用户行为日志的采集
2016-10-26 18:19
309 查看
用户的行为日志,在现今以数据说话时代的重要性已经凸显地越来越明显.笔者从事相关一线工作(主要是数据处理及模型设计,离线及实时平台)三年,分享一些工作中的一些思考,这部分的内容比较偏向业务,希望不会写的太技术。
首先,我们要先来看一下这个东东到底有啥重要的,为啥每个有点规模的公司都需要花费一定人力来搞这个东西呢?有的时候甚至只是一份日志真的能养活这么多人?
想解释这个问题,必须回到一些基本运营的问题上来?
1.公司靠客户转化来增加收入,没错吧?
2.哪个公司都有产品经理吧?怎么知道他/她设计的这产品效果明显呢?万一正好搞啥活动或者公关的好,他这产品上线了,谁扯的清呢?
3.公司运营除了增加收入外还得减少开支吧,每个月投baidu、360、各种网盟的钱有点割肉的感觉吧?我们期待啥?用最少的钱打最合算的广告!
4.那些说什么老板拿这些数据做最后的决策,部分有点扯淡,不排除现在一些老大还是拍脑袋下决策,但是有一点一定是对的,就是你得知道自己公司一段时间的数据吧,不能闷头过日子啊。
5...
以上问题都是可以在用户数据中拿到对应的内容来说明。
好了,在我们确定了这个东西的确是有价值、值得花人力去做之后,我们来聊聊怎么做?
在这里需要细分一下目前用户访问的平台,根据目前以及短期内技术发展,可以分为三种APP|PC|WAP,其中PC/WAP可以算一种,都是传统web交互方式,APP(说的是Native APP,iOS、Android etc)
PC/WEB上实现一般有三种:
1.web service记录
2.js嵌入收集
3.包嗅探器
目前第二种是最流行的收集方式。
通过使用JS收集客户端的cookie信息,浏览器等,发送到后台一组服务器,找了几个网站查看他们的收集数据,请求格式譬如:
[html] view
plain copy
唯品会:
http://mar.vip.com/p?mars_br_pos=&mars_cid=1398657717000_d430514ae3ce8aab29178c11eba5dcb1&mars_sid=b01fc069abdd38df7bd359d6429184f4&pi=0&mars_vid=BD55BF35DADC6722D8D2B29B5C4054A3&lvm_id=83619272008072580001401328910640&mars_var=-&lg=0&wh=VIP_SH&in=0&sn=&url=http://www.vip.com/&sr=1366*768&rf=&bw=1286&bh=150&sc=24&bv=mozilla/5.0 (windows nt 6.3; wow64) applewebkit/537.36 (khtml, like gecko) chrome/40.0.2214.93 safari/537.36&ce=1&vs=&title=唯品会(原Vipshop.com)特卖会:一家专门做特卖的网站_确保正品_确保低价_货到付款&tab_page_id=1423478314979_0c4c3141-f350-79ec-2e58-1b5bafda3332&vip_qe=undefined&vip_qt=undefined&vip_xe=&vip_xt=&r=0.03680062713101506
当当:
http://click.dangdang.com/page_tracker.php?m_id=&o_id=®ion_ids=&out_refer=null&refer_url=&url=http://www.dangdang.com/&to_url=&type=1&visit_count=27&is_first_pv=0&ctr_type=&perm_id=20140430171404681303078869337380126&res=1366,768||1286,1518&r=0.9703021887689829&title=当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款&trace_id=0.70&special=market=location:6;&cif=&rsv1=&rsv2=&rsv3=&rsv4=xxx
淘宝:
http://ac.mmstat.com/1.gif?uid=802662066&apply=vote&abbucket=_AB-M65_B6&com=02&acm=tt-1097039-36356.1.1003&cod=tt-1097039-36356&cache=1874351609&aldid=72SdnsDn&logtype=4&abtest=_AB-LR65-PR65&scm=1003.1.tt-1097039-36356&ip=210.13.117.180
在服务器端如Nginx,进行query的parse配置,最后将数据以log方式存储。
移动端的实现
