python爬虫---post抓取查询数据简单说明
2016-10-13 22:23
741 查看
#表示删不去这一行,这个代码框框啊 啊啊啊啊啊
一、做python爬虫,在爬取数据前,一般需要对网页进行简单分析。这里推荐用火狐的HttpFox,简单实用。
如下图,巨潮信息网的,通过查询显示想要的数据,然后抓取下来。
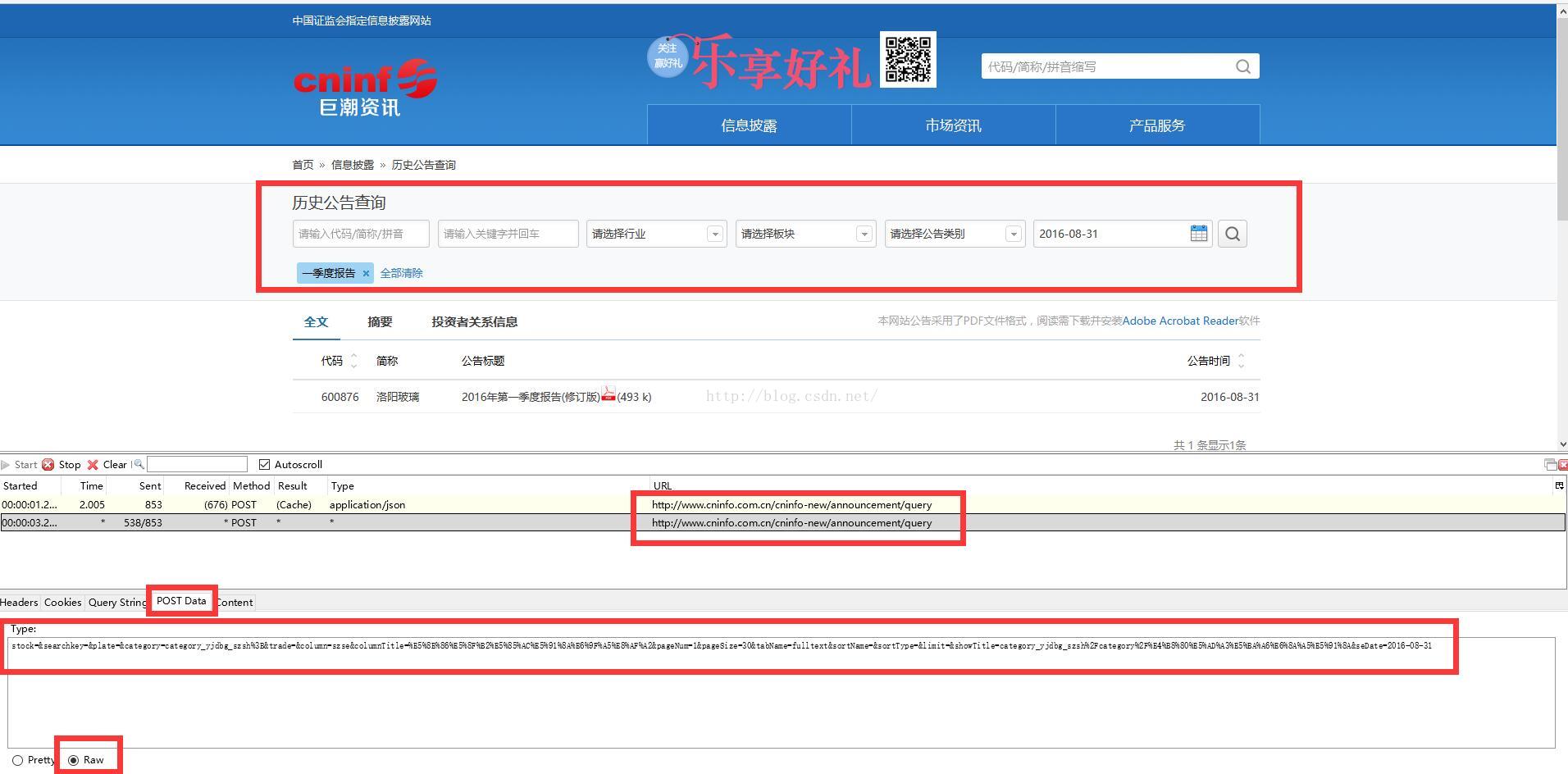
二、爬取查询数据,查询类型的,说明是要post相关数据过去才能get到想要的数据。
通过HttpFox分析,要得到相关的数据,post过去的数据相当复杂。从HttpFox的POST Data 项看到下面这一大串信息:
stock=&searchkey=&plate=sz%3Bszmb%3Bszzx%3Bszcy%3Bshmb%3B&category=category_sjdbg_szsh%3Bcategory_ndbg_szsh
%3Bcategory_bndbg_szsh%3Bcategory_yjdbg_szsh%3B&trade=&column=szse&columnTitle=%E5%8E%86%E5%8F%B2%E5%85
%AC%E5%91%8A%E6%9F%A5%E8%AF%A2&pageNum=1&pageSize=30&tabName=fulltext&sortName=&sortType=&limit=&showTitle
category_sjdbg_szsh%2Fcategory%2F%E4%B8%89%E5%AD%A3%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_ndbg_szsh
%2Fcategory%2F%E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_bndbg_szsh%2Fcategory%2F%E5%8D%8A%
E5%B9%B4%E5%BA%A6%E6%8A%A5%E5%91%8A%3Bcategory_yjdbg_szsh%2Fcategory%2F%E4%B8%80%E5%AD%A3%E5
%BA%A6%E6%8A%A5%E5%91%8A%3Bsz%2Fplate%2F%E6%B7%B1%E5%B8%82%E5%85%AC%E5%8F%B8%3Bszmb%2Fplate
%2F%E6%B7%B1%E5%B8%82%E4%B8%BB%E6%9D%BF%3Bszzx%2Fplate%2F%E4%B8%AD%E5%B0%8F%E6%9D%BF%3Bszcy
%2Fplate%2F%E5%88%9B%E4%B8%9A%E6%9D%BF%3Bshmb%2Fplate%2F%E6%B2%AA%E5%B8%82%E4%B8%BB%E6%9D%B
F&seDate=2016-10-13
想要重点抓取一季度、半年、三季度、年度的年报。看类别选择:
category=category_sjdbg_szsh%3Bcategory_ndbg_szsh%3Bcategory_bndbg_szsh
%3Bcategory_yjdbg_szsh%3B
这么复杂的post数据,根本不知道怎么构建自己的post数据项。特别是某个某个post变量是取多个值时。注意到:%3B 是URL编码值代表分号“;”。这样一个变量多个值的问题解决。
#-*- coding: utf8 -*-
import urllib2
import urllib
import re
import time,datetime
import os
import shutil
def getstock(page,strdate):
values = {
'stock':'',
'searchkey':'',
