读 -- 配置vim+ctags+taglist+cscope
- linux 蓝牙驱动代码阅读笔记
- Linux中ipv6代码阅读(3)
- Linux中ipv6代码阅读(4)
- Linux代码阅读之header.S(一)
- linux下android代码阅读编辑:eclim+vim
- 【Linux开发技术之工具使用】配置VIM下编程和代码阅读环境