对移动开发不熟悉,了解到的是一般通过手动埋点,触发Event来实现,如友盟的自定义事件埋点:
http://mtj.baidu.com/web/welcome/sdk
http://wdm.taobao.com/index.htm
https://talkingdata.net/index.jsp
下面我们将讨论如何将这些日志传输到我们的存储系统以便于后续处理分析,会结合离线以及实时两条线来探讨。
目前我们采取的方案是这样的:
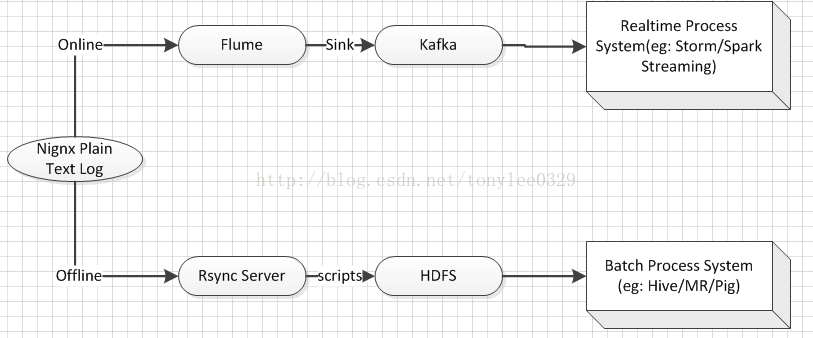
这样架构的考虑点:
1.先说离线,从日志传输和容错方面而言,rsync无疑是最好的方案,它基于日志的内容做增量传输,快速稳定而且高效
2.实时的这条路,前面的Flume和Kafka可替代的开源工具(如Scribe/RMQ)还是有的,但是考虑集成和性能,MQ还是用了Kafka,而传输则采用了Flume
3.离线和实时分开两条路
了解了其他公司的做法,有的是将日志都走实时,然后schedule transfer到HDFS,这样看起来好像是省了点事,但是细想想有诸多不便:
1.对于日志类数据量比较大的,在Flume这块一般都是使用memory channel,而不是FileChannel,这样就有可能因为应用本身或者网络而出现丢数据问题,如此设计的话,数据是无法补救的;
2.需要维护每次schedule consumer的offset,对于后面更为复杂的BI/ETL需求更为麻烦。
但是如果现有的架构要放到和RDBMS一起的整个Databus(离线和在线),觉得接入方面还是相对较难,期待看到更多的设计,也多多学习!
转自:http://blog.csdn.net/tonylee0329/article/details/43705065
首先,我们要先来看一下这个东东到底有啥重要的,为啥每个有点规模的公司都需要花费一定人力来搞这个东西呢?有的时候甚至只是一份日志真的能养活这么多人?
想解释这个问题,必须回到一些基本运营的问题上来?
1.公司靠客户转化来增加收入,没错吧?
2.哪个公司都有产品经理吧?怎么知道他/她设计的这产品效果明显呢?万一正好搞啥活动或者公关的好,他这产品上线了,谁扯的清呢?
3.公司运营除了增加收入外还得减少开支吧,每个月投baidu、360、各种网盟的钱有点割肉的感觉吧?我们期待啥?用最少的钱打最合算的广告!
4.那些说什么老板拿这些数据做最后的决策,部分有点扯淡,不排除现在一些老大还是拍脑袋下决策,但是有一点一定是对的,就是你得知道自己公司一段时间的数据吧,不能闷头过日子啊。
5...
以上问题都是可以在用户数据中拿到对应的内容来说明。
好了,在我们确定了这个东西的确是有价值、值得花人力去做之后,我们来聊聊怎么做?
在这里需要细分一下目前用户访问的平台,根据目前以及短期内技术发展,可以分为三种APP|PC|WAP,其中PC/WAP可以算一种,都是传统web交互方式,APP(说的是Native APP,iOS、Android etc)
PC/WEB上实现一般有三种:
1.web service记录
2.js嵌入收集
3.包嗅探器
| Web日志 | JavaScript标记 | 包嗅探器 | |
| 优点 | ・比较容易获取数据源 ・方便对历史数据再处理 ・可以记录搜索引擎爬虫的访问记录 ・记录文件下载状况 | ・数据收集灵活,可定制性强 ・可以记录缓存、代理服务器访问 ・对访问者行动追踪更为准确 | ・对跨域访问的监测比较方便 ・取得实时数据比较方便 |
| 缺点 | ・无法记录缓存、代理服务器访问 ・无法捕获自定义的业务信息 ・对访问者的定位过于模糊 ・对跨域访问的监测比较麻烦 | ・用户端的JS设置会影响数据收集 ・记录下载和重定向数据比较困难 ・会增加网站的JS脚本负荷 | ・初期导入费用较高 ・无法记录缓存、代理服务器访问 ・对用户数据隐私有安全隐患 |
通过使用JS收集客户端的cookie信息,浏览器等,发送到后台一组服务器,找了几个网站查看他们的收集数据,请求格式譬如:
[html] view
plain copy
唯品会:
http://mar.vip.com/p?mars_br_pos=&mars_cid=1398657717000_d430514ae3ce8aab29178c11eba5dcb1&mars_sid=b01fc069abdd38df7bd359d6429184f4&pi=0&mars_vid=BD55BF35DADC6722D8D2B29B5C4054A3&lvm_id=83619272008072580001401328910640&mars_var=-&lg=0&wh=VIP_SH&in=0&sn=&url=http://www.vip.com/&sr=1366*768&rf=&bw=1286&bh=150&sc=24&bv=mozilla/5.0 (windows nt 6.3; wow64) applewebkit/537.36 (khtml, like gecko) chrome/40.0.2214.93 safari/537.36&ce=1&vs=&title=唯品会(原Vipshop.com)特卖会:一家专门做特卖的网站_确保正品_确保低价_货到付款&tab_page_id=1423478314979_0c4c3141-f350-79ec-2e58-1b5bafda3332&vip_qe=undefined&vip_qt=undefined&vip_xe=&vip_xt=&r=0.03680062713101506
