python 小脚本 通过关键词在百度网盘 搜索 高清电影并生成html浏览
2016-10-22 22:21
645 查看
比较屌丝,看电影经常用百度云网盘,所以写个脚本方便查看。
保持脚本为
把符合的电影最后生成Html文件然后浏览(文件位置自己再修改下或者改成动态的吧)。
设置alias:
脚本地址:https://github.com/kute/purepythontest/blob/master/test/get_film_from_baidu.py
脚本:
效果:
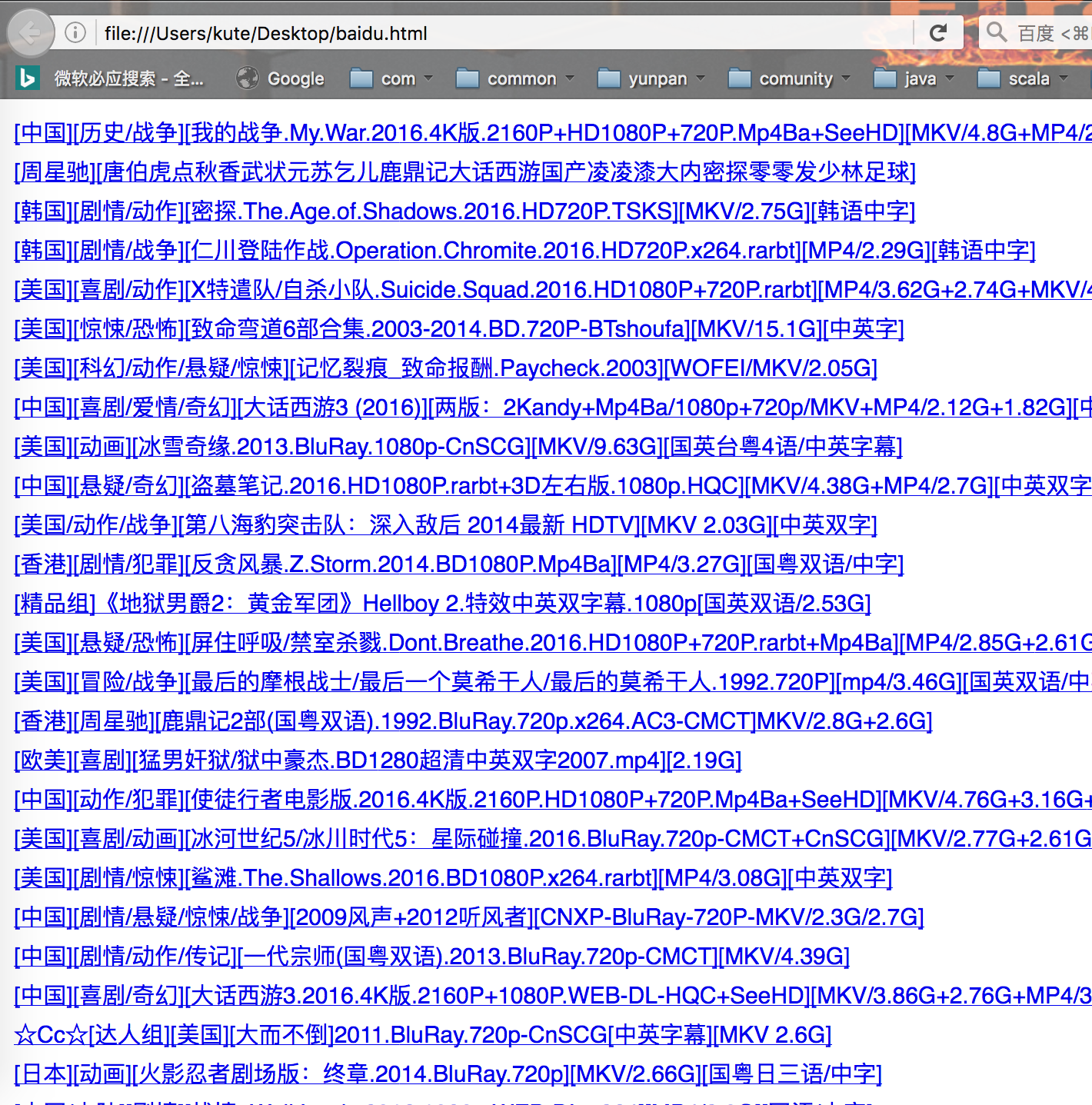
保持脚本为
baidu.py,然后
python baidu.py -h查看帮助。
-p:指定第几页;
-k:关键词
把符合的电影最后生成Html文件然后浏览(文件位置自己再修改下或者改成动态的吧)。
设置alias:
alias baidu="python baidu.py",然后 在命令行中 执行
baidu -p 1 -k 2016
脚本地址:https://github.com/kute/purepythontest/blob/master/test/get_film_from_baidu.py
脚本:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ = 'kute'
# __mtime__ = '16/10/22 17:49'
"""
关键词 过滤 查看 百度网盘的高清电影
太懒了我
"""
import argparse
import requests
from bs4 import BeautifulSoup
import dominate
from dominate.tags import meta, div, table, tr, td, a
import webbrowser
class GetFilm(object):
def __init__(self, page=1, keyword="2016"):
self.page = page or 1
self.keyword = keyword
self.baiduurl = "http://www.baiduyun.me/forum.php?mod=forumdisplay&fid=99&page={}"
self.baidufile = "/Users/kute/Desktop/baidu.html"
def request(self):
print("========1. Curent page is {} and the keyword is {}.========".format(self.page, self.keyword))
res = requests.get(self.baiduurl.format(self.page))
parse = BeautifulSoup(res.text, "html.parser")
tbodylist = parse.select("tbody[id^='normalthread']")
filmlist = []
for tbody in tbodylist:
parse2 = BeautifulSoup(str(tbody.tr.th), "html.parser")
a = parse2.select_one("a[class='s xst']")
if self.keyword:
if a.string.find(self.keyword) != -1:
filmlist.append((a["href"], a.string))
else:
filmlist.append((a["href"], a.string))
