Scrapy爬虫框架抓取中文结果为Unicode编码,如何转换UTF-8编码的解决办法
2016-10-21 18:50
603 查看
1.在pipelines.py中设置如下:(t.json为你要保存的文件名)
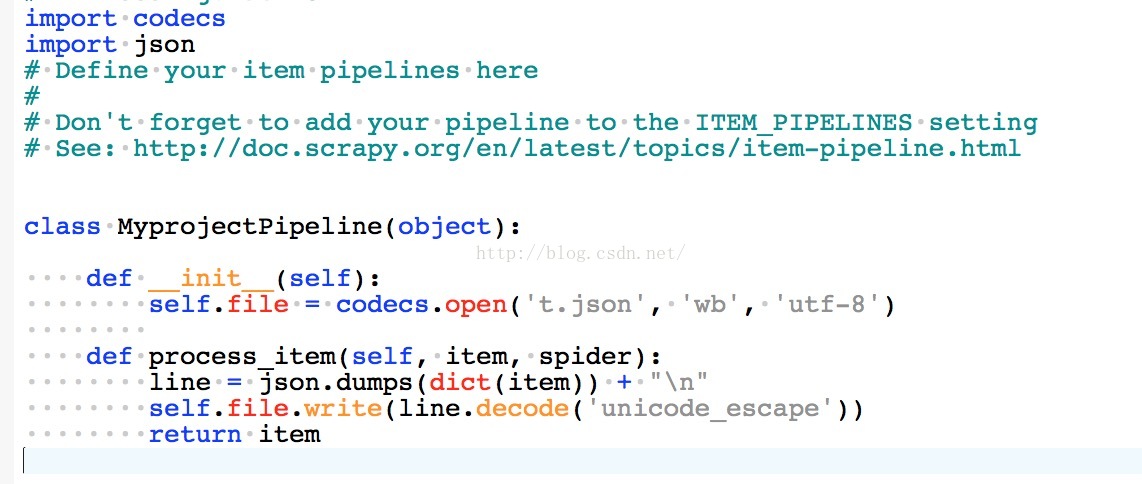
2.在settings.py中设置如下:
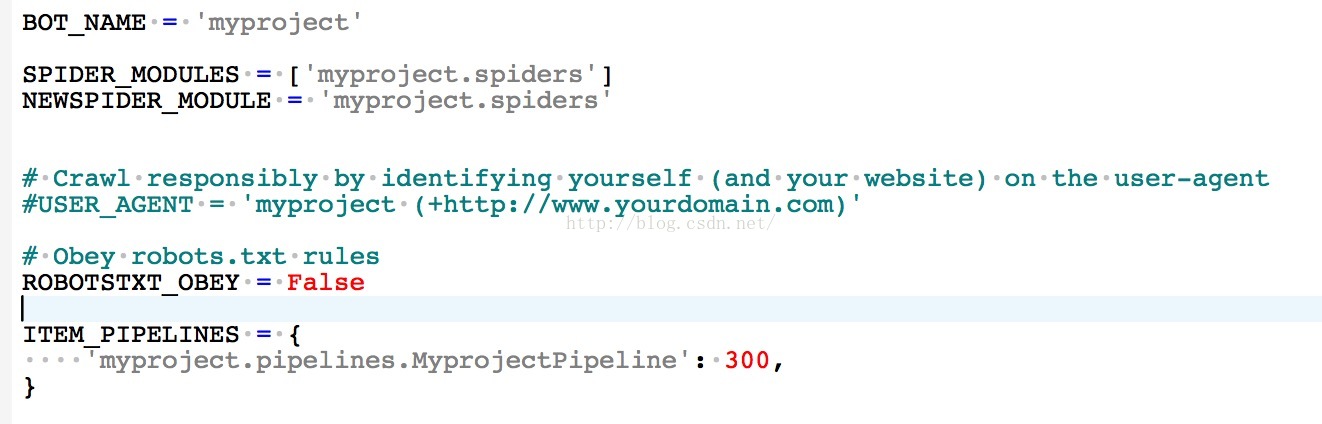
3.在终端运行爬虫程序 scrapy crawl XX(爬虫名)

相关文章推荐
- scrapy抓取到中文,保存到json文件为unicode,如何解决.
- 如何解决GBK的编码的文件中的中文转换成为UTF-8编码的文件而且不乱码
- Scrapy爬虫,Python2将Unicode编码装换成UTF-8编码解决方法之一
- [Python爬虫] 中文编码问题:raw_input输入、文件读取、变量比较等str、unicode、utf-8转换问题
- 解决Scrapy抓取中文结果保存为文件时的编码问题
- scrapy抓取的中文结果乱码解决办法
- scrapy抓取的中文结果乱码解决办法
- Mysql数据库编码为UTF-8,但查询结果依旧乱码、为空解决办法
- utf-8编码引起js输出中文乱码的解决办法
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
- utf-8编码引起js输出中文乱码的解决办法(实用)
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
- 因utf-8编码引起js输出中文乱码的解决办法
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
- 因utf-8编码引起js输出中文乱码的解决办法
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?[转]
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的