当当:
http://click.dangdang.com/page_tracker.php?m_id=&o_id=®ion_ids=&out_refer=null&refer_url=&url=http://www.dangdang.com/&to_url=&type=1&visit_count=27&is_first_pv=0&ctr_type=&perm_id=20140430171404681303078869337380126&res=1366,768||1286,1518&r=0.9703021887689829&title=当当—网上购物中心:图书、母婴、美妆、家居、数码、家电、服装、鞋包等,正品低价,货到付款&trace_id=0.70&special=market=location:6;&cif=&rsv1=&rsv2=&rsv3=&rsv4=xxx
淘宝:
http://ac.mmstat.com/1.gif?uid=802662066&apply=vote&abbucket=_AB-M65_B6&com=02&acm=tt-1097039-36356.1.1003&cod=tt-1097039-36356&cache=1874351609&aldid=72SdnsDn&logtype=4&abtest=_AB-LR65-PR65&scm=1003.1.tt-1097039-36356&ip=210.13.117.180
在服务器端如Nginx,进行query的parse配置,最后将数据以log方式存储。
移动端的实现
对移动开发不熟悉,了解到的是一般通过手动埋点,触发Event来实现,如友盟的自定义事件埋点:
MobclickAgent.onEvent(
this
, Event.Start);
可以下载具体的SDK文档看看,后续一样还是将query发到服务器,由服务器进行解析,存储
http://www.umeng.com/analytics
http://mtj.baidu.com/web/welcome/sdk
http://wdm.taobao.com/index.htm
https://talkingdata.net/index.jsp
下面我们将讨论如何将这些日志传输到我们的存储系统以便于后续处理分析,会结合离线以及实时两条线来探讨。
目前我们采取的方案是这样的:
这样架构的考虑点:
1.先说离线,从日志传输和容错方面而言,rsync无疑是最好的方案,它基于日志的内容做增量传输,快速稳定而且高效
2.实时的这条路,前面的Flume和Kafka可替代的开源工具(如Scribe/RMQ)还是有的,但是考虑集成和性能,MQ还是用了Kafka,而传输则采用了Flume
3.离线和实时分开两条路
了解了其他公司的做法,有的是将日志都走实时,然后schedule transfer到HDFS,这样看起来好像是省了点事,但是细想想有诸多不便:
1.对于日志类数据量比较大的,在Flume这块一般都是使用memory channel,而不是FileChannel,这样就有可能因为应用本身或者网络而出现丢数据问题,如此设计的话,数据是无法补救的;
2.需要维护每次schedule consumer的offset,对于后面更为复杂的BI/ETL需求更为麻烦。
但是如果现有的架构要放到和RDBMS一起的整个Databus(离线和在线),觉得接入方面还是相对较难,期待看到更多的设计,也多多学习!
转自:http://blog.csdn.net/tonylee0329/article/details/43705065

相关文章推荐
- 基于Kafka的服务端用户行为日志采集
- 用户行为日志的采集
- 日志采集与用户行为链路跟踪
- 用户行为日志的采集
- 基于Kafka的服务端用户行为日志采集
- 用户行为数据采集核心思维(APP、web数据采集/埋点)
- 采集网站用户行为的免费工具
- Spark日志分析项目Demo(4)--RDD使用,用户行为统计分析
- 免费的用户行为跟踪采集
- 【分享】互联网用户行为日志数据集
- 用户行为日志-js埋点(二) 实现细节
- 002中小规模电子商务网站用户行为日志收集方案
- 采集网站用户行为的免费工具
- 采集网站用户行为的免费工具
- 免费的用户行为跟踪采集
- 用户行为日志-js埋点(三)浏览记录和停留时间思路
- Linux 用户行为日志记录
- 用户实时行为数据采集
- 免费的用户行为跟踪采集
- 免费的用户行为跟踪采集