print("========2. Finish scrapy the page and begin generate the html:{}.========".format(self.baidufile))
self.generate_html(filmlist)
def generate_html(self, filmlist):
doc = dominate.document(title='Dominate your HTML')
with doc.head:
meta({"http-equiv": "Content-Type", "content": "text/html; charset=UTF-8"})
with doc:
with div():
with table():
for url, text in filmlist:
with tr():
with td():
a(text, href=url, target="_blank")
with open(self.baidufile, "w") as f:
f.write(doc.render())
print("========3. All finished, have a look please.========")
webbrowser.open("file://{}".format(self.baidufile), new=0, autoraise=True)
def main():
parse = argparse.ArgumentParser(description="Generate films file")
parse.add_argument("-k", "--keyword", help="the film year you want to see, default 2016")
parse.add_argument("-p", "--page", help="next page loop, default 1")
args = parse.parse_args()
g = GetFilm(args.page, args.keyword)
g.request()
if __name__ == '__main__':
main()效果:

相关文章推荐
- 用python通过apache log 获取百度搜索来源关键词
- selenium2+python3生成浏览百度de 测试报告
- 解析百度搜索结果页面的python脚本(Linux/Win都可以运行)
- python脚本生成html
- Ubuntu + coreseek + python + mysql (三、通过前端html进行搜索,用python处理数据)
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
- 怎么在百度里通过关键词搜索到自己的网站
- python脚本 通过rsa private key 生成 publickey
- python 模拟百度搜索关键词
- python request库 百度360关键词搜索提交
- 通过微软的HTML Help Workshop 利用.html文件 生成简单的chm帮助类的文件
- 通过百度 vs 奇虎,来谈博客搜索
- Python将Delphi代码生成语法高亮的HTML格式
- 如何通过动态生成Html灵活实现DataGrid分类统计的界面
- 方案改进:直接通过User Control生成HTML
- 动态通过js脚本构造html页面
- 通过ajax调用php生成json转给js,生成html
- 方案改进:直接通过User Control生成HTML——转自 博客园 老赵
- 扩展老赵的 直接通过User Control生成HTML 分页功能
- 给初学者:VB如何操作WEB页的浏览提交———一:在百度中自动搜索