Linux环境搭建Hadoop伪分布模式
2016-10-16 21:42
344 查看
Hadoop有三种分布模式:单机模式、伪分布、全分布模式,相比于其他两种,伪分布是最适合初学者开发学习使用的,可以了解Hadoop的运行原理,是最好的选择。接下来,就开始部署环境。
首先要安装好Linux环境,可以是真机,也可以是虚拟机,我的环境是VMWare下安装的CentOS 6.3的虚拟机,如果你还没有安装好Linux环境,可以参考我的另一篇文章: window7环境下VMWare自定义安装Linux虚拟机完全教程,希望可以帮到你。
等你安装好了Linux环境,我们就可以真正开始部署hadoop了。
需要准备好Linux版本的jdk和hadoop的压缩包,可以分别去官网下载,我也提供我的资源给大家参考:链接:http://pan.baidu.com/s/1mhKixFq 密码:6lqt;
1.添加用户和组,并上传文件
用管理员root登录Linux,创建hadoop用户组:groupadd hadoop,
创建用户:useradd hadoop -g hadoop ,
使用传输软件将到Linux系统的任意目录下,如/root/sethadoop;
使用命令:su hadoop切换用户,查看是否创建成功,出现[root@localhost ~]表示创建成功;
然后exit退出到root用户。
(注:在学习安装Hadoop之前,最好学习和熟悉一下Linux的常用命令)。
2.Host的配置
vim /etc/hosts 进入配置文件,添加linux主机的ip地址和主机名;需要查看你自己的主机名,ifconfig;

vim /etc/sysconfig/network,设置主机名,以后所有的主机名都必须统一;
source /etc/sysconfig/network ,重新加载配置文件后生效;
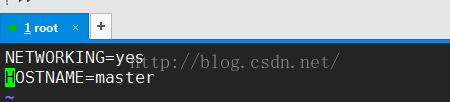
logout 登出后重新登录,发现主机名变为[root@master ~]#
3.SSH和无密码登录
安装SSH客户端:yum -y install openssh-client;
输入ssh localhost ,出现提示信息,输入yes

切换到hadoop用户,su hadoop;
生成无密码的‘公私钥’:
ssh-keygen -t dsa -P '' -f ~/ssh/id_dsa
cat ~/.ssh/id_dsa.pub>>~/.ssh/authorized_keys
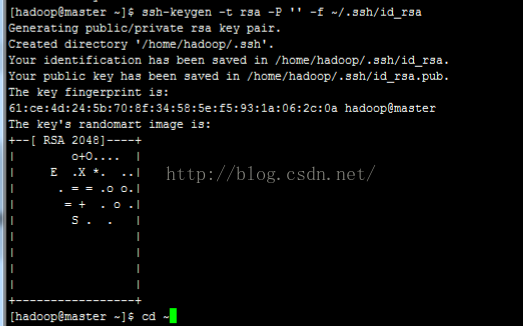
修改权限:chmod 600 ~/.ssh/authorized_keys,chmod 700 .ssh/
测试一下,ssh master,-》yes,然后退出hadoop登录,exit
4.JDK的安装
进入到jdk安装包存放的目录下,我的是/root/set,
创建安装Java的目录,mkdir /usr/java
解压到/usr/java:tar -zxvf jdk-7u9-linux-i586.tar.gz -C /usr/java
为Java安装目录建一个软连接,方便使用:ln -s jdk1.7.0_09/ jdk
(以上操作都视你的jdk版本和存储位置而定,切忌照搬)
修改环境变量,vim /etc/profile ,在文件末尾添加如下信息,也可再添加
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar;
有过window中jdk安装经验的童鞋会比较熟悉的。
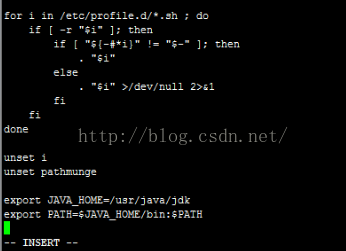
退出保存文件,重新加载配置文件,source /etc/profile.