'plate':'sz;szmb;szzx;szcy;shmb',
#%category_bndbg_szsh半年报告;category_sjdbg_szsh三季度;category_ndbg_szsh年度;category_yjdbg_szsh一季度
'category':'category_bndbg_szsh;category_sjdbg_szsh;category_ndbg_szsh;category_yjdbg_szsh',
'trade':'',
'column':'szse',
'columnTitle':'%E5%8E%86%E5%8F%B2%E5%85%AC%E5%91%8A%E6%9F%A5%E8%AF%A2',
'pageNum':page,
'pageSize':'50',
'tabName':'fulltext',
'sortName':'',
'sortType':'',
'limit':'',
'seDate':strdate}
data = urllib.urlencode(values)
url = "http://www.cninfo.com.cn/cninfo-new/announcement/query"
request = urllib2.Request(url,data)
datime = datetime.datetime.now()
response = urllib2.urlopen(request,timeout=4)
re_data = response.read()
re_data = re_data.decode('utf8')
dict_data = eval(re_data.replace('null','None').replace('true','True').replace('false','False'))
print dict_data #转成dict数据,输出看看
return dict_data
try:
date2 = time.strftime('%Y-%m-%d', time.localtime())
page = 1
ret = getstock(str(page),str(date2))
except Exception as error:
print errorgood luck!

相关文章推荐
- Python爬虫简单实战:抓取小猪短租西安市前五页民房数据
- Python数据抓取(2) —简单网络爬虫的撰写
- Python爬虫(二)——urllib库,Post与Get数据传送区别,设置Headers,urlopen方法,简单爬虫
- python 抓取腾讯微博数据并做简单的分析 .
- Python: http查询(GET,POST)简单代码
- 简单的python爬虫抓取图片实例
- 简单的抓取淘宝图片的Python爬虫
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- python requests 自动管理 cookie 。 get后进行post发送数据---》最简单的刷票
- Python实现抓取页面上链接的简单爬虫分享
- Python实现抓取页面上链接的简单爬虫分享
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- python采用requests库模拟登录和抓取数据的简单示例
- Python3.4 简单抓取爬虫
- python简单爬虫,抓取邮箱
- python&php数据抓取、爬虫分析与中介,有网址案例
- 使用Python编写简单网络爬虫抓取视频下载资源
- 使用Python编写简单网络爬虫抓取视频下载资源
- 一个简单的使用python抓取网页中的水文数据的程序
- 07-爬虫的多线程调度 | 01.数据抓取 | Python