Jmeter之计数器与分布式融合处理
2016-10-18 17:33
127 查看
场景:测试订单记录存储性能;
描述:使用分布式来测试高并发情况下存储订单记录的性能;
要求:订单编号不能重复;
脚本方案(初稿):
使用计数器(counter)来生成订单号,其他可用变量来处理;
调试结果与问题:
单机情况下:Jmeter能生成不重复的订单号,能完成压测任务;
分布式情况:报订单号重复,原因是Jmeter的master机只是将jmx发给slave机器上执行,这样一来就会导致所有slave机共用同一个计数器,就会出现重复了。
思考及切入点:1、订单编号有命名规则,如A10100001;
2、master机不会发送csv文件给slave机;
脚本方案(完善)
1、建一个计数器,让Jmeter生成增长的数字序列;
如7315;
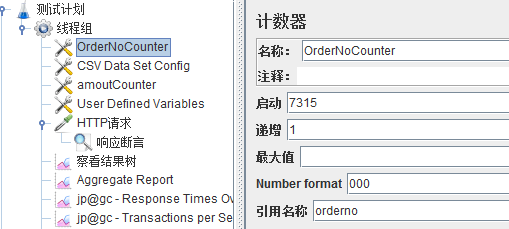
2、建一个csv配置,csv文件里面存储编号标识;如A,
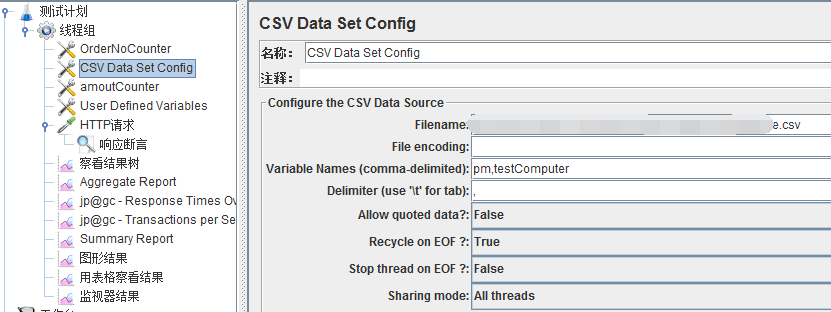
3、为每一个slave机器配置一个名字、路径完全一样的csv文件,
但是文件内容不同;
如csv文件1存ye;csv文件2存yf;
4、在发送请求中,引用csv配置的变量名和计数器;
如
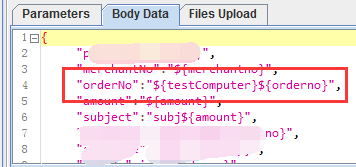
5、这样就不会报订单号重复了,因为订单号已经是有标识+序列号来构成了。
描述:使用分布式来测试高并发情况下存储订单记录的性能;
要求:订单编号不能重复;
脚本方案(初稿):
使用计数器(counter)来生成订单号,其他可用变量来处理;
调试结果与问题:
单机情况下:Jmeter能生成不重复的订单号,能完成压测任务;
分布式情况:报订单号重复,原因是Jmeter的master机只是将jmx发给slave机器上执行,这样一来就会导致所有slave机共用同一个计数器,就会出现重复了。
思考及切入点:1、订单编号有命名规则,如A10100001;
2、master机不会发送csv文件给slave机;
脚本方案(完善)
1、建一个计数器,让Jmeter生成增长的数字序列;
如7315;
2、建一个csv配置,csv文件里面存储编号标识;如A,
3、为每一个slave机器配置一个名字、路径完全一样的csv文件,
但是文件内容不同;
如csv文件1存ye;csv文件2存yf;
4、在发送请求中,引用csv配置的变量名和计数器;
如
5、这样就不会报订单号重复了,因为订单号已经是有标识+序列号来构成了。

相关文章推荐
- jmeter 分布式压力机(多网卡)----处理Connection refused
- ADO.NET如何实现分布式事务处理
- [原创]Java技巧:分布式Jtables处理[1]
- Sybase ASE的XA Transactions(分布式事务处理)
- 分布式跨数据库的事务处理解决方案jta
- Hadoop-- 开源海量文件分布式计算处理方案
- SQL Server 分布式事务处理(MS DTC)初探
- 消息与.Net Remoting的分布式处理架构
- 分布式事务处理
- 未处理的异常:进程性能计数器已禁用
- [原创]Java技巧:分布式Jtables处理[2]
- 基于消息与.Net Remoting的分布式处理架构
- >NET的分布式处理
- Sybase ASE的XA Transactions(分布式事务处理)
- 基于消息与.Net Remoting的分布式处理架构
- 分布式事务处理(zz)
- 分布式异构数据库的事务处理
- [导入]分布式事务处理设计
- Hadoop--海量文件的分布式计算处理方案
- 基于消息与.Net Remoting的分布式处理架构