验证Java是否安装成功:java -version,这个有Java开发经验的都知道吧。。。
5.hadoop的安装
使用root用户登录,进入你的hadoop压缩包的目录,
解压:tar -zxvf hadoop-1.0.4.tar.gz -C /opt/,解压目录/usr/也行,根据自己选择;
进入/opt目录下,更改一下文件夹的名字,方便使用,mv hadoop-1.0.4/ hadoop/;
修改用户组和权限:chown -R hadoop:hadoop hadoop/
登录hadoop用户,su hadoop;
配置 vim conf/hadoop-env.sh,在末尾添加:

第二个变量可以不是256M,根据你的内存大小而定,也可以是512M或更大;
配置 vim conf/core-site.xml 在<configuration>中添加:
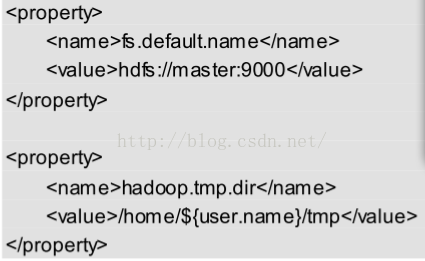
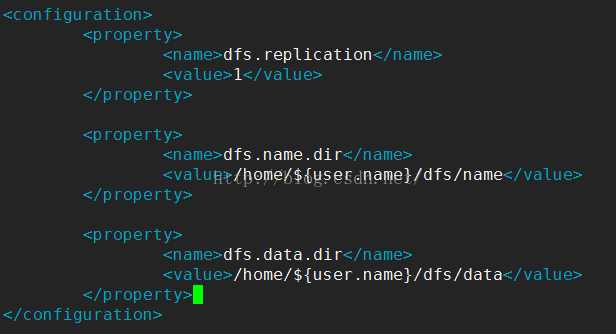
配置vim conf/hdfs-site.xml,如下,由于是伪分布式,所以replication配1就行
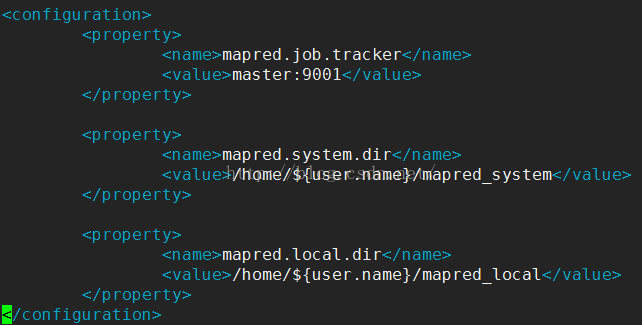
配置 conf/mapred-site.xml:主机名要一致;
配置辅助接点名称,conf/masters,就添加一个master就行
配置子节点,conf/slave 也是添加一个master就行
经过以上步骤,hadoop的配置文件就全部配置好了,不要忘记:wq退出保存哦。
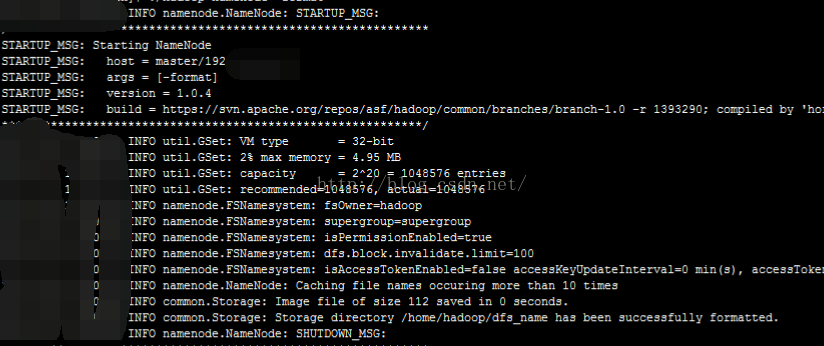
格式化分布式文件系统:进入hadoop的bin目录,
执行 ./hadoop namenode -format,完成后是这样的:
启动hadoop集群:./start-all.sh,
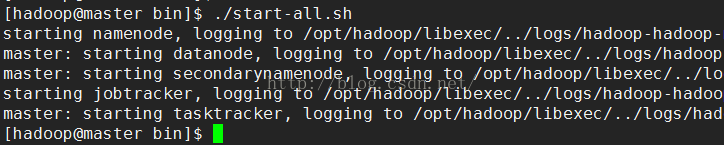
检查hadoop结点是否全部启动成功:共6个结点,一个都不能少,
如果哪个结点没有出现,说明其出错了,请进入logs目录下的日志文件查看相应的日志文件,并修改,
具体方法请查看其它网络资源;
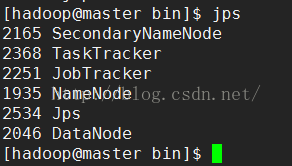
查看hadoop集群的状态信息:
在浏览器地址栏输入:http://192.168.64.128:50070/ (ip是你自己服务器的ip)
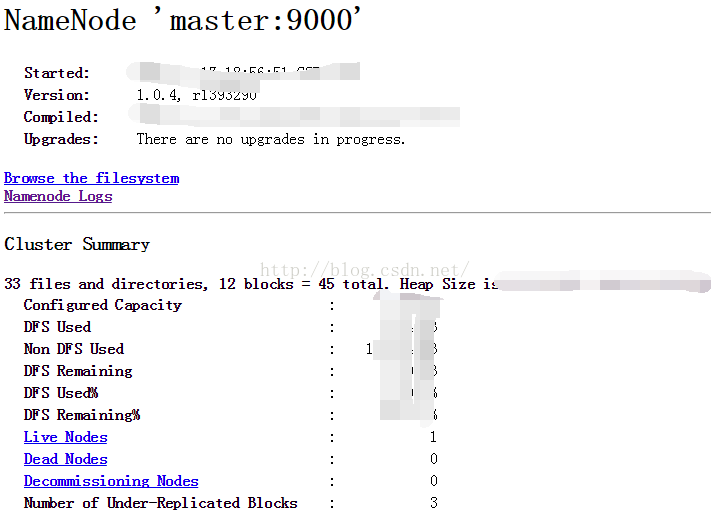
出现上图信息,说明你的hadoop伪分布模式就配置成功了!
(注:如果运行jps没有问题,而上面的页面加载不出来的话,请试着关闭防火墙:service iptables stop)
首先要安装好Linux环境,可以是真机,也可以是虚拟机,我的环境是VMWare下安装的CentOS 6.3的虚拟机,如果你还没有安装好Linux环境,可以参考我的另一篇文章: window7环境下VMWare自定义安装Linux虚拟机完全教程,希望可以帮到你。
等你安装好了Linux环境,我们就可以真正开始部署hadoop了。
