机器学习---第七讲---聚类的基础知识
2016-10-27 00:00
274 查看
1.聚类分析概述
目前为止,我们了解了回归和分类。他们都属于监督式机器学习supervised machine learning。在监督式机器学习中,你训练一个算法,通过它从已知的变量来预测未知的变量。
另外一种主要的机器学习方式被叫做非监督式学习unsupervised learning。在非监督式学习中,我们并不尝试预测任何变量。取而代之,在数据中找到一种模式。
一个非常重要的非监督式学习技术叫做聚类。当我们尝试探索一个数据集时,并且准备去理解变量的行与列之间的联系时,我们使用聚类。例如,我们可以基于NBA球员的统计资料,来聚集他们。
这里是他们的聚类分布图:
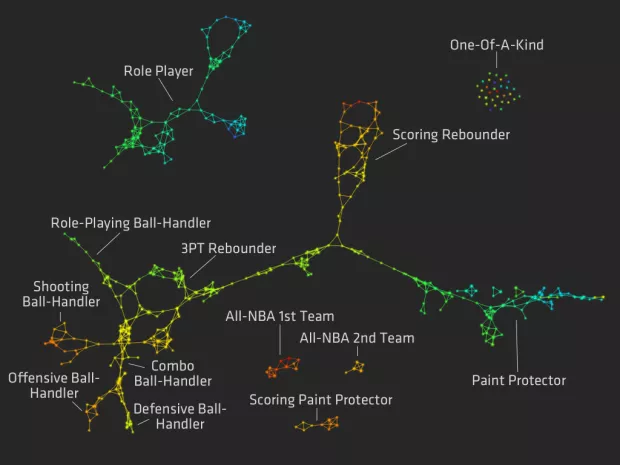
这个分类组制作出之后,你将很容易发现球员的角色,否则,你很难弄清楚。Here's是一个描述分类组怎样被创建出来的文章。
聚类算法组类似在一起的行。他们在数据中可以是一个或多个一组,并且这些组来自于聚类。当我们看这个分类组,我们可以更好的理解数据的结构。
聚类是探索未知数据的钥匙,它是机器学习中普遍用法。在这个任务中,我们将会研究US国会议员选票的聚类问题。
目前为止,我们了解了回归和分类。他们都属于监督式机器学习supervised machine learning。在监督式机器学习中,你训练一个算法,通过它从已知的变量来预测未知的变量。
另外一种主要的机器学习方式被叫做非监督式学习unsupervised learning。在非监督式学习中,我们并不尝试预测任何变量。取而代之,在数据中找到一种模式。
一个非常重要的非监督式学习技术叫做聚类。当我们尝试探索一个数据集时,并且准备去理解变量的行与列之间的联系时,我们使用聚类。例如,我们可以基于NBA球员的统计资料,来聚集他们。
这里是他们的聚类分布图:
这个分类组制作出之后,你将很容易发现球员的角色,否则,你很难弄清楚。Here's是一个描述分类组怎样被创建出来的文章。
聚类算法组类似在一起的行。他们在数据中可以是一个或多个一组,并且这些组来自于聚类。当我们看这个分类组,我们可以更好的理解数据的结构。
聚类是探索未知数据的钥匙,它是机器学习中普遍用法。在这个任务中,我们将会研究US国会议员选票的聚类问题。

相关文章推荐
- 机器学习---基础知识
- 机器学习基础知识
- 机器学习基础知识(一)
- 机器学习的基础知识
- 机器学习基础---概率论基础知识
- 看懂论文的机器学习基础知识(一)
- 机器学习(K-近邻算法)Python的基础知识
- 机器学习知识点(十九)矩阵特征值分解基础知识及Java实现
- 机器学习之由wavenet涉及到的基础知识(补充下学习ing)
- 机器学习知识点(二十二)高斯分布(正态分布)基础知识
- 机器学习基础知识
- 机器学习--基础知识复习(模式识别,成本函数)
- 【机器学习】个人基础知识梳理
- 机器学习知识体系 - 神经网络(基础)
- 机器学习基础(一):K-means聚类
- 【Numpy】python机器学习包Numpy基础知识学习
- 机器学习基础知识之矩阵
- 机器学习之基础知识
- 机器学习知识点(二十)矩阵奇异值分解基础知识及Java实现
- 一 、机器学习基础知识(转载)