需要准备好Linux版本的jdk和hadoop的压缩包,可以分别去官网下载,我也提供我的资源给大家参考:链接:http://pan.baidu.com/s/1mhKixFq 密码:6lqt;
1.添加用户和组,并上传文件
用管理员root登录Linux,创建hadoop用户组:groupadd hadoop,
创建用户:useradd hadoop -g hadoop ,
使用传输软件将到Linux系统的任意目录下,如/root/sethadoop;
使用命令:su hadoop切换用户,查看是否创建成功,出现[root@localhost ~]表示创建成功;
然后exit退出到root用户。
(注:在学习安装Hadoop之前,最好学习和熟悉一下Linux的常用命令)。
2.Host的配置
vim /etc/hosts 进入配置文件,添加linux主机的ip地址和主机名;需要查看你自己的主机名,ifconfig;
vim /etc/sysconfig/network,设置主机名,以后所有的主机名都必须统一;
source /etc/sysconfig/network ,重新加载配置文件后生效;
logout 登出后重新登录,发现主机名变为[root@master ~]#
3.SSH和无密码登录
安装SSH客户端:yum -y install openssh-client;
输入ssh localhost ,出现提示信息,输入yes
切换到hadoop用户,su hadoop;
生成无密码的‘公私钥’:
ssh-keygen -t dsa -P '' -f ~/ssh/id_dsa
cat ~/.ssh/id_dsa.pub>>~/.ssh/authorized_keys
修改权限:chmod 600 ~/.ssh/authorized_keys,chmod 700 .ssh/
测试一下,ssh master,-》yes,然后退出hadoop登录,exit
4.JDK的安装
进入到jdk安装包存放的目录下,我的是/root/set,
创建安装Java的目录,mkdir /usr/java
解压到/usr/java:tar -zxvf jdk-7u9-linux-i586.tar.gz -C /usr/java
为Java安装目录建一个软连接,方便使用:ln -s jdk1.7.0_09/ jdk
(以上操作都视你的jdk版本和存储位置而定,切忌照搬)
修改环境变量,vim /etc/profile ,在文件末尾添加如下信息,也可再添加
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar;
有过window中jdk安装经验的童鞋会比较熟悉的。
退出保存文件,重新加载配置文件,source /etc/profile.
验证Java是否安装成功:java -version,这个有Java开发经验的都知道吧。。。
5.hadoop的安装
使用root用户登录,进入你的hadoop压缩包的目录,
解压:tar -zxvf hadoop-1.0.4.tar.gz -C /opt/,解压目录/usr/也行,根据自己选择;
进入/opt目录下,更改一下文件夹的名字,方便使用,mv hadoop-1.0.4/ hadoop/;
修改用户组和权限:chown -R hadoop:hadoop hadoop/
登录hadoop用户,su hadoop;
配置 vim conf/hadoop-env.sh,在末尾添加:
第二个变量可以不是256M,根据你的内存大小而定,也可以是512M或更大;
配置 vim conf/core-site.xml 在<configuration>中添加:
配置vim conf/hdfs-site.xml,如下,由于是伪分布式,所以replication配1就行
配置 conf/mapred-site.xml:主机名要一致;
配置辅助接点名称,conf/masters,就添加一个master就行
配置子节点,conf/slave 也是添加一个master就行
经过以上步骤,hadoop的配置文件就全部配置好了,不要忘记:wq退出保存哦。
格式化分布式文件系统:进入hadoop的bin目录,
执行 ./hadoop namenode -format,完成后是这样的:
启动hadoop集群:./start-all.sh,
检查hadoop结点是否全部启动成功:共6个结点,一个都不能少,
如果哪个结点没有出现,说明其出错了,请进入logs目录下的日志文件查看相应的日志文件,并修改,
具体方法请查看其它网络资源;
查看hadoop集群的状态信息:
在浏览器地址栏输入:http://192.168.64.128:50070/ (ip是你自己服务器的ip)
出现上图信息,说明你的hadoop伪分布模式就配置成功了!
(注:如果运行jps没有问题,而上面的页面加载不出来的话,请试着关闭防火墙:service iptables stop)

相关文章推荐
- hadoop在linux上的初实验:环境搭建和伪分布模式搭建
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) - 狂奔的蜗牛 - 博客频道 - CSDN.NET http://blog.csdn.net/hitwengqi/article/detai
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- 【hadoop 2.6】hadoop2.6伪分布模式环境的搭建测试使用
- ubuntu12.04下hadoop单机模式和伪分布模式环境搭建
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu下hadoop环境的搭建(伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Linux环境Hadoop完全分布模式安装详解
- Virtualbox安装Ubuntu13.04并搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
- Linux环境Hadoop伪分布模式安装详解
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)